Snowflake DCM Projects — Extended capabilities (early access)¶
Introduction¶
This document describes a rolling set of new DCM Project capabilities that are available in private preview to selected customers. These features extend the core DCM Projects functionality with additional object types and deployment capabilities.
Over time, this document will be extended with new capabilities as they become available for early testing. Once a capability is sufficiently tested and stable, it will progress into the Public Preview release of DCM Projects and be removed from this document.
Early access for the following DCM capabilities is currently available in private preview:
DEFINE FUNCTION (Python and Java)→ now in Public PreviewDEFINE PROCEDURE (Python and Java)→ now in Public Preview- DEFINE PIPE
- DEFINE SEMANTIC VIEW
- DEFINE SHARE
ATTACH TAG→ now in Public PreviewDEFINE MASKING POLICY→ now in Public Preview- DEFINE ROW ACCESS POLICY
DEFINE NETWORK RULE→ now in Public PreviewDEFINE NETWORK POLICY→ now in Public Preview- DEFINE STREAMLIT
- DEFINE DBT PROJECT
PLAN DELTA→ now in Public Preview- CLI enhancements
- Pre-hooks for Integrations
Inherited grants→ now in Public PreviewContainer-level MANAGE GRANTS→ now in Public Preview
Note
For the main DCM documentation of all publicly available functionality see: https://docs.snowflake.com/en/user-guide/dcm-projects/dcm-projects-overview
DEFINE PIPE¶
You can define Snowflake pipes directly in DCM Projects. DCM manages the pipe lifecycle (CREATE, ALTER, DROP) across environments using Jinja templating, so you don’t have to maintain separate pipe definitions per environment.
All pipe properties supported by CREATE PIPE are available in DEFINE PIPE.
Functional limitations¶
- Only the pipe
COMMENTcan be changed after creation. The COPY INTO body and all other pipe properties are immutable. AUTO_INGEST = TRUErequires an S3/Azure/GCS event notification to be configured outside of DCM. DCM creates the pipe but doesn’t configure the cloud-side notification.
DEFINE SEMANTIC VIEW¶
You can define Semantic Views directly in DCM Projects. Every deployment of a definition change reconciles the full semantic view definition: tables, relationships, facts, dimensions, metrics, AI instructions, and verified queries.
Functional limitations¶
- All defined constraints and relationships must be named.
- All CREATE OR ALTER SEMANTIC VIEW usage notes apply, including that tags on the semantic view or its members can’t be added or changed through the statement. Any existing tags are preserved.
DEFINE SHARE¶
You can define shares in DCM to then manage and deploy all GRANTS on these shares, letting you declaratively control which objects are exposed to the share.
All share properties supported by CREATE SHARE are available in DEFINE SHARE.
Functional limitations¶
- Consumer account assignment (
ALTER SHARE ... ADD ACCOUNTS) must be done manually outside of DCM, after database usage is granted to the share. DCM creates and manages the share object and its grants, but doesn’t configure which accounts can access the share.
DEFINE ROW ACCESS POLICY¶
You can define Snowflake row access policies directly in DCM Projects. DCM manages the row access policy lifecycle (CREATE, ALTER, DROP) across environments using Jinja templating. All row access policy properties supported by CREATE ROW ACCESS POLICY are available in DEFINE ROW ACCESS POLICY.
Functional limitations¶
- Row Access Policies can not yet be ATTACHED to tables as part of DCM definitions. You can manually apply policies outside of DCM.
DEFINE STREAMLIT¶
You can define one or more Streamlit apps, their infrastructure, underlying tables, and access control together in a single DCM Project folder, then deploy everything to any environment with one command.
This is especially useful for dashboard and data app deployments that depend on objects (tables, views, dynamic tables) also managed by DCM. The entire stack (data pipeline and the app consuming it) can be version-controlled and promoted through environments together.
