- description:
What to do with all of this assessment information?
Snowpark Migration Accelerator: Assessment Output - Reports Folder¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we’ll examine some key .csv files to understand the migration requirements, we won’t cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
To view the reports, click the “VIEW REPORTS” button at the bottom of the screen. This will open your file explorer to the directory containing the reports.
Let’s examine what information we can gather from the Detailed Report.
Note
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
The Detailed Report¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report’s contents is available in the detailed documentation, this guide focuses on three key aspects:
- Important elements to review
- Their impact on readiness scores
- How to interpret the results
Review all readiness scores available in your report to understand your migration readiness status.
.png)
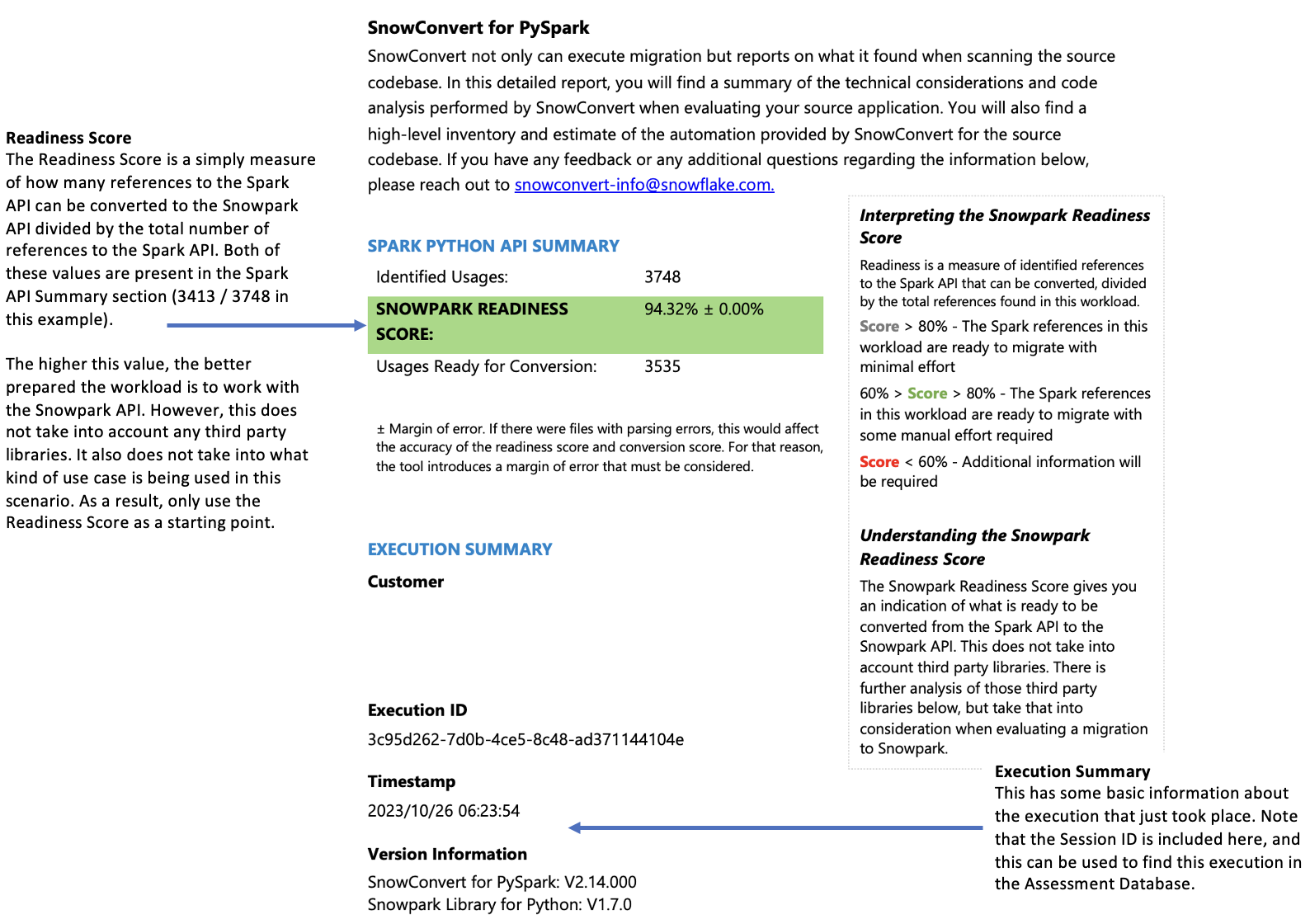
The Spark API Readiness Score¶
Let’s clarify what the Spark API Readiness score means and how it’s calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It’s important to note that this score only considers Spark API usage and doesn’t account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
.png)
The Conversion Score represents the ratio of Spark API references that can be automatically converted to Snowpark API, compared to the total number of Spark API references found in your code. In this case, 3541 out of 3746 references can be converted. A higher score indicates that more of your code can be automatically migrated to Snowpark. While unconverted code can still be manually adapted to work with Snowpark, this score provides a reliable indication of how well-suited your workload is for automatic migration.
