Snowpark Migration Accelerator: Resultado da avaliação - Pasta de relatórios¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we’ll examine some key .csv files to understand the migration requirements, we won’t cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
Para visualizar os relatórios, clique no botão «VIEW REPORTS» na parte inferior da tela. Isso abrirá o explorador de arquivos no diretório que contém os relatórios.
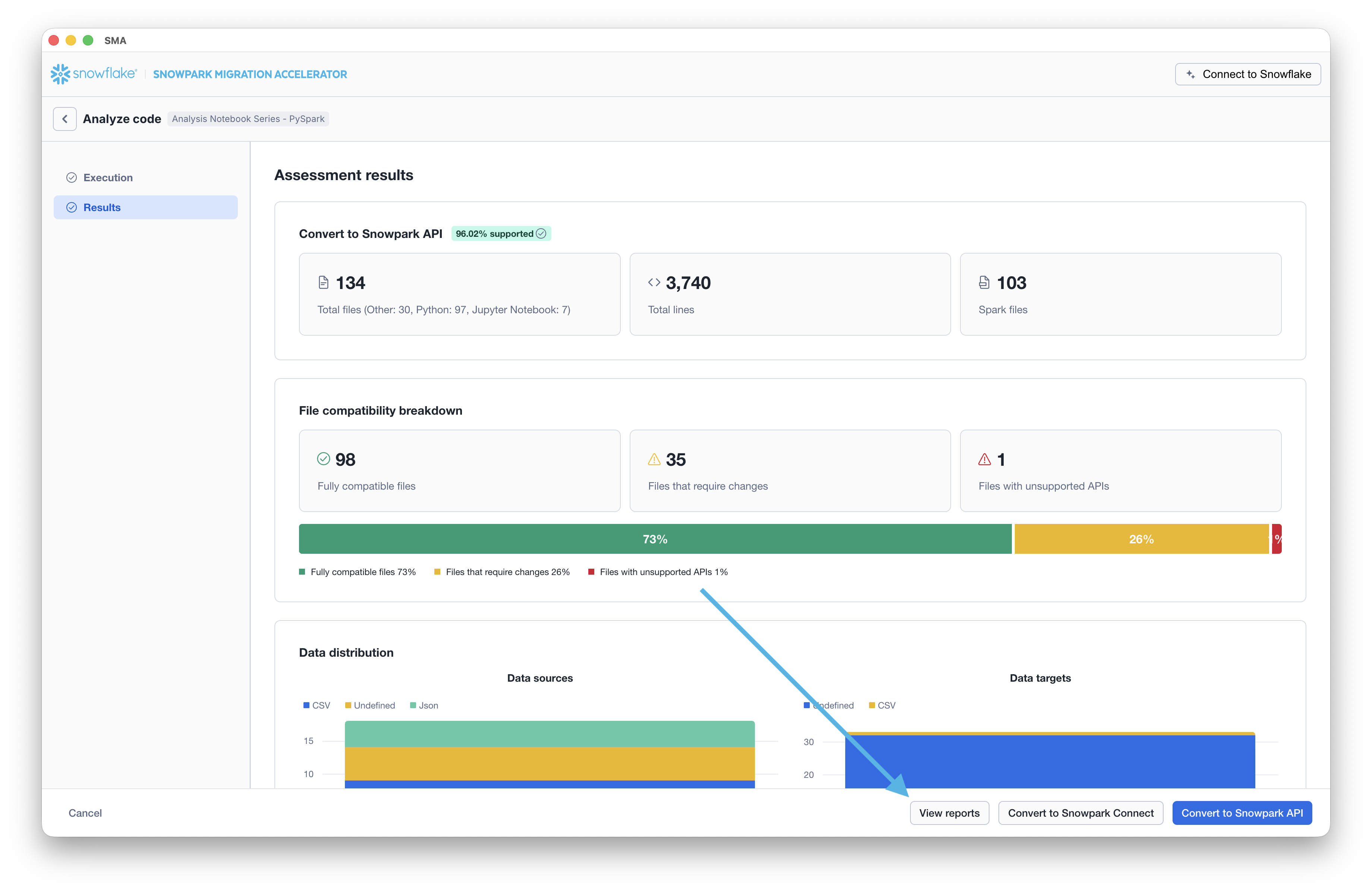
Vamos examinar as informações que podemos obter no Relatório Detalhado.
