Snowpark Migration Accelerator: 평가 출력 - 보고서 폴더¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we’ll examine some key .csv files to understand the migration requirements, we won’t cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
보고서를 보려면 화면 하단의 “VIEW REPORTS” 버튼을 클릭합니다. 그러면 파일 탐색기가 보고서가 포함된 디렉터리로 열립니다.
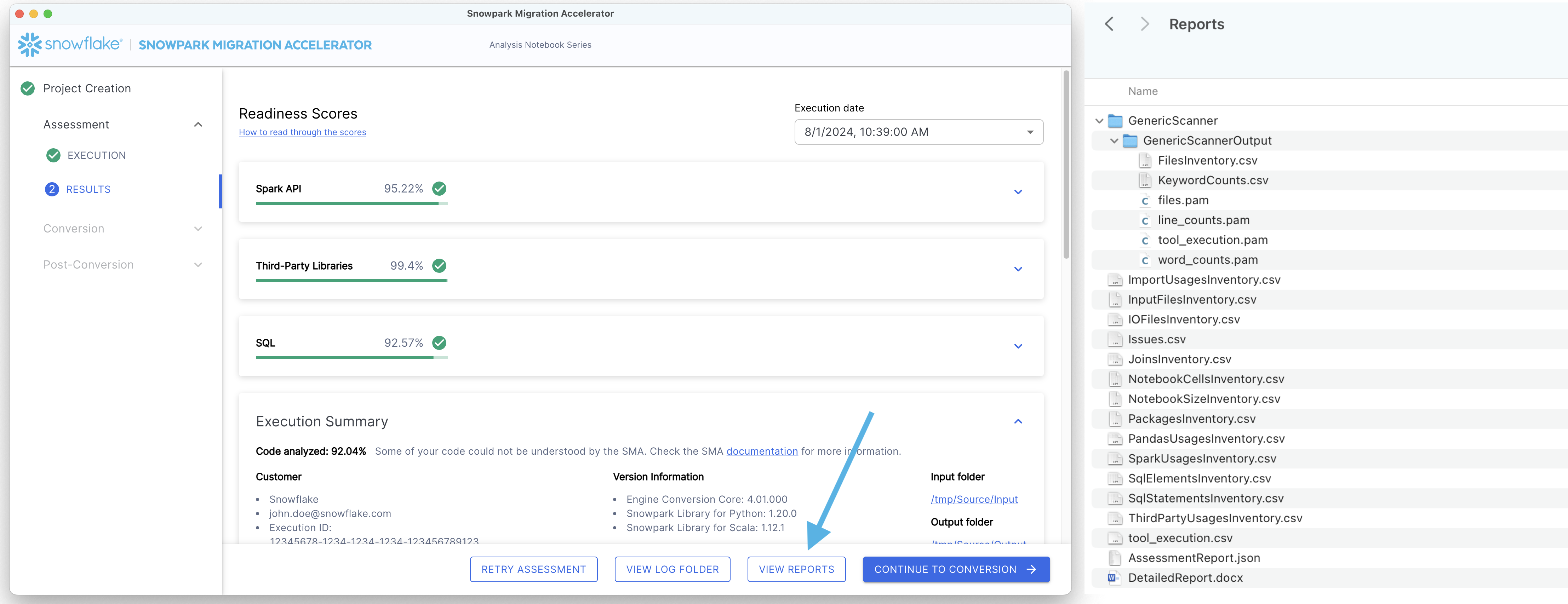
상세 보고서에서 어떤 정보를 수집할 수 있는지 살펴보겠습니다.
