Snowpark Migration Accelerator : Sortie de l’évaluation - Dossier des rapports¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we’ll examine some key .csv files to understand the migration requirements, we won’t cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
Pour voir les rapports, cliquez sur le bouton « VIEW REPORTS » en bas de l’écran. Votre explorateur de fichiers s’ouvrira alors sur le répertoire contenant les rapports.
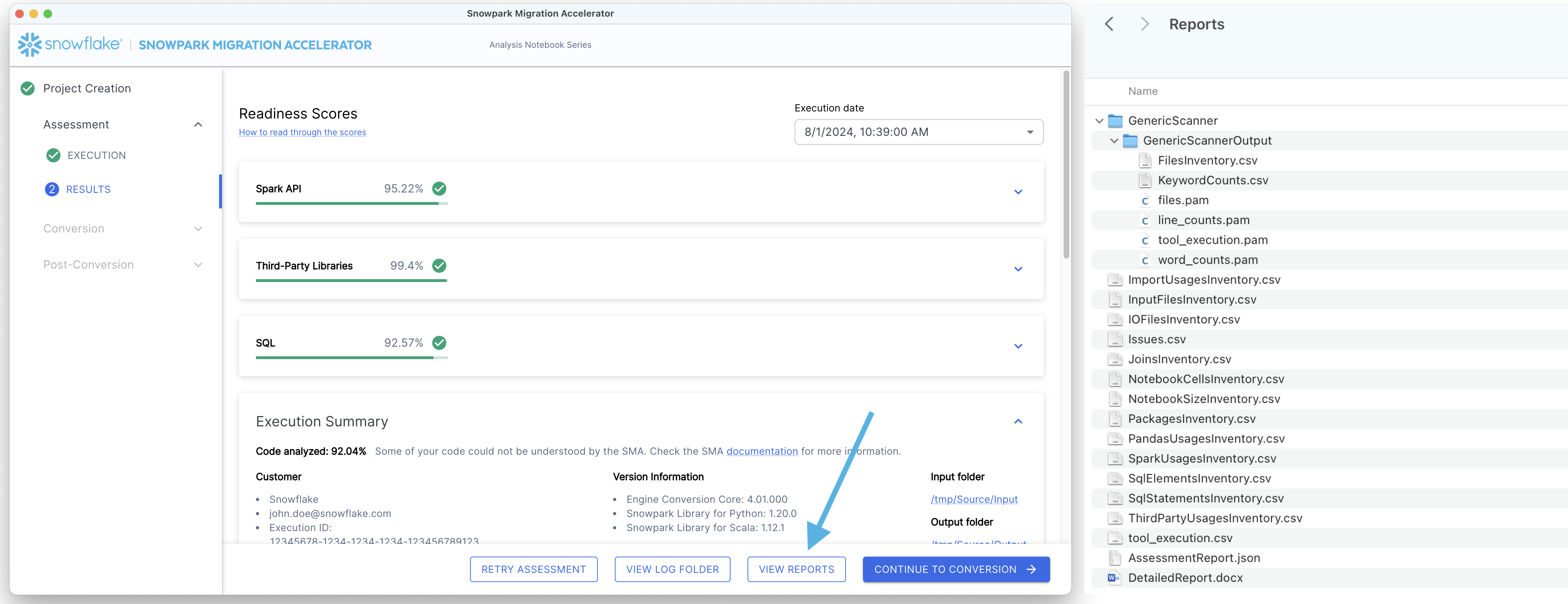
Examinons les informations que nous pouvons tirer du rapport détaillé.
Note
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
Le rapport détaillé¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report’s contents is available in the detailed documentation, this guide focuses on three key aspects:
Éléments importants à examiner
Leur impact sur les scores de préparation
Comment interpréter les résultats
Examinez tous les scores de préparation disponibles dans votre rapport pour comprendre le statut de votre préparation à la migration.