Nota
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
O relatório detalhado¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report’s contents is available in the detailed documentation, this guide focuses on three key aspects:
Elementos importantes a serem analisados
Seu impacto nas pontuações de preparação
Como interpretar os resultados
Analise todas as pontuações de preparação disponíveis em seu relatório para entender seu status de preparação para a migração.
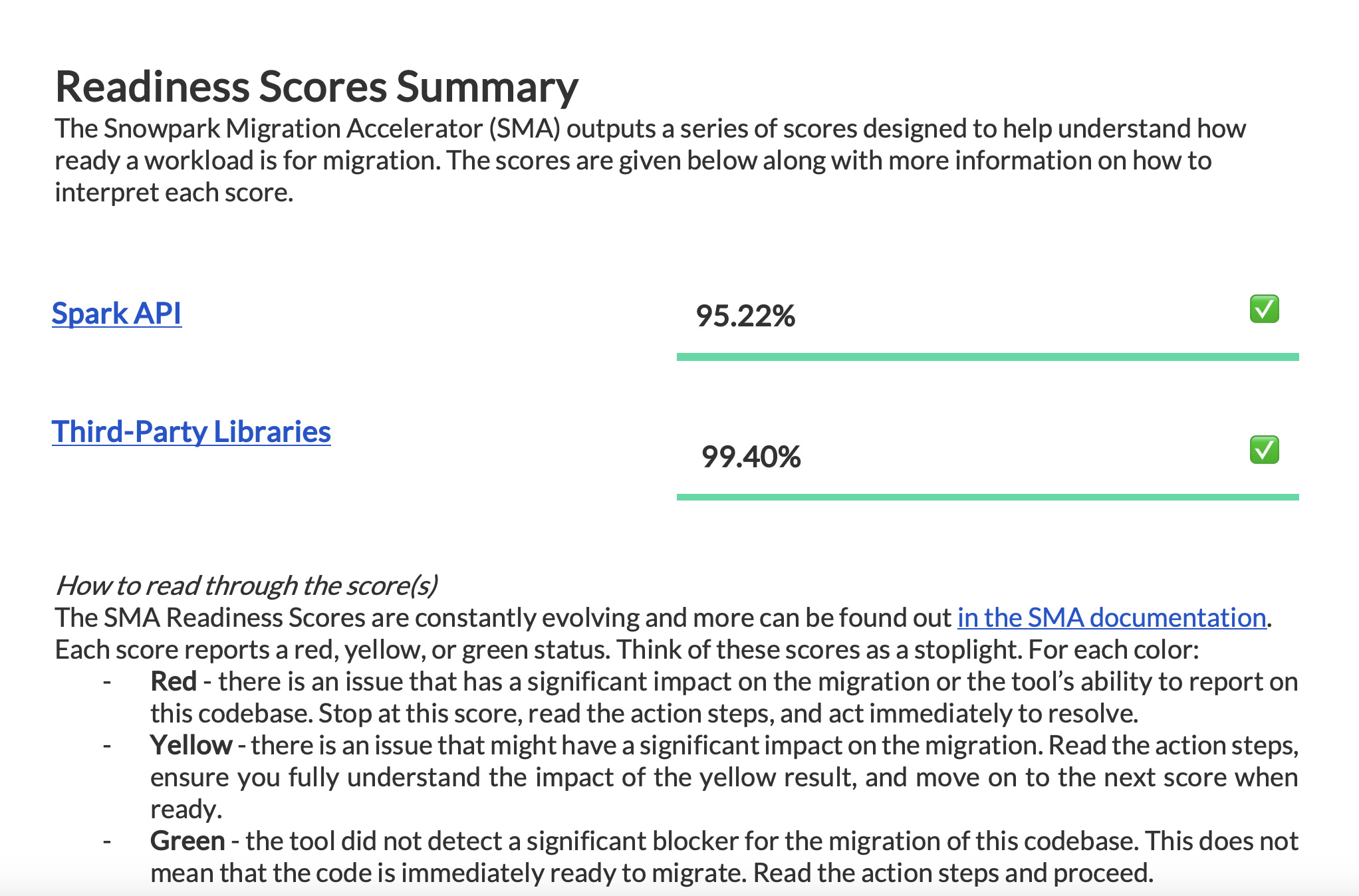
Pontuação de preparação do Spark API¶
Let’s clarify what the Spark API Readiness score means and how it’s calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It’s important to note that this score only considers Spark API usage and doesn’t account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