Third Party Libraries Readiness Score¶
The Third Party Libraries Readiness Score helps you understand which external APIs are used in your code. This score provides a clear overview of all external dependencies in your codebase.
Summary Page¶
The Summary page displays your readiness score and provides an overview of your execution results.
What to Look For Check the readiness score to evaluate how prepared your codebase is for converting Spark API references to Snowpark API references. A high readiness score indicates that the Spark code is well-suited for migration to Snowpark.
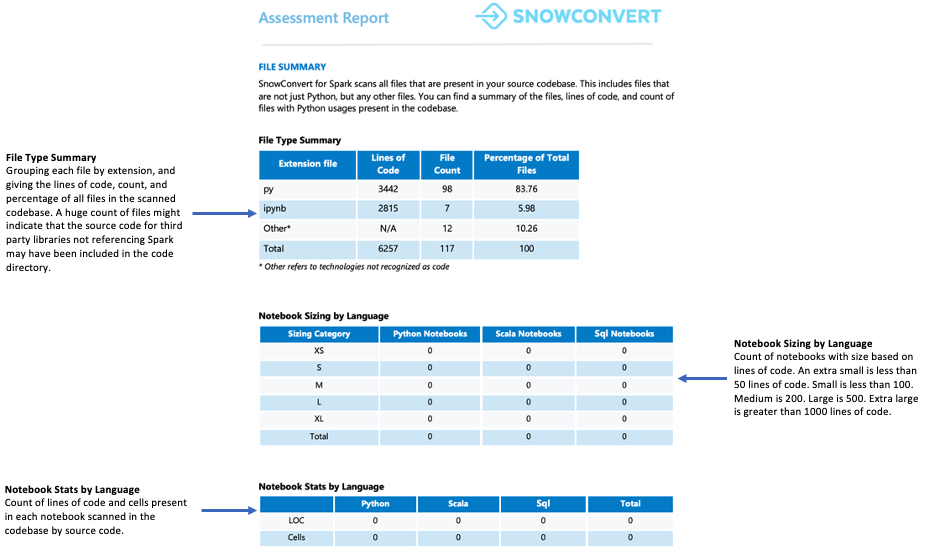
File Summary¶
The file summary provides an overview of your codebase, including:
- Total lines of code per file extension
- Notebook cell information (if notebooks were analyzed)
- Number of files containing embedded SQL queries
What Should You Watch For?
The number and content of files. When you find many files but only a few contain Spark API references, this could mean:
- The application uses Spark minimally (perhaps only for data extraction and loading)
- The source code includes external library dependencies
- The use case needs further investigation to understand how Spark is being utilized
In either scenario, it’s important to thoroughly analyze the use case before proceeding.
