SnowConvert AI - ベストプラクティス¶
1.抽出¶
ワークロードの抽出には、当社のスクリプトを使用することを強くお勧めします。
Teradata: DDL Export Scripts for Teradata.
Oracle: DDL Export Scripts for Oracle.
SQLServer: DDL Export Scripts for SQL Server.
Redshift: Redshift code extraction guide.
2.前処理¶
評価や変換を開始する前に、より良い結果を得ることを目的とした前処理スクリプトを使用することを強くお勧めします。このスクリプトは以下のタスクを実行します。
各トップレベルオブジェクトに1つのファイルを作成します。
定義されたフォルダー階層によって各ファイルを整理します(デフォルトは、データベース名 -> スキーマ名 -> オブジェクトタイプ)。
ワークロードにあるすべてのオブジェクトの情報を提供するインベントリレポートを作成します。
2.1 ダウンロード¶
Download the binary of the script for macOS and make sure to follow the setup instructions in Step 2.3.
Download the binary of the script for Windows.
2.2 説明¶
スクリプトの実行には以下の情報が必要です。
スクリプト引数 |
値の例 |
必須 |
使用状況 |
|---|---|---|---|
入力フォルダー |
|
有り |
|
出力フォルダー |
|
有り |
|
データベース名 |
|
有り |
|
データベースエンジン |
|
有り |
|
出力フォルダー構造 |
|
無し |
|
ピボットテーブル生成 |
|
無し |
|
注釈
データベースエンジンの引数(-e)でサポートされている値は、Oracle、MSSL、Teradataです。
注釈