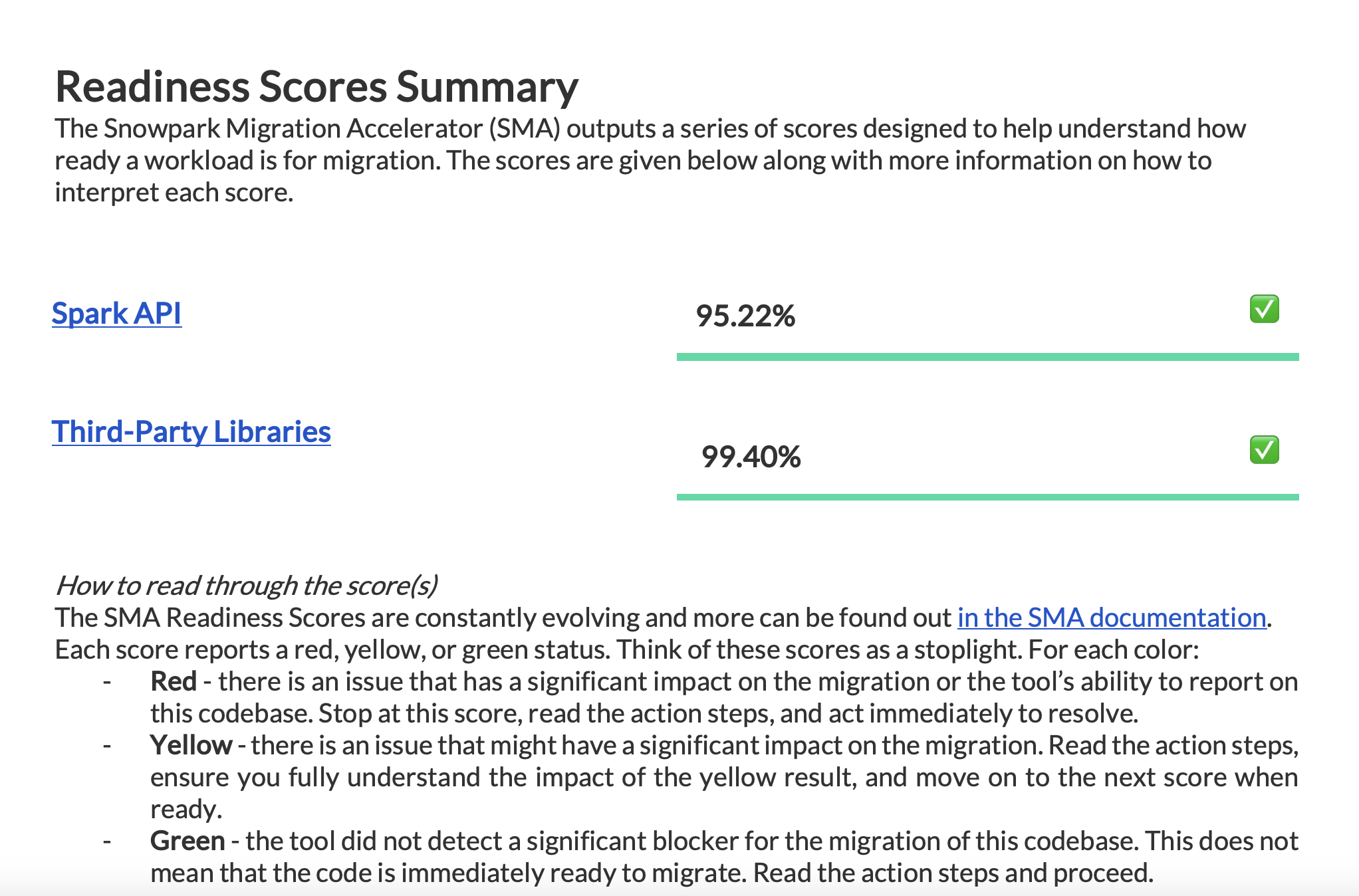
Le score de préparation Spark API¶
Let’s clarify what the Spark API Readiness score means and how it’s calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It’s important to note that this score only considers Spark API usage and doesn’t account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
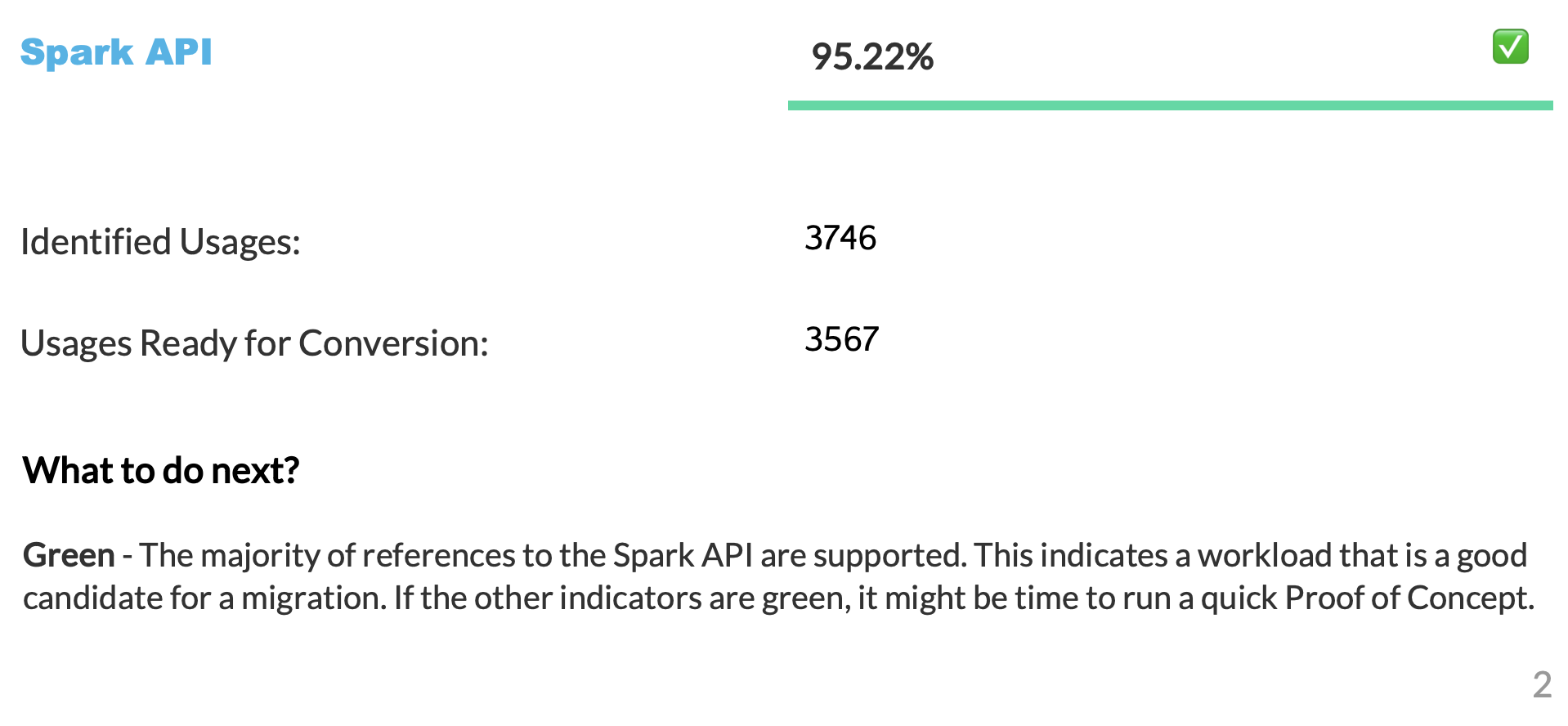
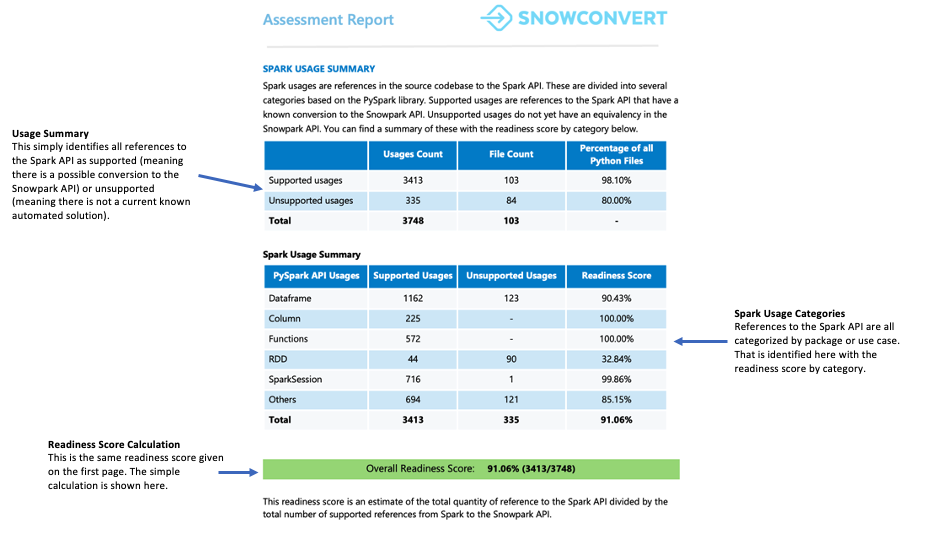
Le score de conversion représente le ratio des références Spark API qui peuvent être automatiquement converties en Snowpark API, par rapport au nombre total de références Spark API trouvées dans votre code. Dans ce cas, 3 541 références sur 3 746 peuvent être converties. Un score plus élevé indique qu’une plus grande partie de votre code peut être migrée automatiquement vers Snowpark. Bien que le code non converti puisse encore être adapté manuellement pour fonctionner avec Snowpark, ce score fournit une indication fiable de l’adéquation de votre charge de travail à la migration automatique.
Score de préparation des bibliothèques tierces¶
Le score de préparation des bibliothèques tierces vous aide à comprendre quelles APIs externes sont utilisées dans votre code. Ce score donne un aperçu clair de toutes les dépendances externes de votre base de code.
Page de résumé¶
La page Résumé affiche votre score de préparation et donne un aperçu de vos résultats en matière d’exécution.
Ce qu’il faut rechercher : Vérifiez le score de préparation pour évaluer dans quelle mesure votre base de code est prête pour convertir les références Spark API en références Snowpark API. Un score de préparation élevé indique que le code Spark est bien adapté à la migration vers Snowpark.