참고
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
상세 보고서¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report’s contents is available in the detailed documentation, this guide focuses on three key aspects:
검토해야 할 중요 요소
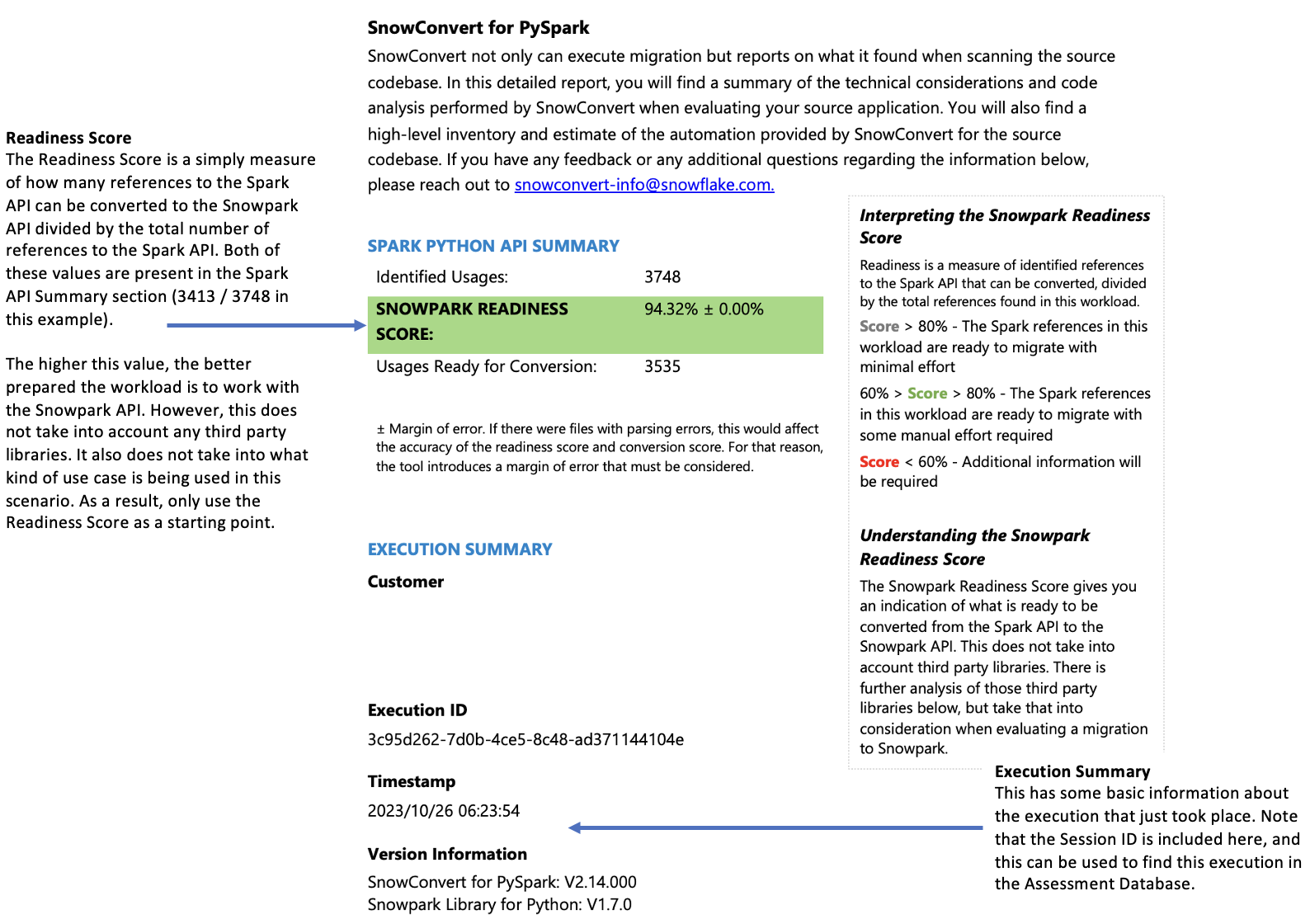
준비도 점수에 미치는 영향
결과 해석 방법
보고서에서 사용 가능한 모든 준비도 점수를 검토하여 마이그레이션 준비 상태를 파악하십시오.