The supported values for the output folder structure argument (-s) are: database_name, schema_name and top_level_object_name_type.
When specifying this argument, all the previous values need to be separated by a comma. For example: -s database_name,top_level_object_name_type,schema_name.
この引数はオプションで、指定しない場合のデフォルトの構造は次のとおりです。データベース名、トップレベルオブジェクト型、スキーマ名。
注釈
ピボットテーブル生成パラメーター(-p)はオプションです。
2.3 Mac用バイナリのセットアップ¶
バイナリを実行可能ファイルとして設定します。\
chmod +x standardize_sql_files以下のコマンドを実行してスクリプトを実行します。
./standardize_sql_filesバイナリを初めて実行する場合は、以下のメッセージがポップアップ表示されます。\
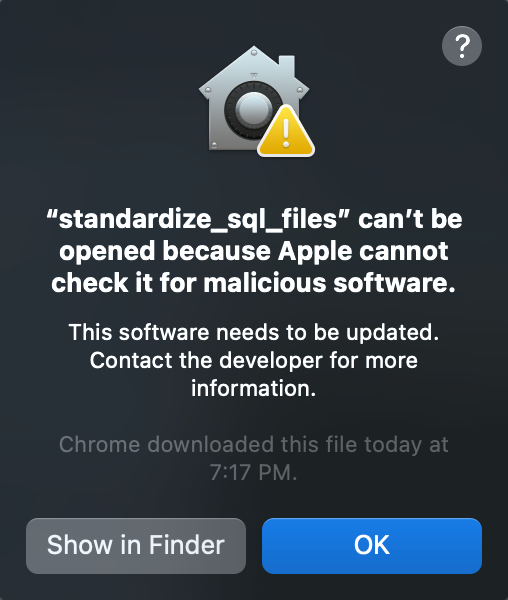 OK をクリックします。
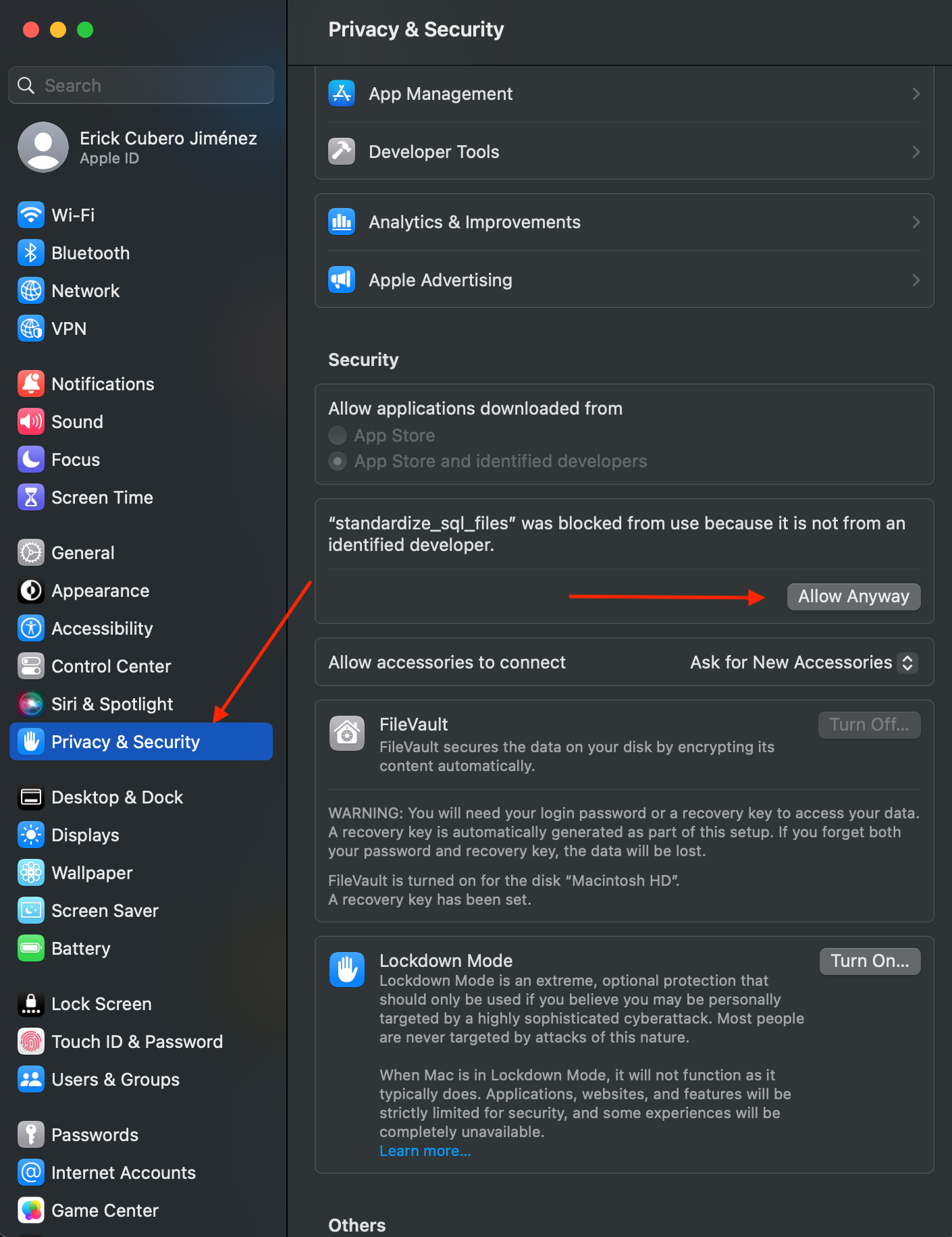
OK をクリックします。設定を開く -> プライバシーおよびセキュリティ -> とにかく矢印をクリック\
スクリプトの実行¶
以下の形式でスクリプトを実行します。
Mac形式\
./standardize_sql_files -i "入力パス" -o "出力パス" -d Workload1 -e teradataWindows形式\
./standardize_sql_files.exe -i "入力パス" -o "出力パス" -d Workload1 -e teradata
スクリプトが正常に実行されると、以下の出力が表示されます。
Splitting process completed successfully!
Report successfully created!
Script successfully executed!