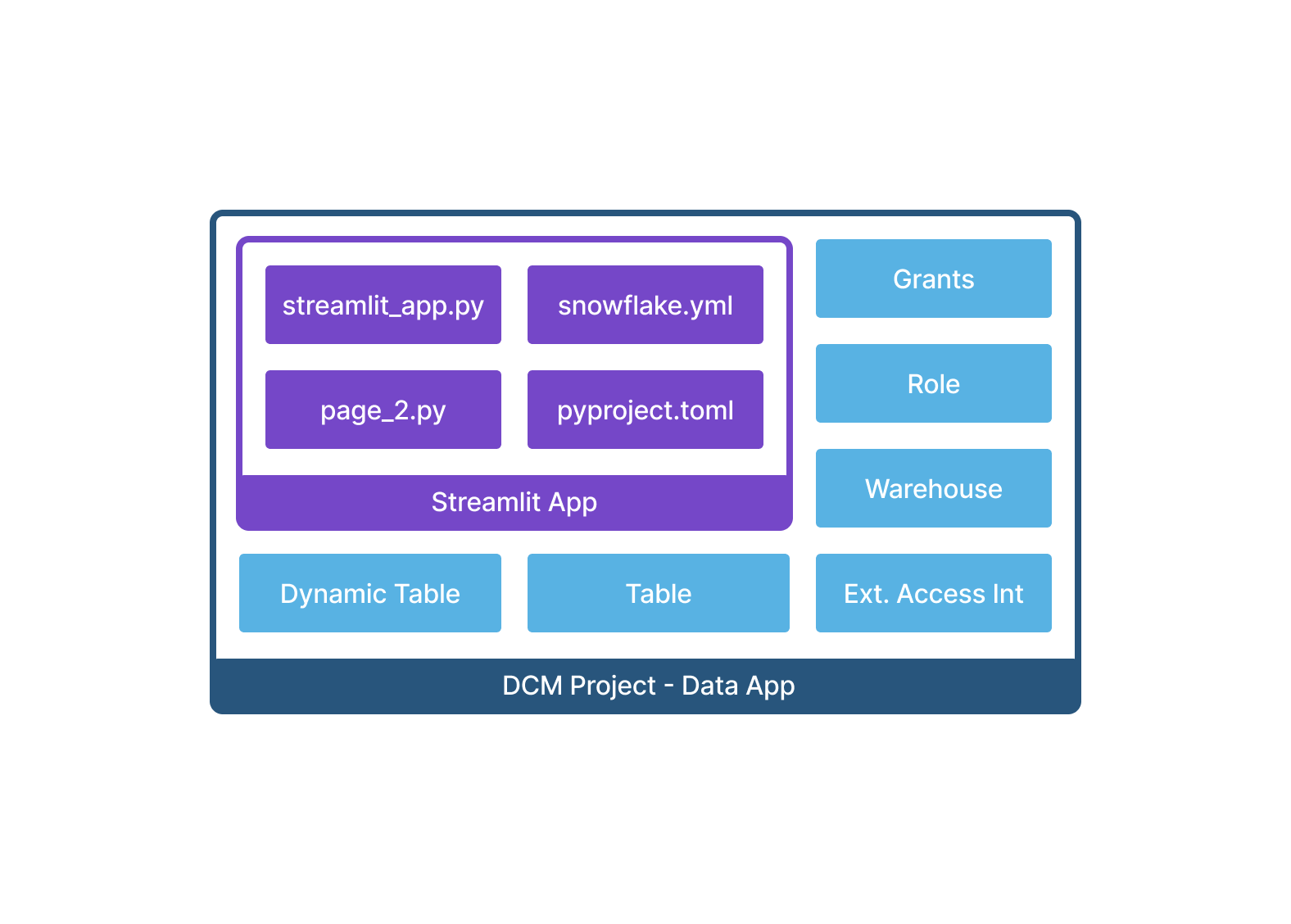
Create a DCM Project for Streamlit¶
You can take your existing Streamlit app folder, which includes:
streamlit_app.py(or any entrypoint file)environment.yml(for warehouse runtime) orrequirements.txtorpyproject.toml(for container runtime)- Any supporting Python modules, pages, or asset files
and move it inside the sources/ folder of your DCM Project, since the Snowflake CLI only uploads files from the sources/ folder hierarchy. Place it outside of sources/definitions/ and organize it in any subfolder structure you like, for example sources/streamlit/my_dashboard/.