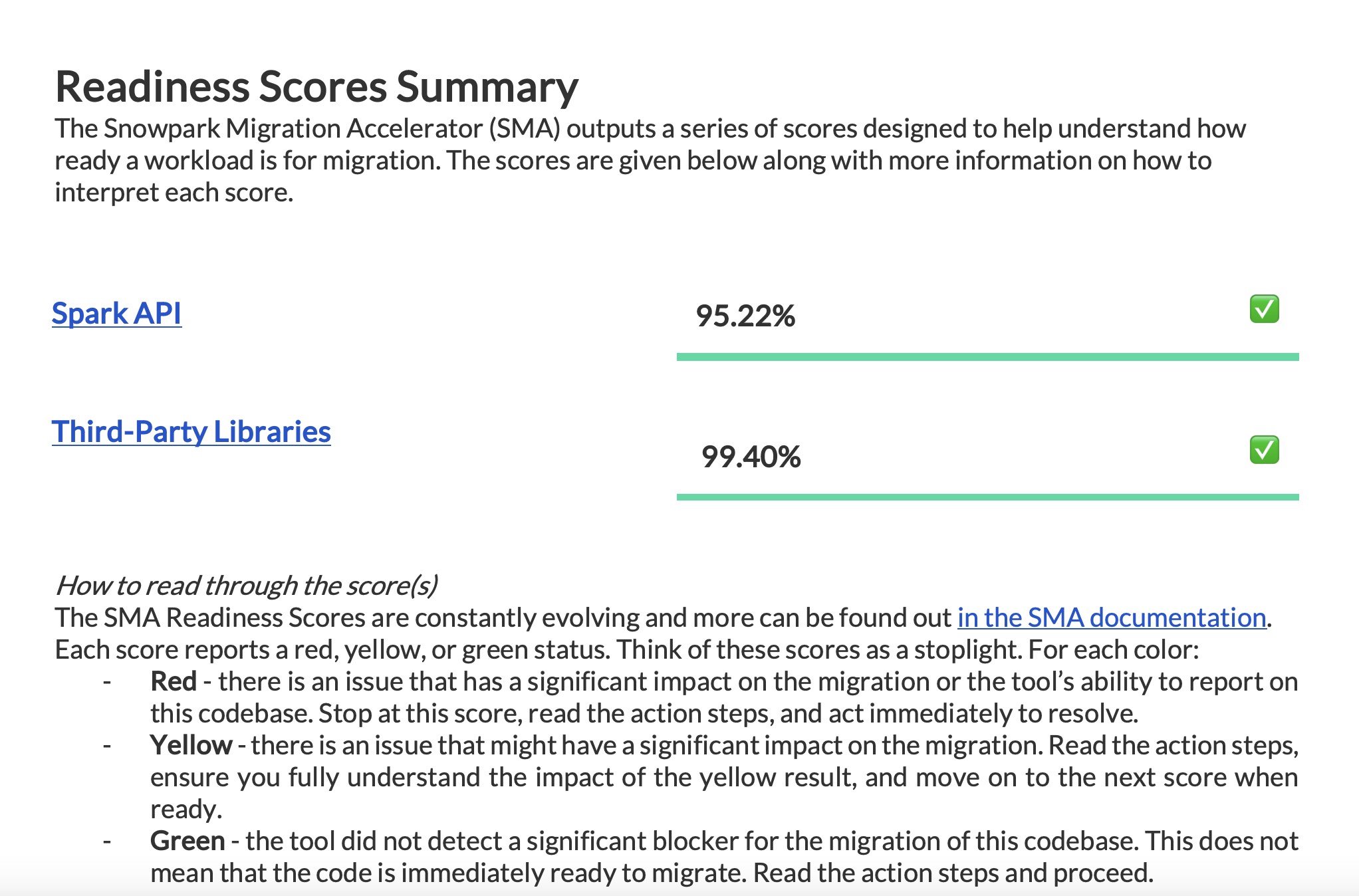
The Spark API 준비도 점수¶
Let’s clarify what the Spark API Readiness score means and how it’s calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It’s important to note that this score only considers Spark API usage and doesn’t account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