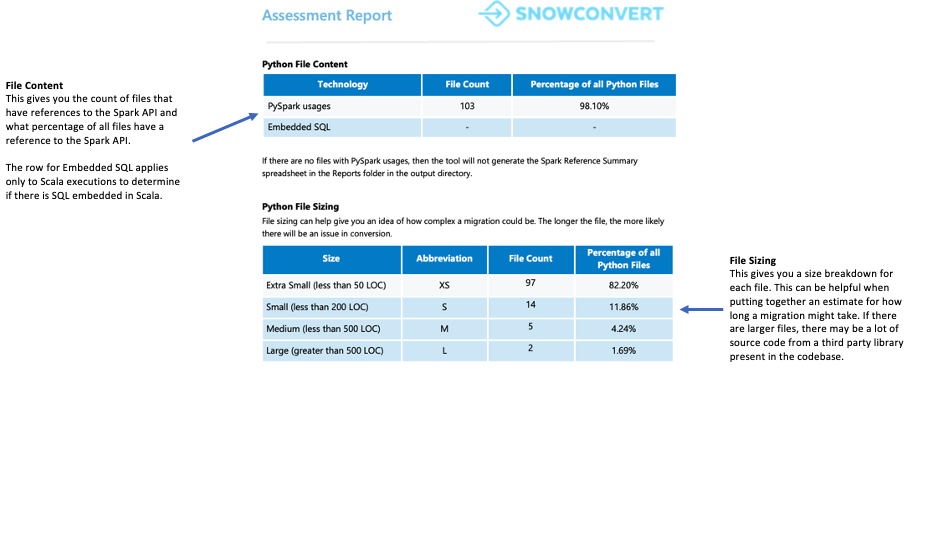
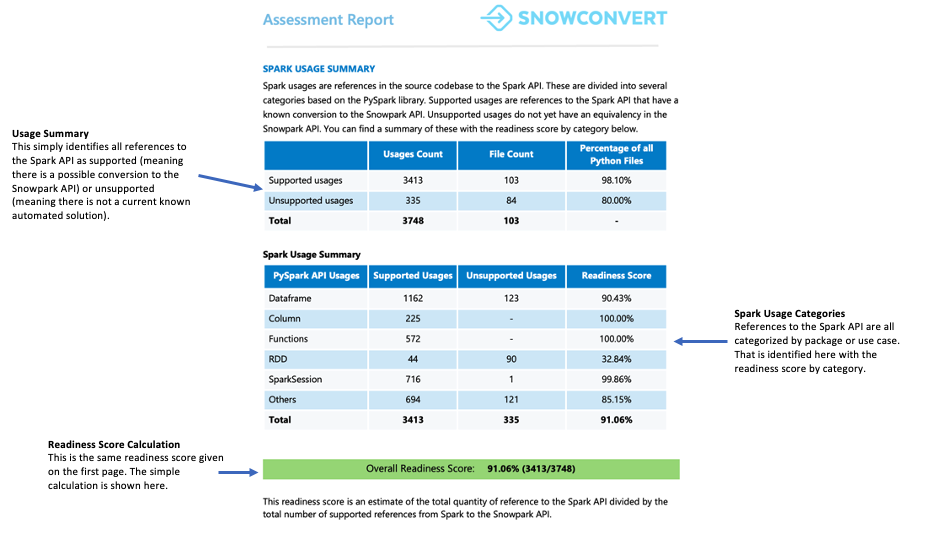
Spark Usage Summary¶
The Spark Usage Summary provides a detailed breakdown of Spark API references found in your code and identifies which ones can be converted to the Snowpark API. The summary categorizes these references into different types, including DataFrame operations, column manipulations, SparkSession calls, and other API functions.
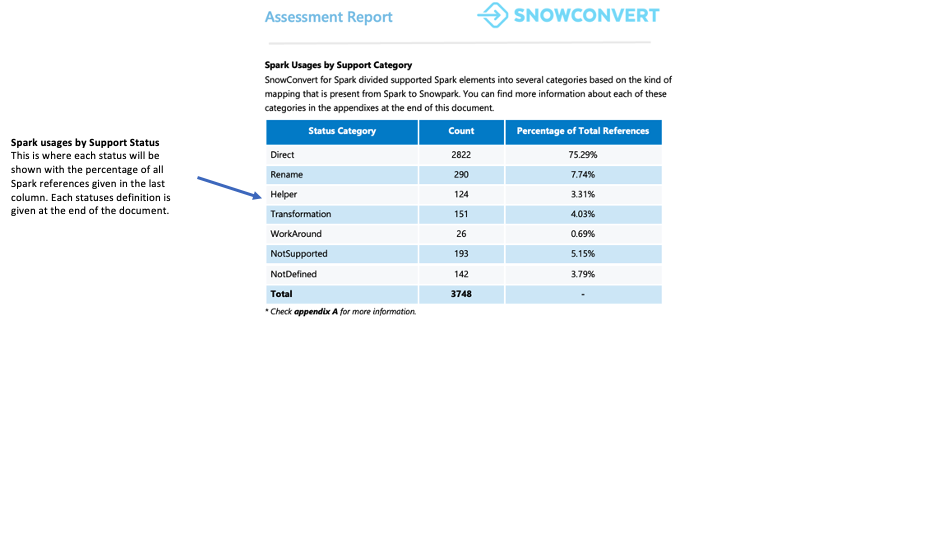
Each reference is classified into one of seven support statuses. These statuses indicate whether and how a reference can be supported in Snowpark. The detailed definitions of these statuses can be found in the report’s appendixes.
- Direct: The function exists in both PySpark and Snowpark and can be used without changes.