Then add the DEFINE STREAMLIT statement to your DCM definitions with:
- The fully qualified name for the Streamlit object
- The relative path from the manifest to the Streamlit folder (always starting with
sources/) - The entrypoint file name (
MAIN_FILE) - The warehouse to use for query execution (
QUERY_WAREHOUSE) - The compute pool and runtime (
COMPUTE_POOL,RUNTIME_NAME) for container-runtime apps - An optional display title (
TITLE) - Any external access integrations (
EXTERNAL_ACCESS_INTEGRATIONS) and stage imports (IMPORTS) the app requires
Plan & deploy a DCM Project with a Streamlit app¶
Run your regular DCM plan and deploy commands. If either the DEFINE STREAMLIT statement in your definitions or the file hash for any of the files within the Streamlit app folder has changed since the last successful deployment, PLAN shows the Streamlit object as part of the changeset. DEPLOY replaces any modified files and creates a new version.
PLAN only validates that the Streamlit object can be created. It doesn’t test whether the app itself will run successfully when started.
After the first successful deployment, the Streamlit app is immediately live. DCM automatically initializes the live version after creating the Streamlit object, so you don’t need to run ALTER STREAMLIT manually.
Removing the DEFINE STREAMLIT statement drops the Streamlit object on the next deployment.
Functional limitations¶
-
DCM Jinja templating variables are not passed through to Streamlit Python files. You can use Jinja in the DEFINE STREAMLIT statement itself (for example, to set the warehouse or compute pool name), but not inside your app code.
- To reference environment-specific objects from inside your Streamlit app at runtime, query the active context using
CURRENT_DATABASE(),CURRENT_SCHEMA(), or similar functions to infer the environment.
- To reference environment-specific objects from inside your Streamlit app at runtime, query the active context using
-
Only relative paths to the Streamlit folder are supported. You can’t specify a path to another repo or folder outside of the DCM Project.
-