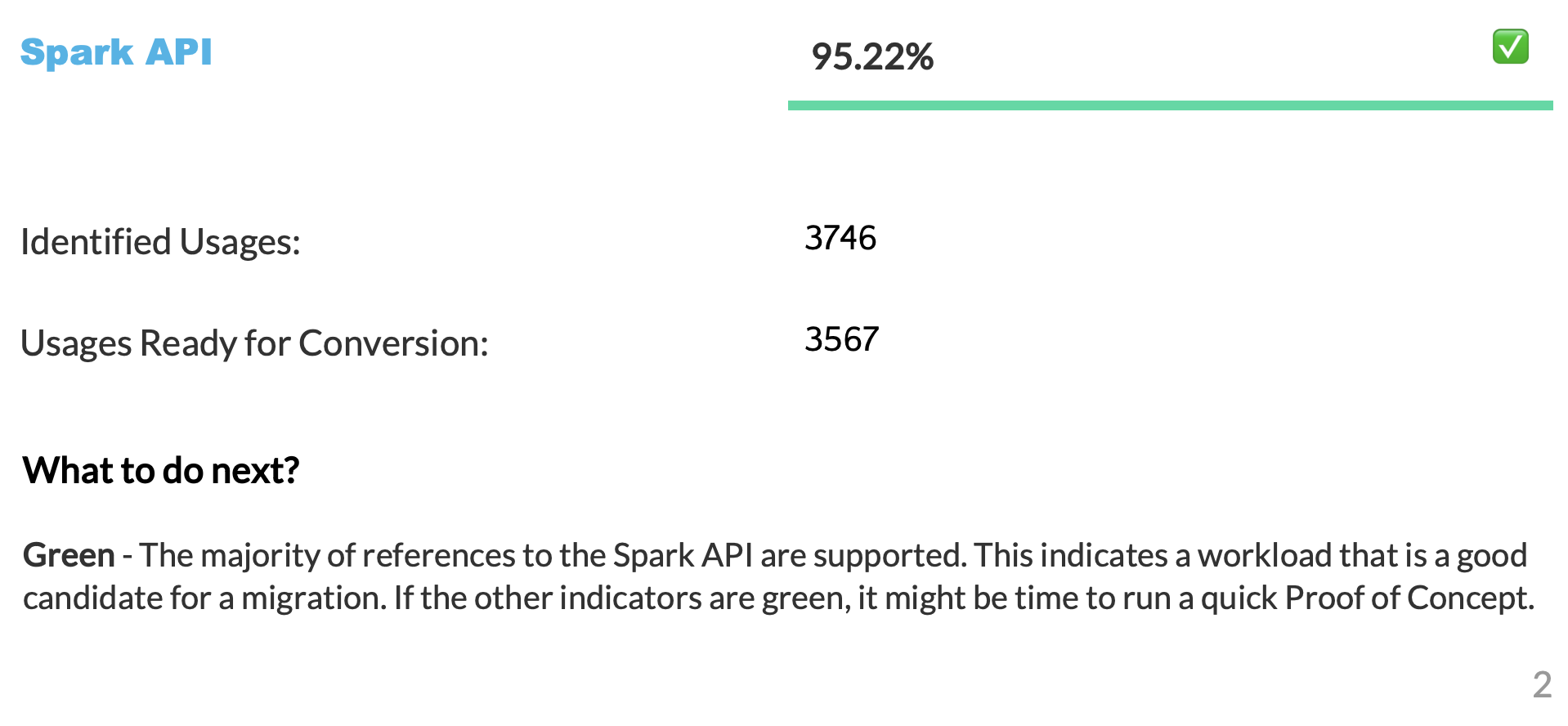
변환 점수는 코드에서 발견된 총 Spark API 참조 수와 비교하여 자동으로 Snowpark API 로 변환될 수 있는 Spark API 참조의 비율을 나타냅니다. 이 경우 3,746개의 참조 중 3,541개의 참조를 변환할 수 있습니다. 점수가 높을수록 더 많은 코드를 Snowpark로 자동 마이그레이션할 수 있음을 의미합니다. 변환되지 않은 코드는 여전히 Snowpark에서 작동하도록 수동으로 조정할 수 있지만, 이 점수는 워크로드가 자동 마이그레이션에 얼마나 적합한지 신뢰할 수 있는 메트릭을 제공합니다.