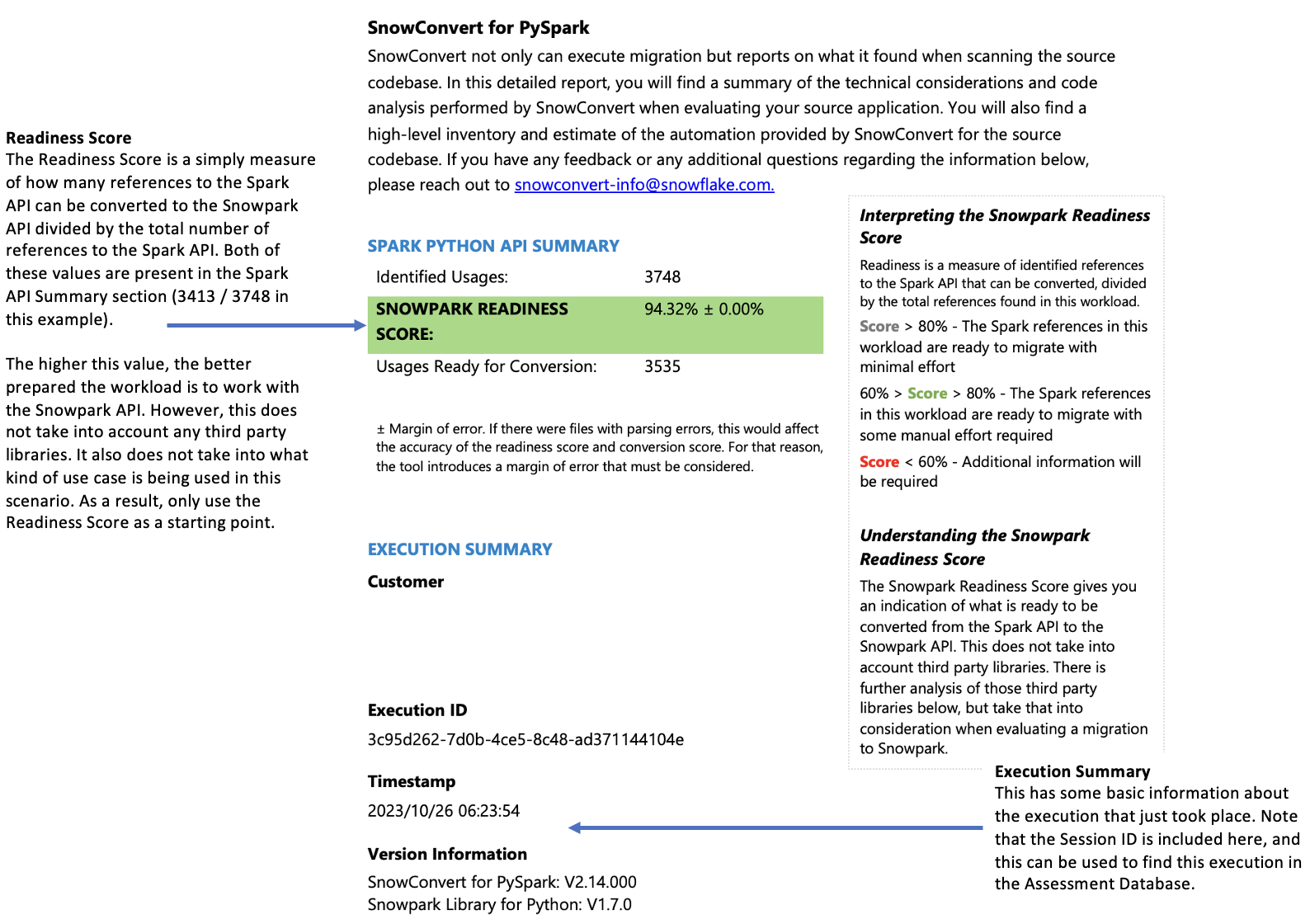
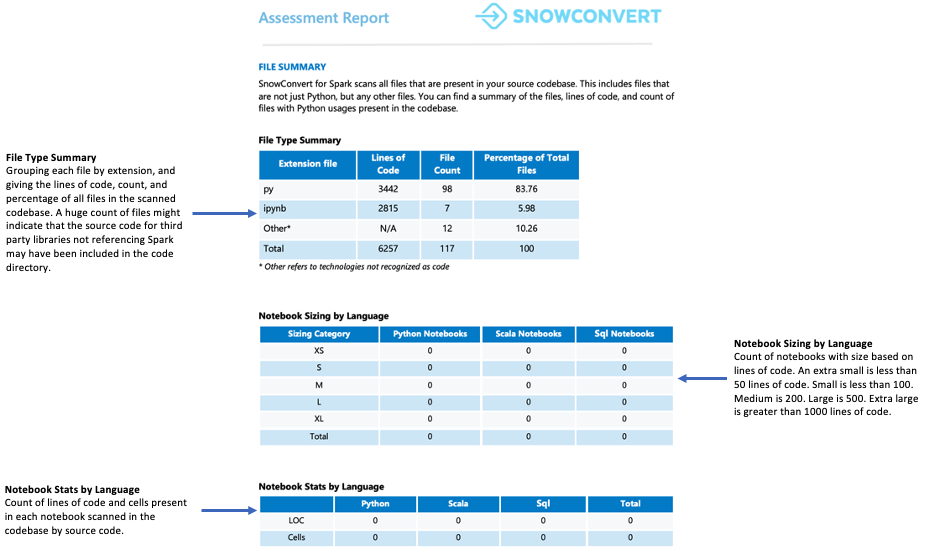
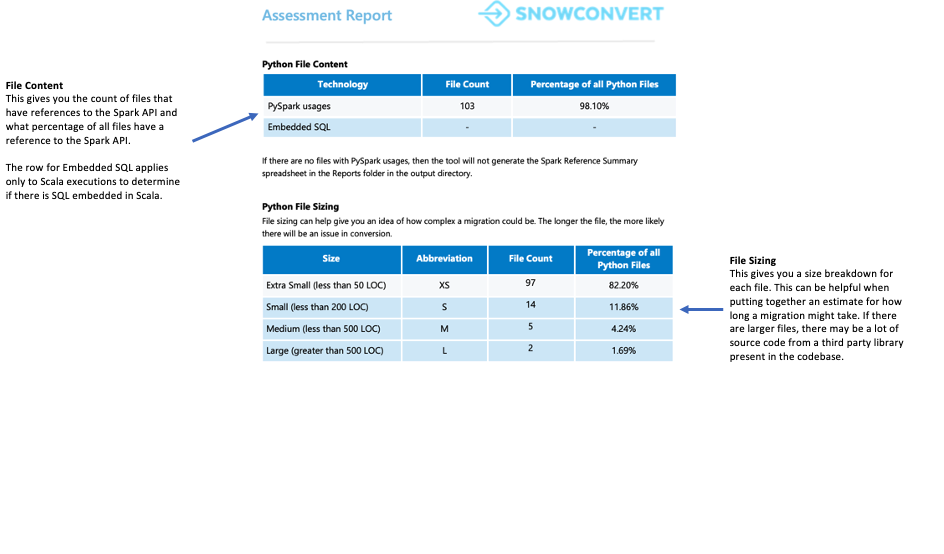
Résumé du fichier¶
Le résumé du fichier donne un aperçu de votre base de code, y compris :
Le nombre total de lignes de code par extension de fichier
Les informations sur les cellules des notebooks (si les notebooks ont été analysés)
Le nombre de fichiers contenant des requêtes SQL intégrées
Que faut-il surveiller ?
Le nombre et le contenu des fichiers. Lorsque vous trouvez de nombreux fichiers mais que seuls quelques-uns contiennent des références Spark API, cela peut signifier ce qui suit :
L’application utilise très peu Spark (peut-être uniquement pour le chargement et l’extraction des données)
Le code source comprend des dépendances de bibliothèques externes
Le cas d’utilisation doit être approfondi pour comprendre comment Spark est utilisé
Dans un cas comme dans l’autre, il est important d’analyser en profondeur le cas d’utilisation avant d’aller de l’avant.
Résumé de l’utilisation de Spark¶
Le résumé de l’utilisation de Spark fournit une ventilation détaillée des références Spark API trouvées dans votre code et identifie celles qui peuvent être converties en Snowpark API. Le résumé classe ces références en différents types, notamment les opérations DataFrame, les manipulations de colonnes, les appels SparkSession et d’autres fonctions API.