PLAN DELTA doesn’t yet detect changes to the DEFINE STREAMLIT statement or to files within the Streamlit app folder. While this is in early access, run a full PLAN to see these changes reflected in the changeset.
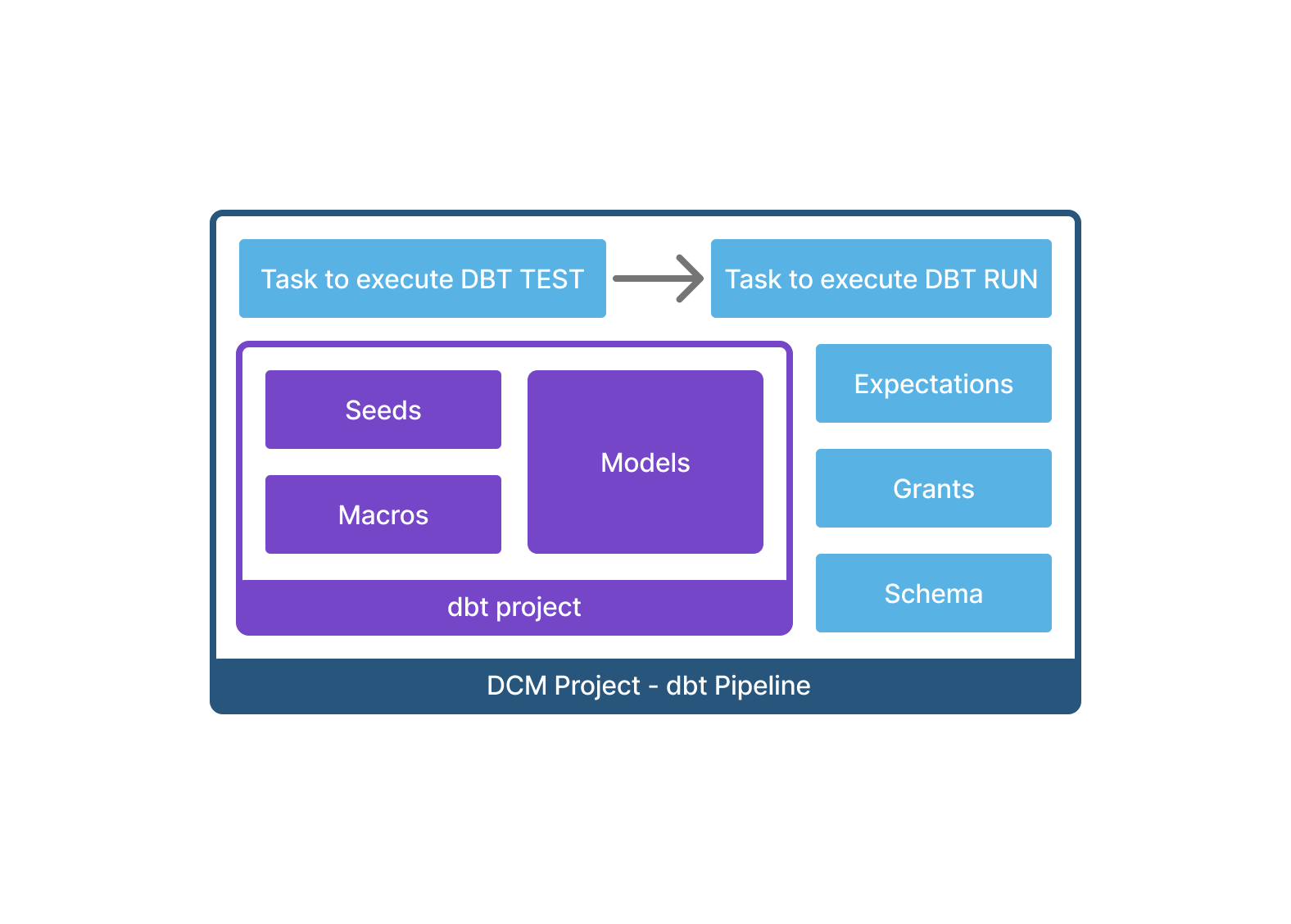
DEFINE DBT PROJECT¶
You can define a dbt project, its orchestration, infrastructure, and access control together in a single DCM Project folder, then deploy everything to any environment with one command.
Most commonly used is the combination of dbt projects + Tasks to execute dbt test and dbt run on a defined schedule. You can define a DAG of Tasks to orchestrate runs of different dbt projects or individual models.
Create a DCM Project for dbt¶
You can take your existing dbt project folder, which includes:
- models
- dbt_project.yml
- packages.yml
- profiles.yml
and move it inside the sources/ folder of your DCM Project, since the Snowflake CLI only uploads files from the sources/ folder hierarchy. Place it outside of sources/definitions/ and organize it in any subfolder structure you like, for example sources/dbt/dbt_pipeline/.
Then add the DEFINE DBT PROJECT statement to your DCM definitions with:
- The relative path from the manifest to the dbt folder (always starting with
sources/) - A default target (which can use jinja templating to match the DCM deployment target)
In addition, you can add Tasks to execute dbt commands after the deployment as well as grants on the dbt project object or future tables and views.
If you need to run dbt deps to get external packages, you can run CREATE NETWORK RULE IF NOT EXISTS and CREATE EXTERNAL ACCESS INTEGRATION IF NOT EXISTS in a DCM pre-hook (DCM Hooks are also part of this private preview).
Pass DCM variables to dbt¶
DCM Jinja templating and dbt templating variables are completely isolated. There’s no automatic pass-through between the DCM manifest.yml configuration and the dbt profiles.yml targets. The two configurations must be maintained separately and kept in sync.
If you need values from the DCM templating context inside a dbt run (for example, the active dbt target), pass them explicitly through the args of the EXECUTE DBT PROJECT statement. Jinja in args is rendered by DCM before the command is executed, so any DCM templating variable can be injected.