- Rename: The function exists in both frameworks, but requires a name change in Snowpark.
- Helper: The function requires a small modification in Snowpark that can be solved by creating an equivalent helper function.
- Transformation: The function needs to be completely rebuilt in Snowpark using different methods or multiple steps to achieve the same result.
- Workaround: The function cannot be automatically converted, but there is a documented manual solution available.
- NotSupported: The function cannot be converted because Snowflake does not have an equivalent feature. The tool will add an error message to the code.
- NotDefined: The PySpark element is not yet included in the conversion tool’s database and will be added in a future update.
What Should You Watch For?
The readiness score is displayed in this section. You can review how many code references will need workarounds versus direct translations. If your code requires many workarounds, helpers, and transformations, we recommend using Snowpark Migration Accelerator (SMA) to help migrate your codebase efficiently.
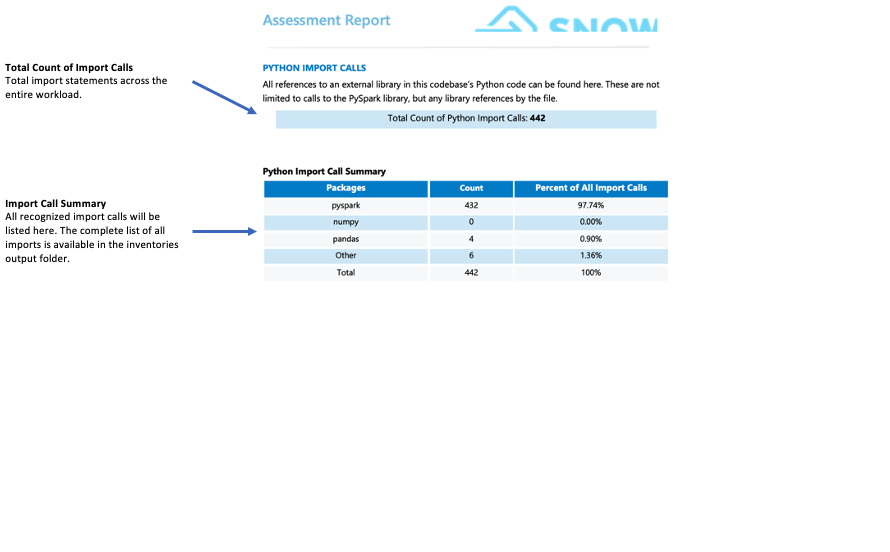
Import Calls:¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
What Should You Watch For?
Third-party libraries not supported by Snowflake can significantly impact your migration readiness. If your code imports libraries like mllib, streaming, or third-party libraries such as graphs, subprocess, or smtplib, you may face migration challenges. While the presence of these libraries doesn’t automatically make migration impossible, it requires a deeper analysis of your use case. In such situations, we recommend consulting with the WLS team for a detailed assessment.
Snowpark Migration Accelerator Issue Summary¶
This section provides an overview of potential issues and errors that may occur during workload migration. While detailed information about unconvertible elements is available elsewhere, this section is particularly valuable during the initial stages of the conversion process.
Common Issues to Watch For
To find elements that were not converted or have known workarounds, check the Spark reference inventory in your local inventories folder. You can compare these elements with existing mappings by querying the database.

Summary:¶
The readiness score indicates how prepared your codebase is for Snowpark migration. A score of 80% or higher means your code is mostly ready for migration. If your score is below 60%, you will need to make additional modifications to your code before proceeding.
For this workload, the score exceeds 90%, which indicates excellent compatibility for migration.
The next indicator is size. A workload with extensive code but few Spark API references might suggest heavy reliance on third-party libraries. Even if a project has a low readiness score, it can be quickly converted manually if it contains only about 100 lines of code or 5 Spark API references, regardless of automation tools.
For this workload, the size is reasonable and easy to handle. The codebase contains more than 100 files with fewer than 5,000 Spark API references and under 10,000 lines of code. Approximately 98% of these files contain Spark API references, indicating that most of the Python code is Spark-related.
The third indicator to examine is imported libraries. The inventory of import statements helps identify which external packages the code uses. If the code relies heavily on third-party libraries, it may require additional analysis. In cases with numerous external dependencies, consult the Workload Services (WLS) team to better understand how these libraries are being used.
In this example, we have some referenced third-party libraries, but none of them are related to Machine Learning, Streaming, or other complex libraries that would be challenging to implement in Snowpark.
Since this workload is suitable for migration to Snowpark, proceed to the next step in the Spark migration process.