서드 파티 라이브러리 준비도 점수¶
서드 파티 라이브러리 준비도 점수는 코드에서 어떤 외부 APIs 가 사용되는지 파악하는 데 도움이 됩니다. 이 점수는 코드베이스의 모든 외부 종속성에 대한 명확한 개요를 제공합니다.
요약 페이지¶
요약 페이지에는 준비도 점수가 표시되고 실행 결과에 대한 개요가 제공됩니다.
검색할 대상 준비도 점수를 확인하여 코드베이스가 Spark API 참조를 Snowpark API 참조로 변환할 준비가 얼마나 되어 있는지 평가하십시오. 준비도 점수가 높으면 Spark 코드가 Snowpark로의 마이그레이션에 적합하다는 뜻입니다.
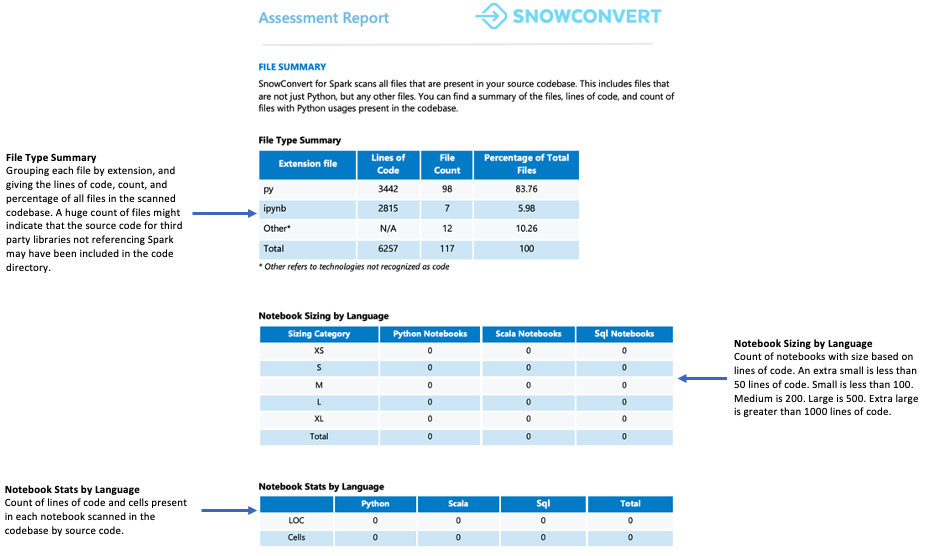
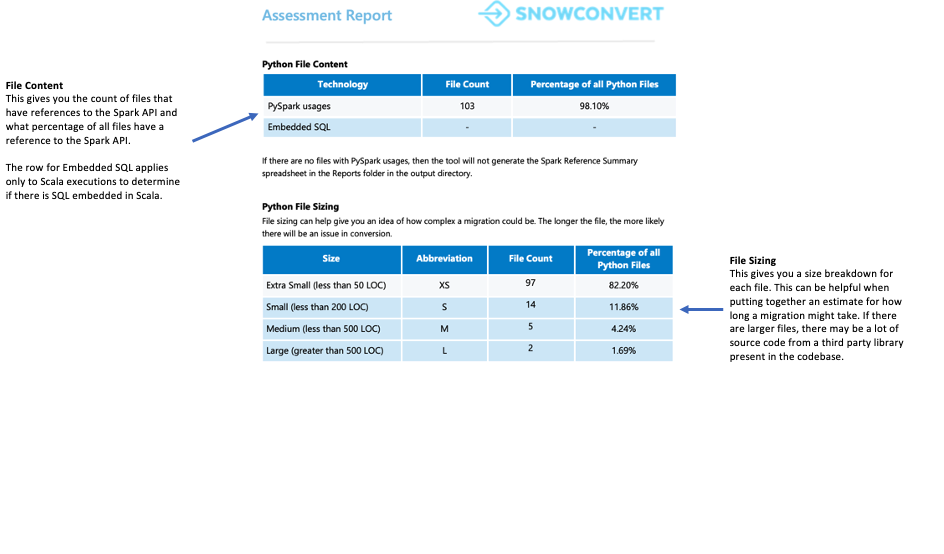
파일 요약¶
파일 요약은 다음을 포함하여 코드베이스에 대한 개요를 제공합니다.