Plan & deploy a DCM Project for dbt¶
Run your regular DCM plan and deploy commands. If the DEFINE DBT PROJECT statement in your definitions has changed since the last successful deployment, then PLAN will:
- Render the jinja templating
- Compile the entire DCM Project
- Show the dbt project as part of the plan output
The dbt project is compiled during DEPLOY, not during PLAN. PLAN only validates that the dbt project object can be created successfully. It doesn’t check whether the dbt project will run successfully.
Tables created by dbt don’t show as “DCM managed entities” because they aren’t defined directly in the DCM definitions. Removing the DEFINE DBT PROJECT statement drops the dbt project object on the next deployment, but it won’t drop the tables created by dbt.
You can also consider creating a new DCM Project for dbt on top of an existing “platform” project.
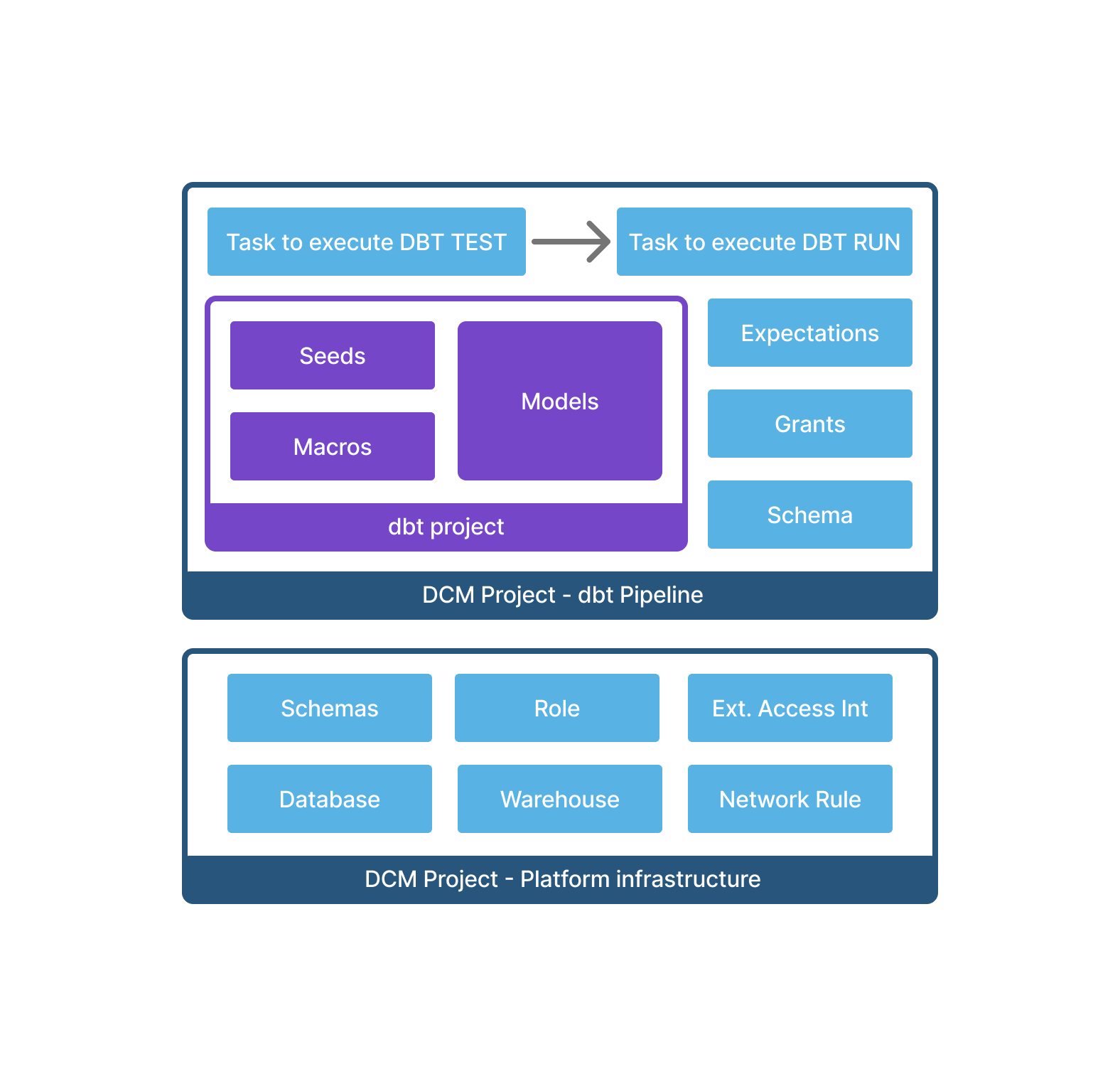
Functional limitations¶
- PLAN and DEPLOY output only show the operation for a Snowflake
dbt projectobject (CREATE / ALTER / DROP) and don’t show more granular changes in the dbt project configuration or models. - Dependencies: dbt models can refer to other objects defined in DCM, but other DCM objects can’t reference tables created by dbt, meaning dbt projects can’t have downstream dependencies.
- Currently, only relative paths to dbt project files are supported. You can’t specify a path to another repo or folder outside of the DCM Project.
- PLAN DELTA doesn’t yet detect changes to the DEFINE DBT PROJECT statement or to files within the dbt project folder. While this is in early access, run a full PLAN to see these changes reflected in the changeset.
CLI enhancements¶
An early-access version of the Snowflake CLI includes improvements to several DCM Projects commands.
Re-run the same command with --force occasionally to pick up the latest updates to the early-access build:
To revert to the latest official release on main:
Note
Details of these improvements (such as syntax and output format) are subject to change while they’re in early access.
All of the commands below (except snow dcm init) support the --save-output flag, which saves the command output as a .json file under out/.
snow dcm plan¶
- Shows a compressed file upload summary (file counter per path) with a progress bar
- Shows more granular changes for ALTER operations in the output
snow dcm deploy¶