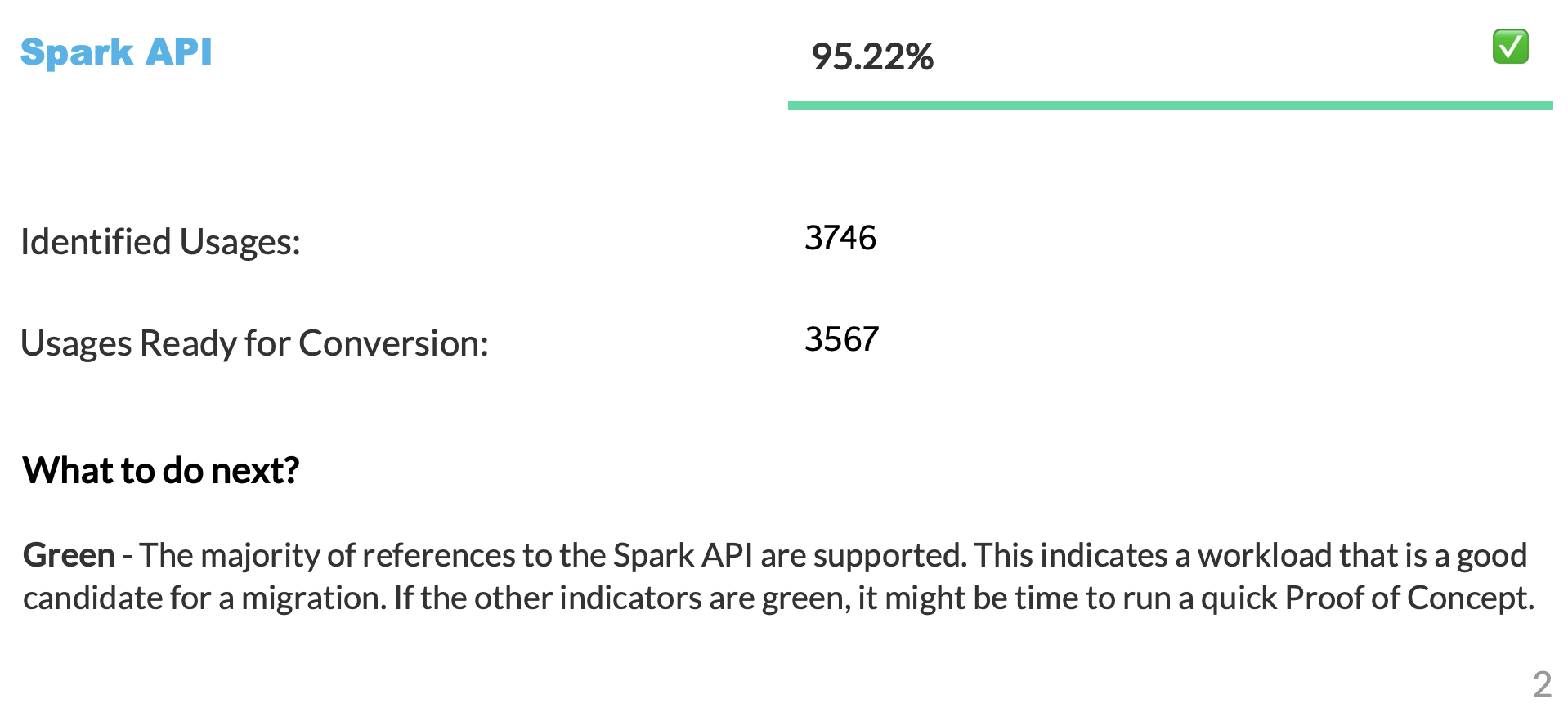
A pontuação de conversão representa a proporção de referências Spark API que podem ser convertidas automaticamente para Snowpark API, em comparação com o número total de referências Spark API encontradas em seu código. Nesse caso, 3541 das 3746 referências podem ser convertidas. Uma pontuação mais alta indica que mais do seu código pode ser migrado automaticamente para o Snowpark. Embora o código não convertido ainda possa ser adaptado manualmente para funcionar com o Snowpark, essa pontuação fornece uma indicação confiável do grau de adequação da sua carga de trabalho à migração automática.