파일 확장자당 총 코드 줄 수
노트북 셀 정보(노트북이 분석된 경우)
임베드된 SQL 쿼리가 포함된 파일 수
무엇을 주의해야 하나요?
파일의 수와 내용입니다. 많은 파일을 찾았지만 Spark API 참조가 포함된 파일이 몇 개만 있는 경우 이는 다음과 같은 의미일 수 있습니다.
애플리케이션은 Spark를 최소한으로 사용합니다(아마도 데이터 추출 및 로딩에만 사용할 수 있음)
소스 코드에는 외부 라이브러리 종속성이 포함됩니다
사용 사례는 Spark가 어떻게 활용되고 있는지 이해하려면 추가 조사가 필요합니다
두 시나리오 모두 진행하기 전에 사용 사례를 철저히 분석하는 것이 중요합니다.
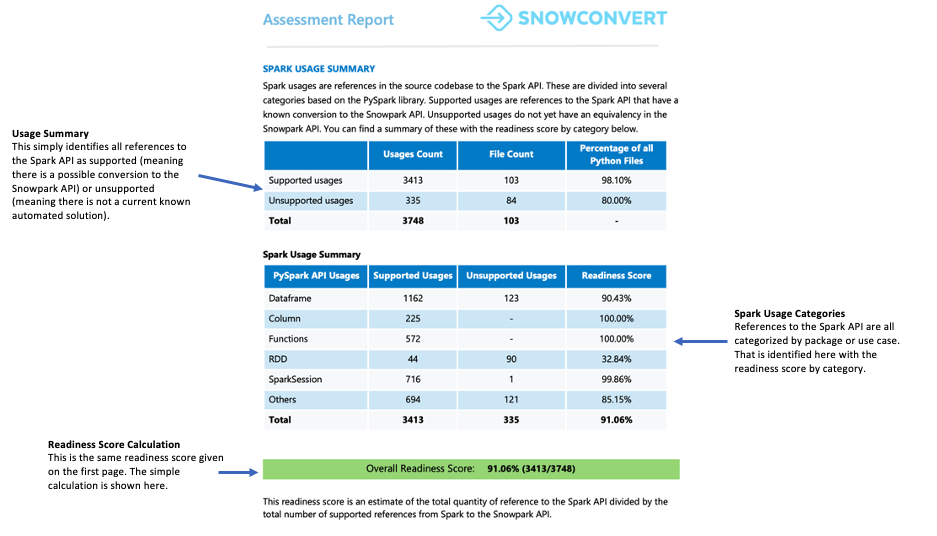
Spark 사용 요약¶
Spark 사용 요약은 코드에 있는 Spark API 참조에 대한 자세한 분석을 제공하고 어떤 참조를 Snowpark API 로 변환할 수 있는지 식별합니다. 이 요약에서는 이러한 참조를 DataFrame 작업, 열 조작, SparkSession 호출 및 기타 API 함수를 포함한 다양한 유형으로 분류합니다.
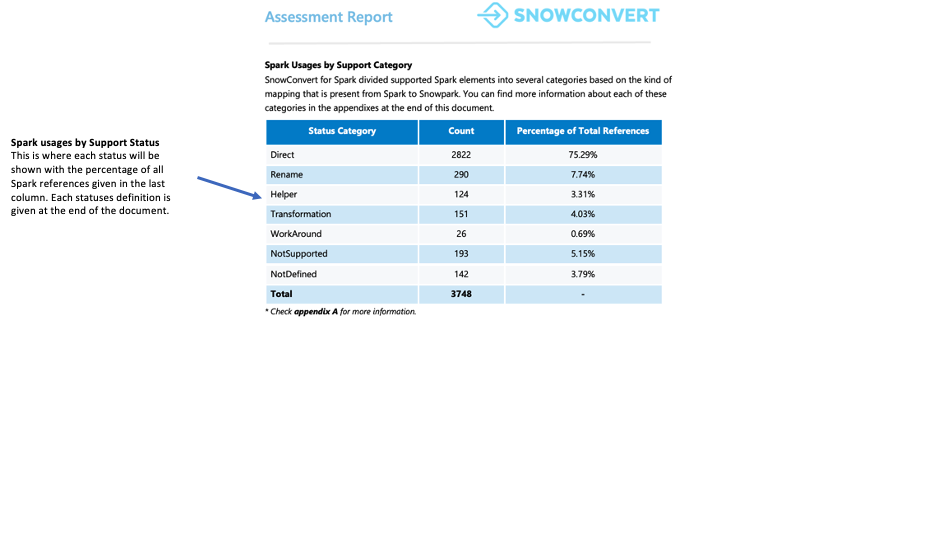
각 참조는 7가지 지원 상태 중 하나로 분류됩니다. 이러한 상태는 참조가 Snowpark에서 지원될 수 있는지 여부와 지원 방법을 나타냅니다. 이러한 상태에 대한 자세한 정의는 보고서의 부록에서 확인할 수 있습니다.
Direct: 이 함수는 PySpark 및 Snowpark에 모두 있으며 변경 없이 사용할 수 있습니다.
Rename: 이 함수는 두 프레임워크에 모두 존재하지만 Snowpark에서 이름을 변경해야 합니다.
Helper: 이 함수는 Snowpark에서 약간의 수정이 필요한데, 이는 동등한 도우미 함수를 만들어서 해결할 수 있습니다.
Transformation: 동일한 결과를 얻으려면 다른 방법 또는 여러 단계를 사용하여 함수를 Snowpark에서 완전히 다시 빌드해야 합니다.
Workaround: 이 함수는 자동으로 변환할 수 없지만 문서화된 수동 해결 방법을 사용할 수 있습니다.
NotSupported: 해당 함수를 변환할 수 없는 이유는 Snowflake에 해당 함수가 없기 때문입니다. 이 도구는 코드에 오류 메시지를 추가합니다.
NotDefined: PySpark 요소는 아직 변환 도구의 데이터베이스에 포함되어 있지 않으며 향후 업데이트에서 추가될 예정입니다.
무엇을 주의해야 하나요?
이 섹션에는 준비도 점수가 표시됩니다. 직접 변환과 비교하여 얼마나 많은 코드 참조에 해결 방법이 필요한지 검토할 수 있습니다. 코드에 많은 해결 방법, 도우미 및 변환이 필요한 경우 코드베이스를 효율적으로 마이그레이션하는 데 도움이 되는 Snowpark Migration Accelerator(SMA)를 사용하는 것이 좋습니다.
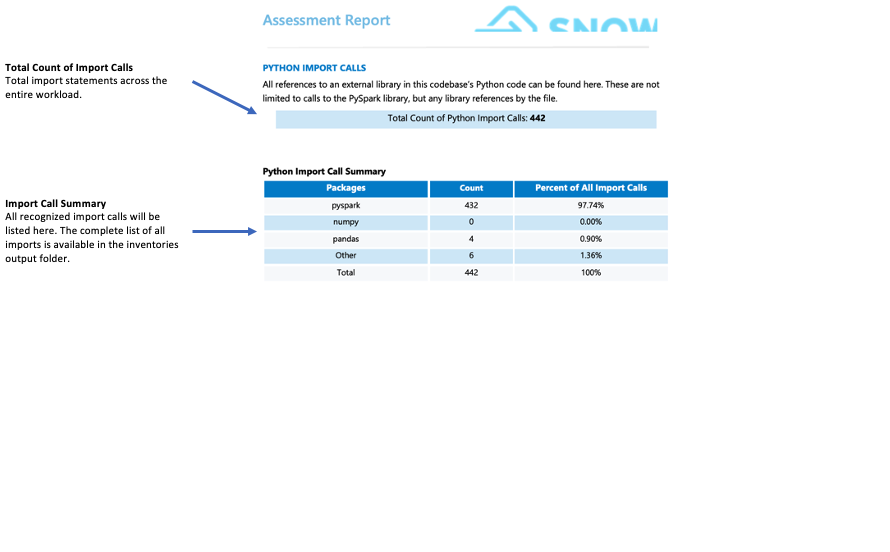
호출 가져오기:¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
무엇을 주의해야 하나요?
Snowflake에서 지원하지 않는 서드 파티 라이브러리는 마이그레이션 준비에 상당한 영향을 미칠 수 있습니다. 코드에서 mllib, 스트림 또는 그래프, 서브프로세스 또는 smtplib와 같은 서드 파티 라이브러리를 가져오는 경우 마이그레이션 문제가 발생할 수 있습니다. 이러한 라이브러리가 있다고 해서 마이그레이션이 자동으로 불가능해지는 것은 아니지만, 사용 사례에 대한 심층적인 분석이 필요합니다. 이러한 상황에서는 WLS 팀에 문의하여 자세한 평가를 받는 것이 좋습니다.
Snowpark Migration Accelerator 문제 요약¶
이 섹션에서는 워크로드 마이그레이션 중에 발생할 수 있는 잠재적인 문제와 오류에 대한 개요를 제공합니다. 변환할 수 없는 요소에 대한 자세한 정보는 다른 곳에서 확인할 수 있지만, 이 섹션은 변환 프로세스의 초기 단계에서 특히 유용합니다.
주의해야 할 일반적인 문제
변환되지 않았거나 알려진 해결 방법이 있는 요소를 찾으려면 로컬 인벤토리 폴더에서 Spark 참조 인벤토리를 확인하십시오. 데이터베이스 쿼리를 통해 이러한 요소를 기존 매핑과 비교할 수 있습니다.

요약:¶
준비도 점수는 코드베이스가 Snowpark 마이그레이션에 얼마나 준비되었는지를 나타냅니다. 80% 이상의 점수는 대부분의 코드가 마이그레이션할 준비가 되었다는 의미입니다. 점수가 60% 미만인 경우 계속 진행하기 전에 코드를 추가로 수정해야 합니다.
이 워크로드의 경우 점수가 90%를 초과하여 마이그레이션에 대한 호환성이 우수함을 나타냅니다.
다음 지표는 크기 입니다. 코드가 광범위하지만 Spark API 참조가 거의 없는 워크로드는 서드 파티 라이브러리에 대한 의존도가 높다는 의미일 수 있습니다. 프로젝트의 준비도 점수가 낮더라도 100줄 정도의 코드 또는 5개의 Spark API 참조만 포함되어 있으면 자동화 도구에 관계없이 빠르게 수동으로 변환할 수 있습니다.
이 워크로드의 경우 크기가 적당하고 다루기 쉽습니다. 코드베이스에는 5,000개 미만의 Spark API 참조와 10,000줄 미만의 코드가 포함된 100개 이상의 파일이 포함되어 있습니다. 이러한 파일의 약 98%는 Spark API 참조를 포함하고 있으며, 이는 대부분의 Python 코드가 Spark와 관련이 있음을 나타냅니다.
세 번째로 살펴볼 지표는 가져온 라이브러리 입니다. 가져오기 문의 인벤토리는 코드가 사용하는 외부 패키지를 식별하는 데 도움이 됩니다. 코드가 서드 파티 라이브러리에 크게 의존하는 경우 추가 분석이 필요할 수 있습니다. 외부 종속성이 많은 경우에는 워크로드 서비스(WLS) 팀에 문의하여 이러한 라이브러리가 어떻게 사용되고 있는지 파악하십시오.
이 예제에서는 서드 파티 라이브러리를 참조했지만 머신 러닝, 스트림 또는 Snowpark에서 구현하기 어려운 기타 복잡한 라이브러리와 관련된 라이브러리는 없습니다.
이 워크로드는 Snowpark로의 마이그레이션에 적합하므로 다음 단계인 Spark 마이그레이션 프로세스를 진행하십시오.