- Shows a compressed file upload summary (file counter per path) with a progress bar
- Shows a progress bar for the PLAN and DEPLOY execution phases
- Shows more granular changes for ALTER operations in the output
snow dcm compile (new command)¶
snow dcm compile runs a static analysis of all DCM definitions and returns any errors or warnings found, grouped by file and entity. It’s intended for quickly checking iterative definition changes and catching errors before committing.
- Validates syntax and dependencies
- Runs faster than PLAN, but doesn’t catch all possible errors. (Always run PLAN to preview changes before deploying)
- Shows a compressed file upload summary (file counter per path) with a progress bar
snow dcm dependencies (new command)¶
snow dcm dependencies runs a static analysis of all DCM definitions and builds a Mermaid flowchart representing the dependencies between all objects in the project (tables, dynamic tables, views, functions, procedures, and tasks).
The diagram is written to out/dependencies.md. The CLI prints a link to the file so you can open it in your IDE’s Markdown preview and explore the dependency graph visually.
Note that these dependencies refer to the deployment of objects (CREATE). It does not resolve run-time dependencies (for example, a Task that calls a stored procedure).
- Generate a dependency diagram for the current project:
snow dcm init (new command)¶
snow dcm init is the starting point for two common workflows: creating a brand-new empty DCM Project, or deploying an existing set of DCM definitions (from a repository or local path) to a new target environment.
In both cases it bootstraps the project in a single run: it writes or updates a manifest.yml, creates the DCM Project object in Snowflake, and provisions any missing supporting objects (database, schema, warehouse).
Before making any change, it prints a summary of every action and asks for confirmation. Nothing is created if you decline.
To start a new project the init process will walk you through all required steps for setting up a new project structure:
If you want to use an existing project folder and add a new target for a new account, then run init from a directory that already contains a manifest.yml.
A new target block is appended and your existing definitions are left untouched:
During a run, init resolves everything a target needs:
- Target name — defaults to your account alias; re-prompts if the name is invalid or already used.