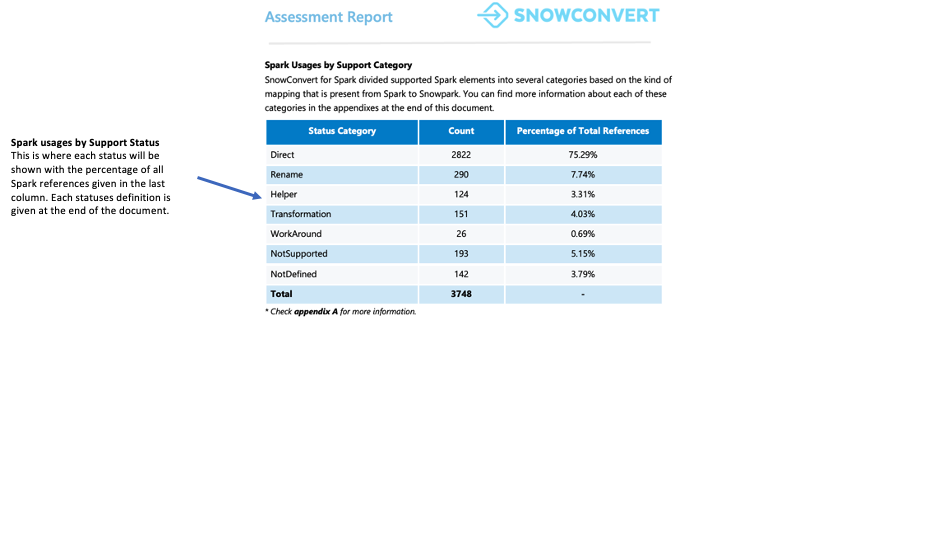
Chaque référence est classée dans l’un des sept statuts de prise en charge. Ces statuts indiquent si et comment une référence peut être prise en charge dans Snowpark. Les définitions détaillées de ces statuts se trouvent dans les annexes du rapport.
Direct : La fonction existe à la fois dans PySpark et dans Snowpark et peut être utilisée sans changement.
Renommer : La fonction existe dans les deux frameworks, mais nécessite un changement de nom dans Snowpark.
Assistant : La fonction nécessite une petite modification dans Snowpark qui peut être résolue par la création d’une fonction d’assistance équivalente.
Transformation : La fonction doit être entièrement reconstruite dans Snowpark en utilisant différentes méthodes ou plusieurs étapes pour obtenir le même résultat.
Solution de contournement : La fonction ne peut pas être convertie automatiquement, mais il existe une solution manuelle documentée.
NotSupported : La fonction ne peut pas être convertie car Snowflake n’a pas de fonction équivalente. L’outil ajoutera un message d’erreur au code.
NotDefined : L’élément PySpark n’est pas encore inclus dans la base de données de l’outil de conversion et sera ajouté dans une prochaine mise à jour.
Que faut-il surveiller ?
Le score de préparation est affiché dans cette section. Vous pouvez examiner le nombre de références de code qui nécessiteront des solutions de contournement plutôt que des traductions directes. Si votre code nécessite de nombreuses solutions contournements, assistants et transformations, nous vous recommandons d’utiliser Snowpark Migration Accelerator (SMA) pour vous aider à migrer efficacement votre base de code.
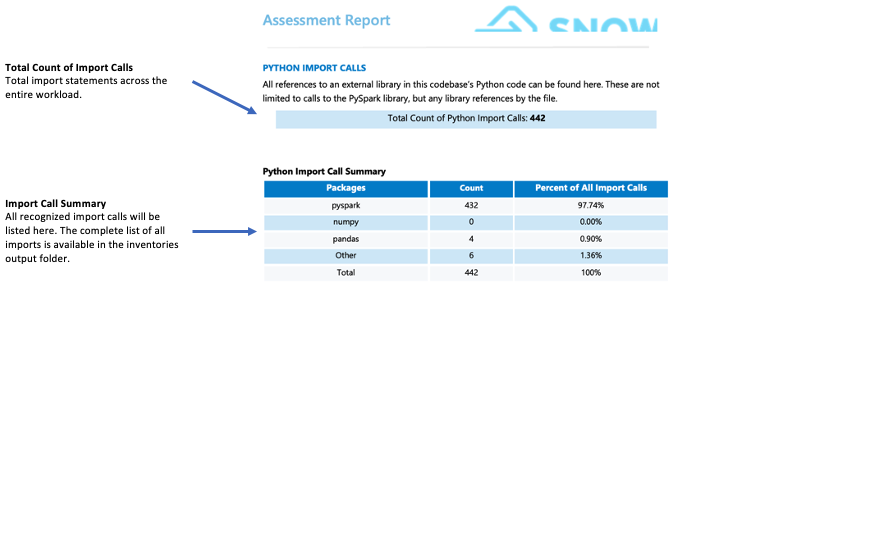
Appels d’importation :¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
Que faut-il surveiller ?
