Snowpark Migration Accelerator: Bewertungsergebnisse - Berichtsordner¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we’ll examine some key .csv files to understand the migration requirements, we won’t cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
Um die Berichte anzuzeigen, klicken Sie auf die Schaltfläche „VIEW REPORTS“ am unteren Rand des Bildschirms. Dies öffnet Ihren Datei-Explorer zum Verzeichnis, das die Berichte enthält.
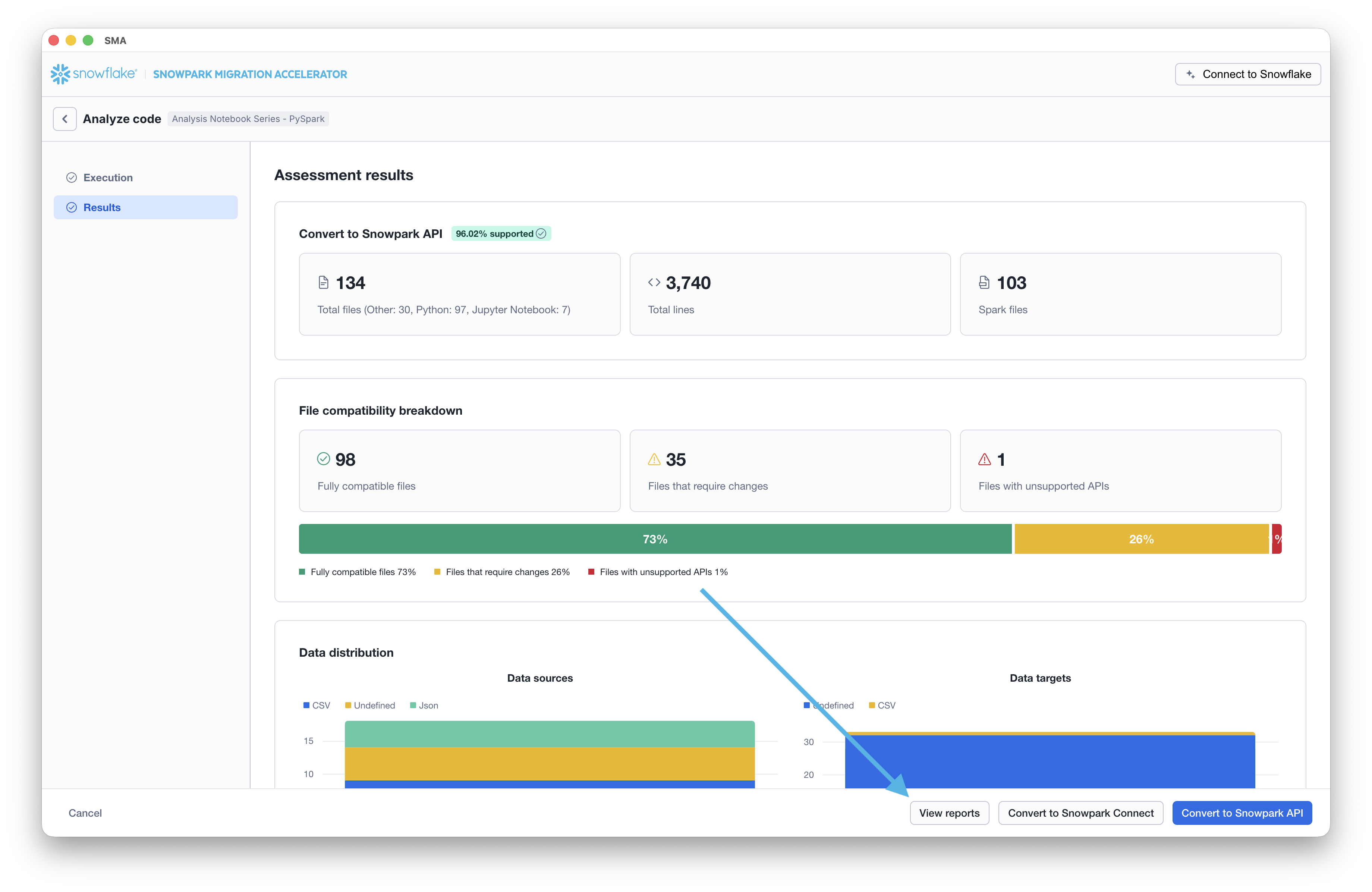
Lassen Sie uns untersuchen, welche Informationen wir aus dem detaillierten Bericht entnehmen können.
Bemerkung
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
Der detaillierte Bericht¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report’s contents is available in the detailed documentation, this guide focuses on three key aspects:
Wichtige Elemente zur Überprüfung
Ihr Einfluss auf die Bereitschaftsbewertungen
Wie Sie die Ergebnisse interpretieren
Prüfen Sie alle in Ihrem Bericht verfügbaren Werte für die Migrationsbereitschaft, um den Status Ihrer Migrationsbereitschaft zu verstehen.
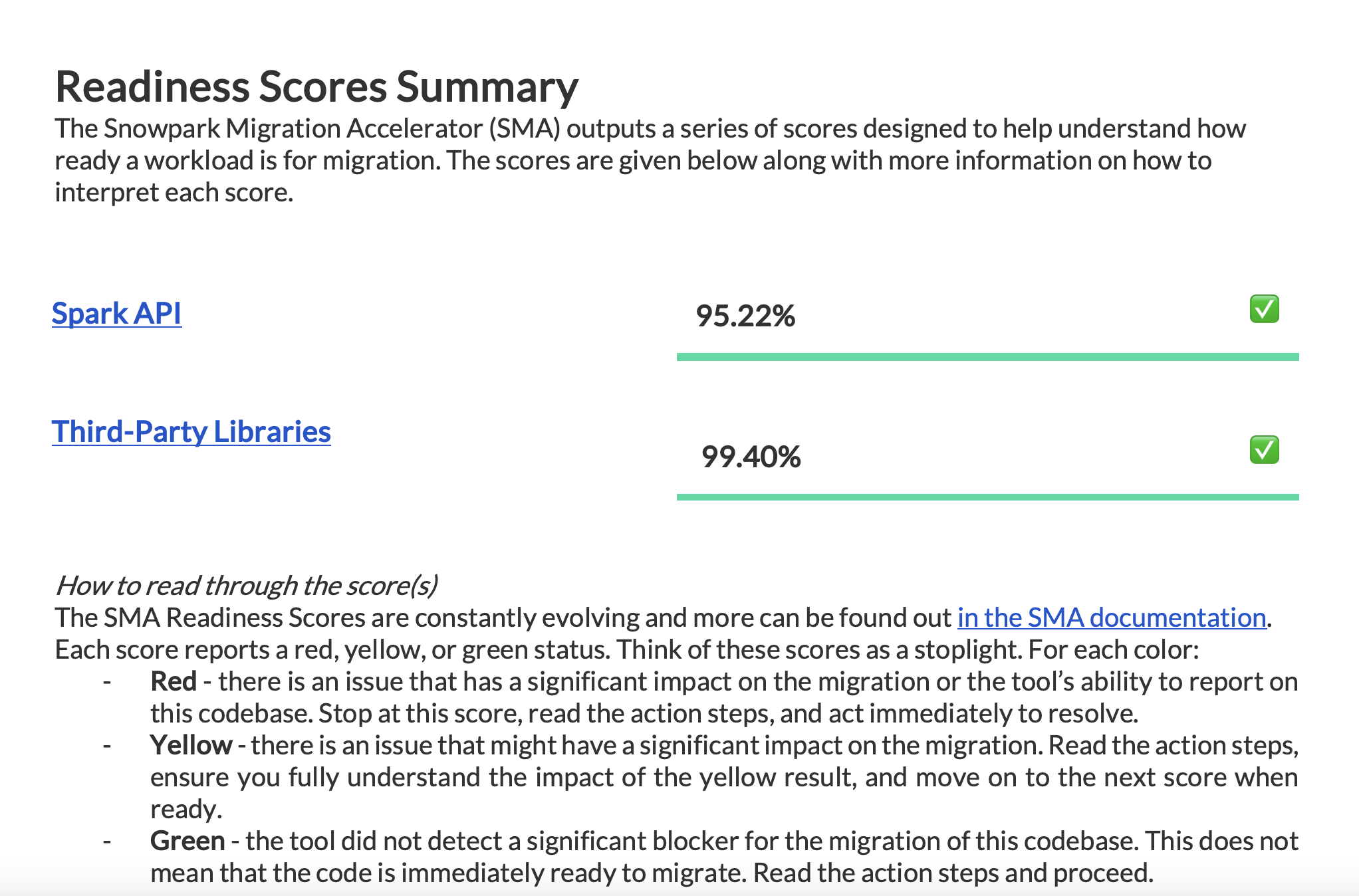
Die Spark API-Bereitschaftsbewertung¶
Let’s clarify what the Spark API Readiness score means and how it’s calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It’s important to note that this score only considers Spark API usage and doesn’t account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