- DCM Project object name — defaults to the target name. Identifiers with special characters are automatically wrapped in double quotes.
- Database and schema — uses your connection’s defaults (or prompts when there are none) and creates them if they don’t exist.
- Project owner — uses your current role, or prompts if it can’t be determined.
- Warehouse — uses your connection’s warehouse, or provisions an X-Small
DCM_WH(or a name you choose) and tells you how to configure it.
For automation and CI, pass --force to approve all changes non-interactively. --force requires --target; if that target already exists it’s reused as-is rather than failing:
The following options control init behavior:
| Option | Description |
|---|---|
--project-name <name> | Create a new project in a subfolder of this name. Omit to add a target to an existing manifest.yml. |
--target <name> | Name of the target to create in the manifest. Defaults to the account alias. Required with --force. |
--project-identifier <id> | Identifier of the DCM Project object (for example, MY_DB.MY_SCHEMA.MY_PROJECT). Defaults to the target name. |
--if-not-exists | Do nothing if the DCM Project object already exists in Snowflake. |
--force | Approve all changes non-interactively. |
Pre-hooks for Integrations¶
DDL Pre-hooks are intended as an interim solution for defining integrations until they are supported natively in DCM using DEFINE statements. DDL Hooks do not offer full functional parity to regular DCM definitions.
Capabilities of DDL Pre-hooks¶
- Each DCM Project can contain only 1 pre-hook
- The pre-hook can contain multiple DDL statements
- DDL statements inside the hook are executed in the order they are defined
- The hook supports only 2 types of commands:
- CREATE IF NOT EXISTS (recommended)
- For one-time execution to create the object
- Skipped any time an integration with this name already exists
- CREATE OR REPLACE
- Executed at every DCM deployment
- Use when the definition of an existing object has changed and should be replaced completely
- Only DDL statements are supported (no USE, no SET, no COPY INTO…)
Key advantages of pre-hooks compared to custom SQL pre-scripts¶
- Pre-hooks are plannable. Other DCM definitions can declare dependencies on objects created in the pre-hook.
- Example: A Notification Integration defined in the pre-hook can be referenced by an Alert defined in DCM definitions.
- Pre-hooks support Jinja templating, using the same variables as the rest of the DCM Project.
Functional limitations¶
- Create statements from pre-hooks show as operations in the PLAN changeset and the deployment history, but don’t include granular details about their individual properties.
- Errors from executing pre-hooks don’t show the exact error line and in some cases not the full stack-trace.
- Removing a DDL statement from a pre-hook does NOT drop the object.
- Pre-hooks can’t be defined inside Jinja loops, as it would create multiple pre-hooks. However, Jinja code including loops can be used inside a hook.
Warning
Do not use pre-hooks for object definitions that contain sensitive information or credentials. The rendered SQL definitions will not redact any values inserted by environment variables!
Comparison between DCM definitions, DCM pre-hooks, custom SQL pre-scripts¶
| Functionality | DCM Definitions | DCM pre-hooks | Custom SQL scripts |
|---|---|---|---|
| Uses DCM Jinja templating values | ✅ | ✅ | 🚫 |
| Plannable dependencies | ✅ | ✅ | 🚫 |
| DDL operations visible in PLAN output | ✅ | ✅ | 🚫 |
| DDL operations stored in DCM deployment artifacts | ✅ | ✅ | 🚫 |
| Removing definition -> drops object | ✅ | 🚫 | 🚫 |
| Changed definition -> alters object | ✅ | ✅ (when using CREATE OR REPLACE) | 🚫 |
| Automatically executed in the correct order based on dependencies | ✅ | 🚫 | 🚫 |
Supported object types for DDL Hooks¶
Only integration object types are supported:
- API Integration
- Notification Integration
- External Access Integration
- Catalog Integration
- Security Integration
- Storage Integration
Once these object types are supported natively with DCM DEFINE statements, the hook support will be deprecated.
Examples: