Snowpipe Streaming: High-Performance Architecture¶
The high-performance architecture for Snowpipe Streaming is engineered for modern, data-intensive organizations requiring near real-time insights. This next-generation architecture significantly advances throughput, efficiency, and flexibility for real-time ingestion into Snowflake.
For information about the classic architecture, see Snowpipe Streaming - Classic Architecture. For differences between the classic SDK and the high-performance SDK, see Comparison between classic SDK and the high-performance SDK.
Software requirements¶
Java
Requires Java 11 or later.
SDK maven repository: snowpipe-streaming Java SDK
API reference: Java SDK reference
Python
Requires Python version 3.9 or later.
SDK PyPI repository: snowpipe-streaming Python SDK
API reference: Python SDK reference
Key features¶
Throughput and latency:
High throughput: Designed to support ingest speeds of up to 10 GB/s per table.
Near-real-time insights: Achieves end-to-end ingest to query latencies within 5 to 10 seconds.
Billing:
Simplified, transparent, throughput-based billing. For more information, see Snowpipe Streaming High-Performance Architecture: Understanding your costs.
Flexible ingestion:
Java SDK and Python SDK: Utilize the new
snowpipe-streamingSDK, with a Rust-based client core for improved client-side performance and lower resource usage.REST API: Provides a direct ingestion path, simplifying integration for lightweight workloads, IoT device data, and edge deployments.
Note
We recommend that you begin with the Snowpipe Streaming SDK over the REST API to benefit from the improved performance and getting-started experience.
Optimized data handling:
In-flight transformations: Supports data cleansing and reshaping during ingestion using COPY command syntax within the PIPE object.
Enhanced channel visibility: Improved insight into ingestion status primarily through the channel history view in Snowsight and a new
GET_CHANNEL_STATUSAPI.
This architecture is recommended for:
Consistent ingestion of high-volume streaming workloads.
Powering real-time analytics and dashboards for time-sensitive decision-making.
Efficient integration of data from IoT devices and edge deployments.
Organizations seeking transparent, predictable, and throughput-based pricing for streaming ingestion.
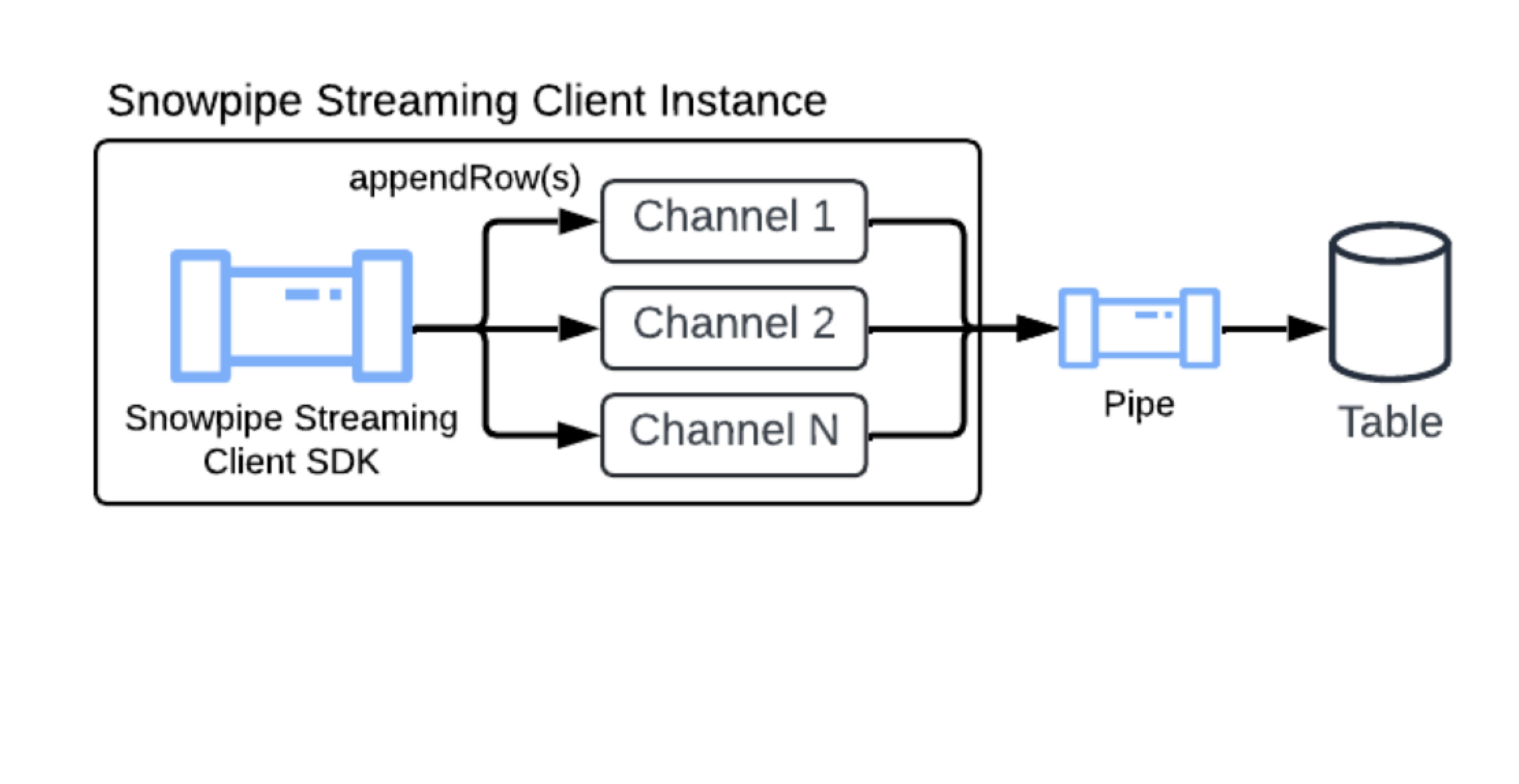
New concepts: The PIPE object¶
While inheriting core concepts like channels and offset tokens from Snowpipe Streaming Classic, this architecture introduces the PIPE object as a central component.