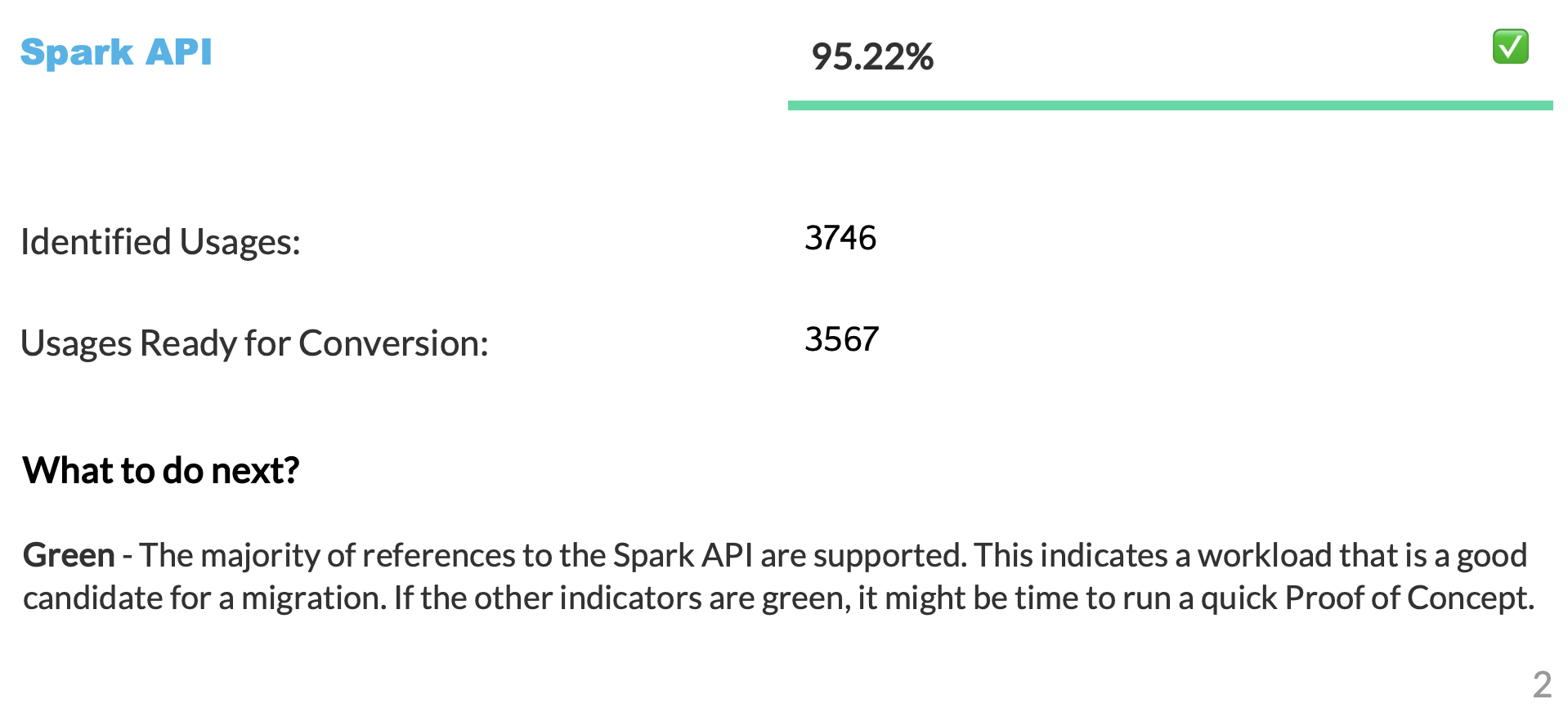
Die Konvertierungsbewertugn stellt das Verhältnis der Spark API-Referenzen, die automatisch in Snowpark API konvertiert werden können, im Vergleich zur Gesamtzahl der Spark API-Referenzen in Ihrem Code dar. In diesem Fall können 3541 von 3746 Referenzen umgewandelt werden. Eine höhere Bewertung bedeutet, dass ein größerer Teil Ihres Codes automatisch nach Snowpark migriert werden kann. Nicht konvertierter Code kann zwar immer noch manuell an Snowpark angepasst werden, aber diese Bewertung gibt einen zuverlässigen Hinweis darauf, wie gut Ihr Workload für eine automatische Migration geeignet ist.
Drittanbieter-Bibliotheken-Bereitschaftsbewertung¶
Die Drittanbieter-Bibliotheken-Bereitschaftsbewertung hilft Ihnen zu verstehen, welche externen APIs in Ihrem Code verwendet werden. Diese Bewertung bietet einen klaren Überblick über alle externen Abhängigkeiten in Ihrer Codebasis.
Zusammenfassungsseite¶
Die Zusammenfassungsseite zeigt Ihre Bereitschaftsbewertung an und bietet einen Überblick über Ihre Ausführungsergebnisse.
Worauf Sie achten sollten Prüfen Sie die Bereitschaftsbewertung, um zu beurteilen, wie gut Ihre Codebasis auf die Konvertierung von Spark API-Referenzen in Snowpark API-Referenzen vorbereitet ist. Eine hohe Bereitschaftsbewertung zeigt an, dass der Spark-Code gut für die Migration zu Snowpark geeignet ist.
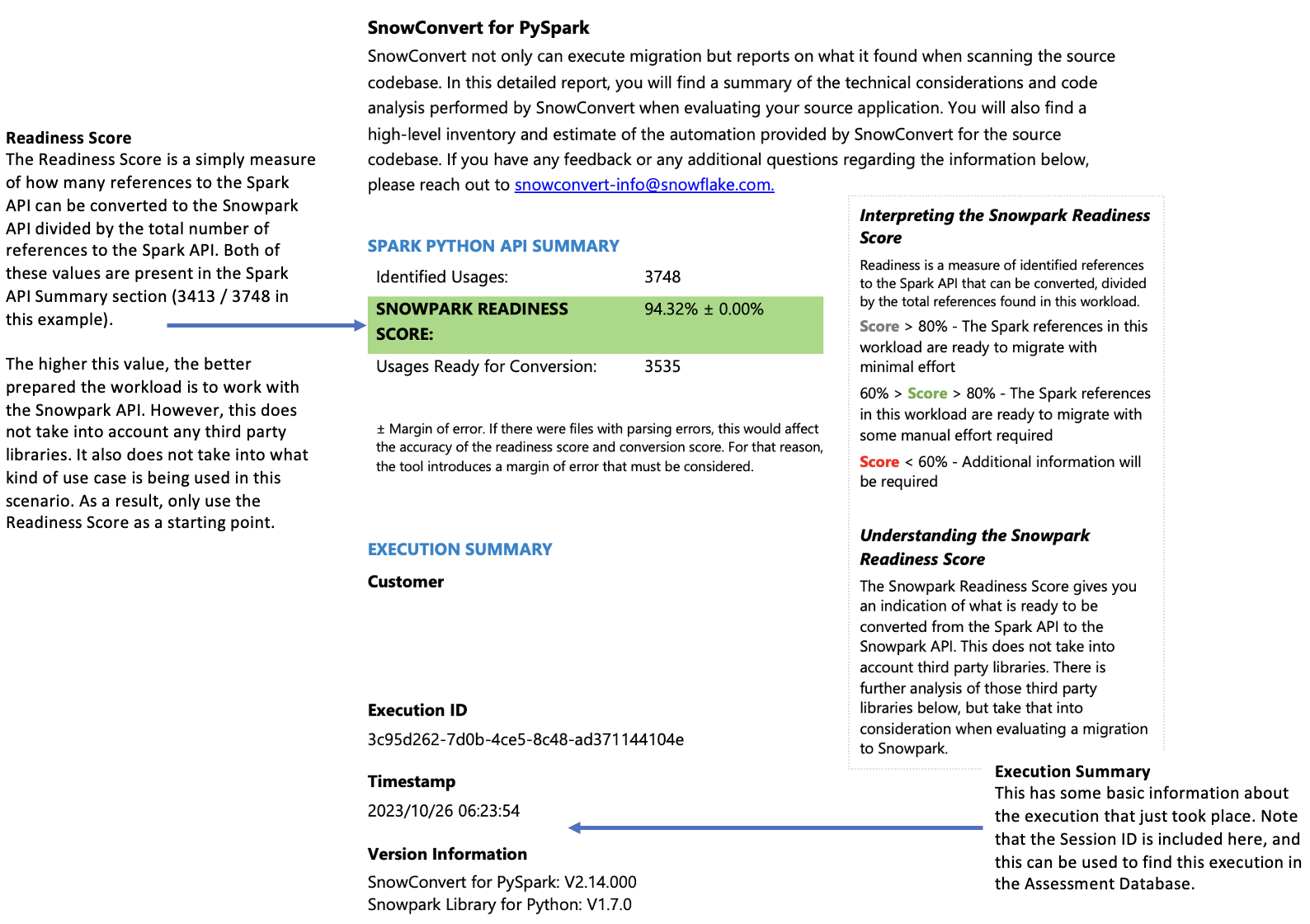
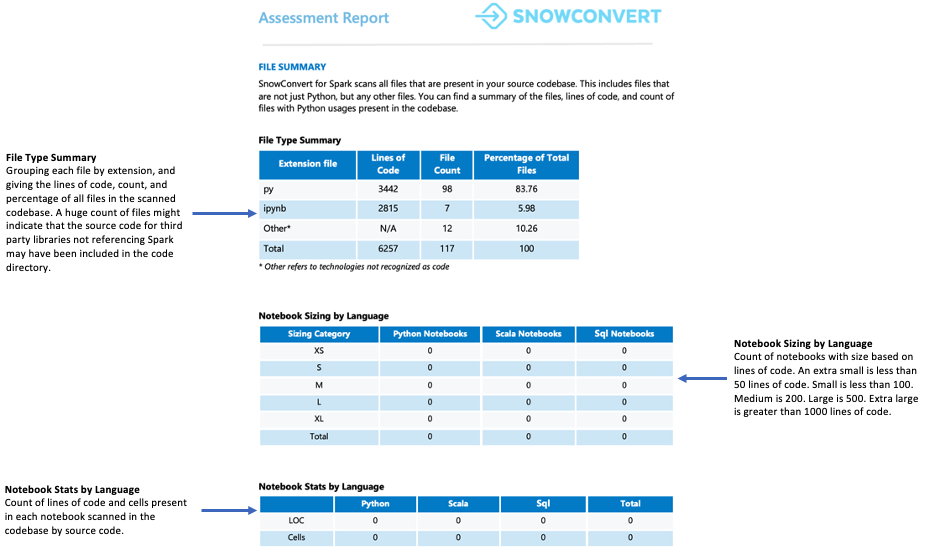
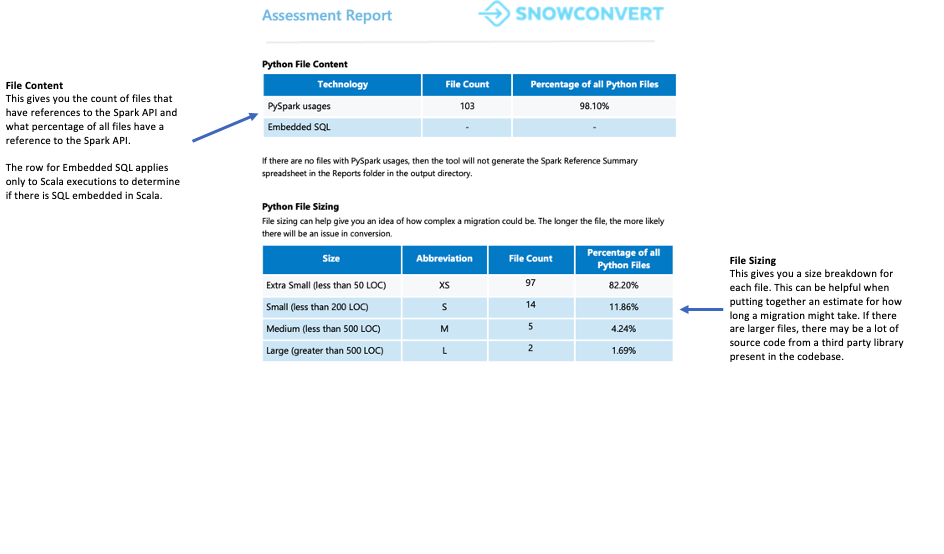
Dateizusammenfassung¶
Die Dateizusammenfassung bietet einen Überblick über Ihre Codebasis, einschließlich:
Gesamtanzahl der Codezeilen pro Dateierweiterung
Informationen zu den Notebook-Zellen (falls die Notebooks analysiert wurden)
Anzahl der Dateien mit eingebetteten SQL-Abfragen
Worauf sollten Sie achten?
Die Anzahl und der Inhalt der Dateien. Wenn Sie viele Dateien finden, aber nur einige wenige Spark API-Referenzen enthalten, könnte dies bedeuten:
Die Anwendung verwendet Spark nur minimal (vielleicht nur für die Datenextraktion und das Laden von Daten)