Pontuação de preparação das bibliotecas de terceiros¶
A pontuação de preparação de bibliotecas de terceiros ajuda a entender quais APIs externas são usadas em seu código. Essa pontuação fornece uma visão geral clara de todas as dependências externas em sua base de código.
Página de resumo¶
A página Summary exibe sua pontuação de preparação e fornece uma visão geral dos resultados de sua execução.
O que procurar Verifique a pontuação de preparação para avaliar o quanto sua base de código está preparada para converter referências Spark API em referências Snowpark API. Uma alta pontuação de preparação indica que o código do Spark é adequado para a migração para o Snowpark.
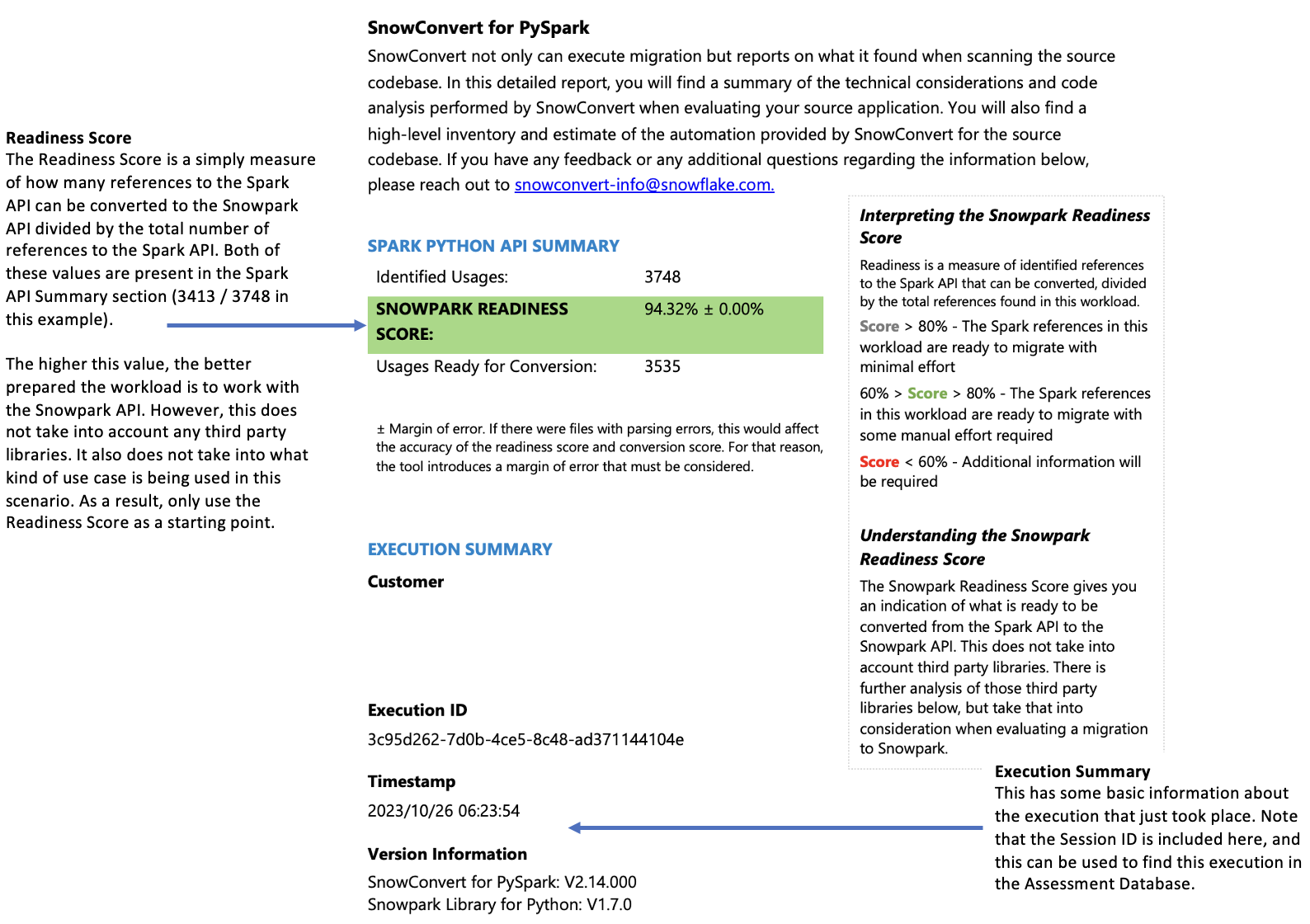
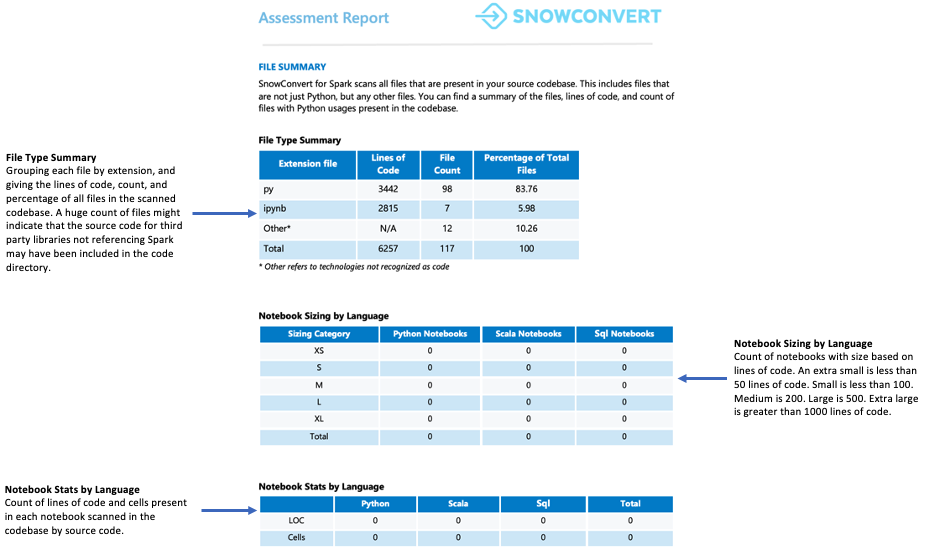
Resumo do arquivo¶
O resumo do arquivo fornece uma visão geral de sua base de código, incluindo:
Total de linhas de código por extensão de arquivo
Informações sobre células do notebook (se os notebooks foram analisados)
Número de arquivos que contêm consultas SQL incorporadas
O que você deve observar?