The PIPE object is a named Snowflake object that acts as the entry point and definition layer for all ingested streaming data. It provides the following:
Data processing definition: Defines how streaming data is processed before being committed to the target table, including server-side buffering for transformations or schema mapping.
Enabling transformations: Allows for in-flight data manipulation (e.g., filtering, column reordering, simple expressions) by incorporating COPY command transformation syntax.
Table features support: Handles ingestion into tables with defined clustering keys, DEFAULT value columns, and AUTOINCREMENT (or IDENTITY) columns.
Schema management: Helps define the expected schema of incoming streaming data and its mapping to target table columns, enabling server-side schema validation.
Pre-clustering data during ingestion¶
Snowpipe Streaming can cluster in-flight data during ingestion, which improves query performance on your target tables. This feature sorts your data directly during ingestion before it’s committed. Sorting your data this way optimizes organization for faster queries.
To leverage pre-clustering, your target table must have clustering keys defined. You can then enable this feature by setting the parameter CLUSTER_AT_INGEST_TIME to TRUE in your COPY INTO statement when creating or replacing your Snowpipe Streaming pipe.
For more information, see CLUSTER_AT_INGEST_TIME. This feature is only available on the high-performance architecture.
Important
When using the pre-clustering feature, ensure that you do not disable the auto-clustering feature on the destination table. Disabling auto-clustering can lead to degraded query performance over time.
Differences from Snowpipe Streaming Classic¶
For users familiar with the classic architecture, the high-performance architecture introduces the following changes:
New SDK and APIs: Requires the new
snowpipe-streamingSDK (Java SDK and REST API), necessitating client code updates for migration.PIPE object requirement: All data ingestion, configuration (for example, transformations), and schema definitions are managed through the server-side PIPE object, a shift from Classic’s more client-driven configuration.
Channel association: Client applications open channels against a specific PIPE object, not directly against a target table.
Schema validation: Moves from primarily client-side (Classic SDK) to server-side enforcement by Snowflake, based on the PIPE object.
Migration requirements: Requires modifying client application code for the new SDK and defining PIPE objects in Snowflake.