Les bibliothèques tierces non prise en charge par Snowflake peuvent avoir un impact significatif sur votre préparation à la migration. Si votre code importe des bibliothèques comme des bibliothèques mllib, de diffusion ou tierces comme les graphiques, les sous-processus ou smtplib, vous pouvez être confronté à des problèmes de migration. Si la présence de ces bibliothèques ne rend pas automatiquement la migration impossible, elle nécessite une analyse plus approfondie de votre cas d’utilisation. Dans de telles situations, nous vous recommandons de contacter l’équipe WLS pour une évaluation détaillée.
Résumé des problèmes relatifs à Snowpark Migration Accelerator¶
Cette section donne un aperçu des problèmes et des erreurs qui peuvent survenir lors de la migration de la charge de travail. Bien que des informations détaillées sur les éléments non convertibles soient disponibles ailleurs, cette section est particulièrement utile lors des premières étapes du processus de conversion.
Problèmes courants à surveiller
Pour trouver des éléments qui n’ont pas été convertis ou qui ont des solutions de contournement connues, consultez l’inventaire de référence de Spark dans votre dossier d’inventaires local. Vous pouvez comparer ces éléments avec les mappages existants en interrogeant la base de données.

Résumé :¶
Le score de préparation indique dans quelle mesure votre base de code est prête pour la migration vers Snowpark. Un score de 80 % ou plus signifie que votre code est en grande partie prêt pour la migration. Si votre score est inférieur à 60 %, vous devrez apporter des modifications supplémentaires à votre code avant de poursuivre.
Pour cette charge de travail, le score dépasse 90 %, ce qui indique une excellente compatibilité pour la migration.
L’indicateur suivant est la taille. Une charge de travail avec un code étendu mais avec peu de références Spark API pourrait suggérer une forte dépendance aux bibliothèques tierces. Même si un projet a un faible score de préparation, il peut être rapidement converti manuellement s’il ne contient qu’une centaine de lignes de code ou 5 références Spark API, quels que soient les outils d’automatisation.
Pour cette charge de travail, la taille est raisonnable et facile à manipuler. La base de code contient plus de 100 fichiers avec moins de 5 000 références Spark API et moins de 10 000 lignes de code. Environ 98 % de ces fichiers contiennent des références Spark API, ce qui indique que la majeure partie du code Python est liée à Spark.
Le troisième indicateur à examiner concerne les bibliothèques importées. L’inventaire des instructions d’importation permet d’identifier les paquets externes utilisés par le code. Si le code s’appuie fortement sur des bibliothèques tierces, il peut nécessiter une analyse supplémentaire. Dans les cas où il existe de nombreuses dépendances externes, contactez l’équipe des services de charge de travail (WLS) pour mieux comprendre comment ces bibliothèques sont utilisées.
Dans cet exemple, nous avons quelques bibliothèques tierces référencées, mais aucune d’entre elles n’est liée au machine learning, au Streaming, ou à d’autres bibliothèques complexes dont l’implémentation dans Snowpark représenterait un défi.
Puisque cette charge de travail est adaptée à la migration vers Snowpark, passez à l’étape suivante du processus de migration Spark.