O número e o conteúdo dos arquivos. Se encontrar muitos arquivos, mas apenas alguns contiverem referências ao Spark API, isso pode significar:
O aplicativo usa o Spark minimamente (talvez apenas para extração e carregamento de dados)
O código-fonte inclui dependências de bibliotecas externas
O caso de uso precisa de mais investigação para entender como o Spark está sendo utilizado
Em ambos os casos, é importante analisar minuciosamente o caso de uso antes de prosseguir.
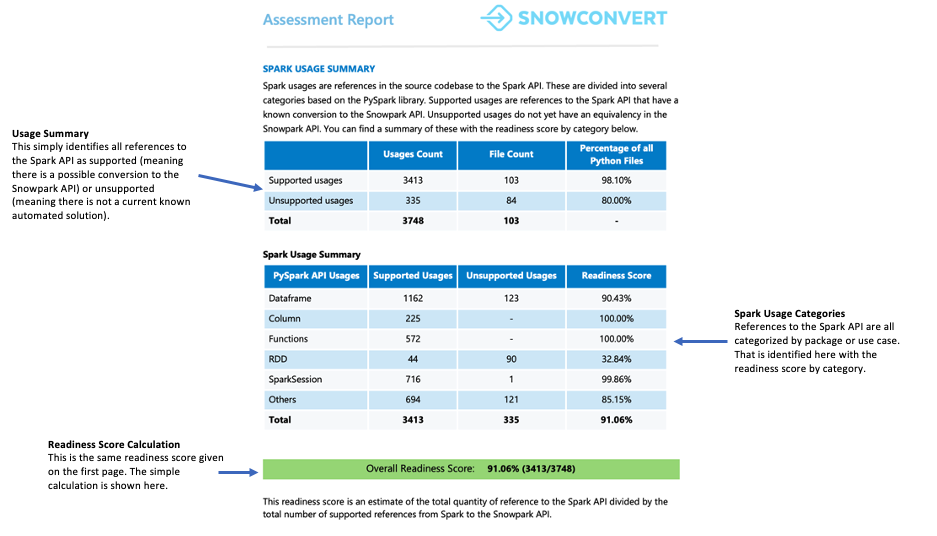
Resumo do uso do Spark¶
O Resumo de uso do Spark fornece uma análise detalhada das referências do Spark API encontradas em seu código e identifica quais podem ser convertidas para o Snowpark API. O resumo categoriza essas referências em diferentes tipos, incluindo operações DataFrame, manipulações de coluna, chamadas SparkSession e outras funções API.
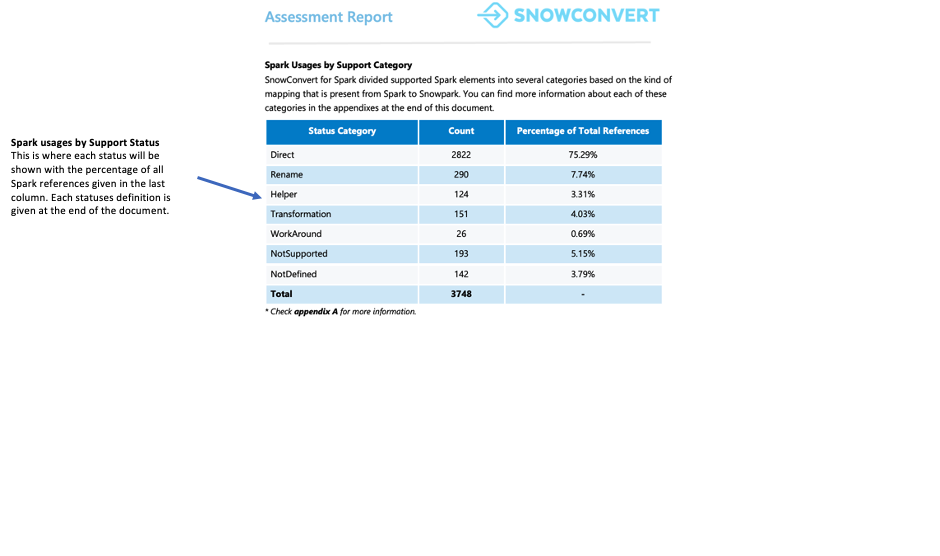
Cada referência é classificada em um dos sete status de suporte. Esses status indicam se e como uma referência pode ser suportada no Snowpark. As definições detalhadas desses status podem ser encontradas nos apêndices do relatório.
Direto: A função existe tanto no PySpark quanto no Snowpark e pode ser usada sem alterações.
Renomear: A função existe em ambas as estruturas, mas requer uma mudança de nome no Snowpark.
Helper: A função requer uma pequena modificação no Snowpark que pode ser resolvida com a criação de uma função auxiliar equivalente.
Transformação: A função precisa ser totalmente reconstruída no Snowpark usando métodos diferentes ou várias etapas para obter o mesmo resultado.
Solução alternativa: A função não pode ser convertida automaticamente, mas há uma solução manual documentada disponível.
NotSupported: A função não pode ser convertida porque o Snowflake não tem um recurso equivalente. A ferramenta adicionará uma mensagem de erro ao código.
NotDefined: O elemento PySpark ainda não está incluído no banco de dados da ferramenta de conversão e será adicionado em uma atualização futura.
O que você deve observar?
A pontuação de preparação é exibida nessa seção. Você pode analisar quantas referências de código precisarão de soluções alternativas em vez de conversões diretas. Se o seu código exigir muitas soluções alternativas, auxiliares e transformações, recomendamos o uso do Snowpark Migration Accelerator (SMA) para ajudar a migrar sua base de código com eficiência.
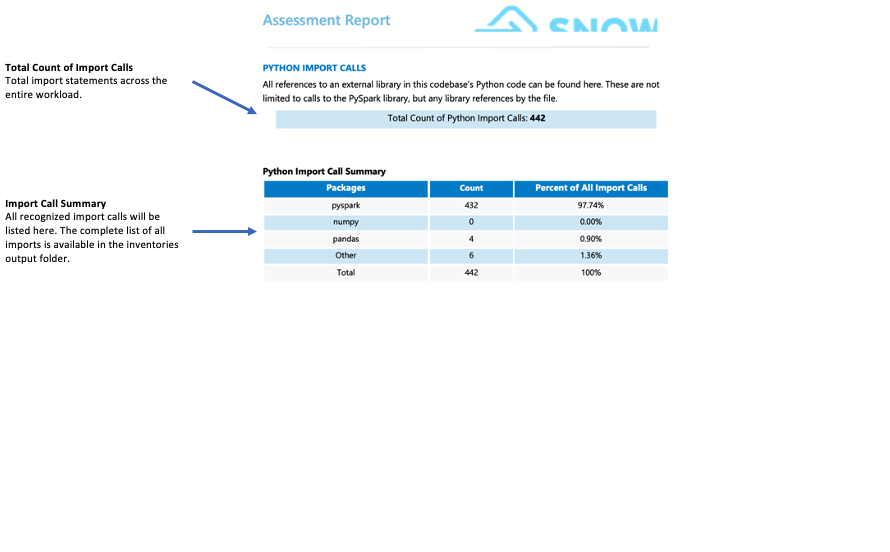
Importar chamadas:¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
O que você deve observar?
As bibliotecas de terceiros não compatíveis com o Snowflake podem afetar significativamente a preparação da migração. Se o seu código importar bibliotecas como mllib, streaming ou bibliotecas de terceiros, como graphs, subprocess ou smtplib, você poderá enfrentar desafios de migração. Embora a presença dessas bibliotecas não impossibilite automaticamente a migração, ela exige uma análise mais profunda do seu caso de uso. Nessas situações, recomendamos consultar a equipe do WLS para uma avaliação detalhada.
Resumo dos problemas do Snowpark Migration Accelerator¶
Esta seção fornece uma visão geral dos possíveis problemas e erros que podem ocorrer durante a migração da carga de trabalho. Embora informações detalhadas sobre elementos não conversíveis estejam disponíveis em outros lugares, esta seção é particularmente valiosa durante os estágios iniciais do processo de conversão.
Problemas comuns a serem observados
Para encontrar elementos que não foram convertidos ou que têm soluções alternativas conhecidas, verifique o inventário de referência do Spark em sua pasta de inventários locais. Você pode comparar esses elementos com os mapeamentos existentes consultando o banco de dados.

Resumo:¶
A pontuação de preparação indica o quanto sua base de código está preparada para a migração para o Snowpark. Uma pontuação de 80% ou mais significa que seu código está praticamente pronto para a migração. Se a pontuação for inferior a 60%, você precisará fazer modificações adicionais no código antes de continuar.
Para essa carga de trabalho, a pontuação excede 90%, o que indica excelente compatibilidade para migração.
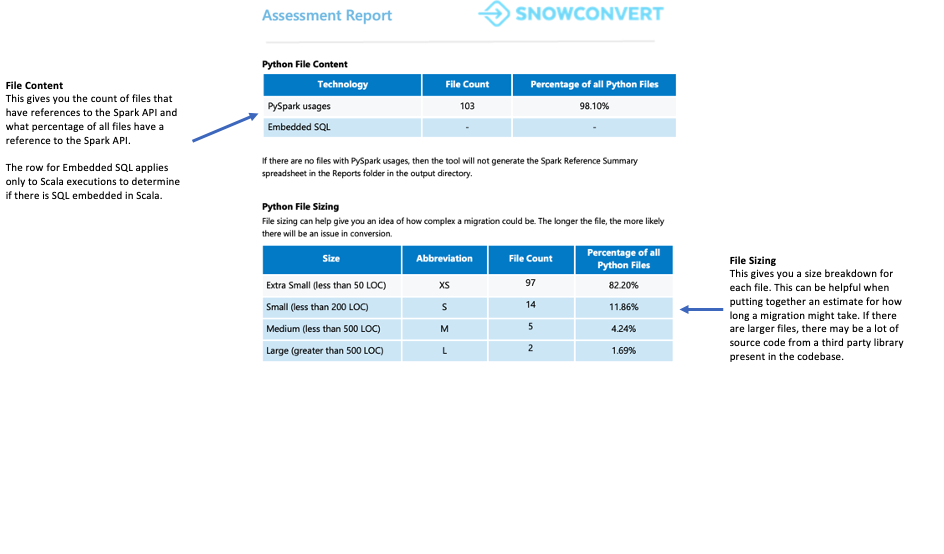
O próximo indicador é tamanho. Uma carga de trabalho com código extenso, mas com poucas referências ao Spark API, pode sugerir uma grande dependência de bibliotecas de terceiros. Mesmo que um projeto tenha uma baixa pontuação de preparação, ele pode ser rapidamente convertido manualmente se contiver apenas cerca de 100 linhas de código ou 5 referências Spark API, independentemente das ferramentas de automação.
Para essa carga de trabalho, o tamanho é razoável e fácil de manusear. A base de código contém mais de 100 arquivos com menos de 5.000 referências Spark API e menos de 10.000 linhas de código. Aproximadamente 98% desses arquivos contêm referências ao Spark API, indicando que a maior parte do código Python está relacionada ao Spark.
O terceiro indicador a ser examinado é bibliotecas importadas. O inventário de instruções de importação ajuda a identificar quais pacotes externos o código usa. Se o código depender muito de bibliotecas de terceiros, pode ser necessária uma análise adicional. Em casos com várias dependências externas, consulte a equipe de Serviços de Carga de Trabalho (WLS) para entender melhor como essas bibliotecas estão sendo usadas.
Neste exemplo, temos algumas bibliotecas de terceiros referenciadas, mas nenhuma delas está relacionada a aprendizado de máquina, streaming ou outras bibliotecas complexas que seriam difíceis de implementar no Snowpark.
Como essa carga de trabalho é adequada para a migração para o Snowpark, prossiga para a próxima etapa do processo de migração do Spark.