Der Quellcode enthält Abhängigkeiten von externen Bibliotheken
Der Anwendungsfall muss weiter untersucht werden, um zu verstehen, wie Spark genutzt wird
In beiden Szenarien ist es wichtig, den Anwendungsfall gründlich zu analysieren, bevor Sie fortfahren.
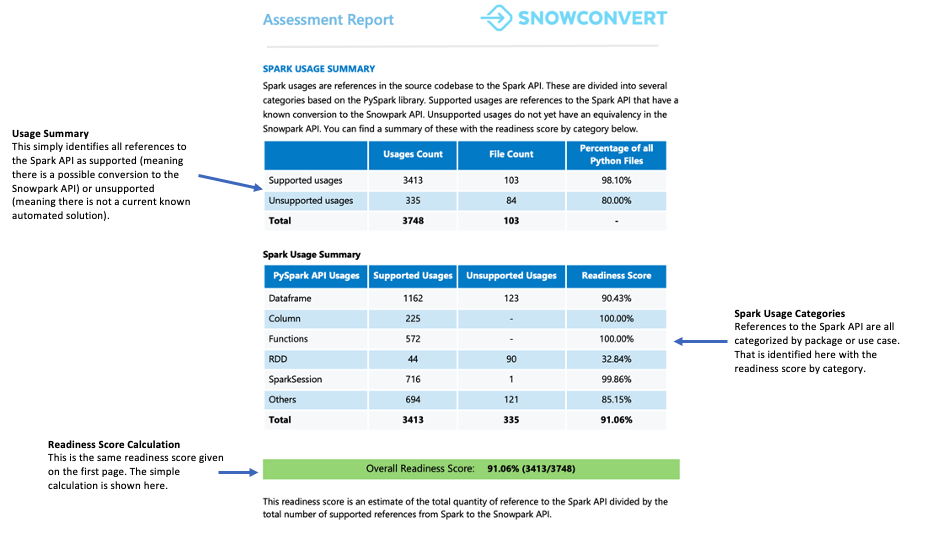
Zusammenfassung der Spark-Verwendung¶
Die Spark-Verwendungsübersicht bietet eine detaillierte Aufschlüsselung der Spark API-Referenzen, die in Ihrem Code gefunden wurden, und identifiziert, welche davon in den Snowpark API konvertiert werden können. Die Zusammenfassung kategorisiert diese Verweise in verschiedene Typen, darunter DataFrame-Operationen, Spaltenmanipulationen, SparkSession-Aufrufe und andere API-Funktionen.
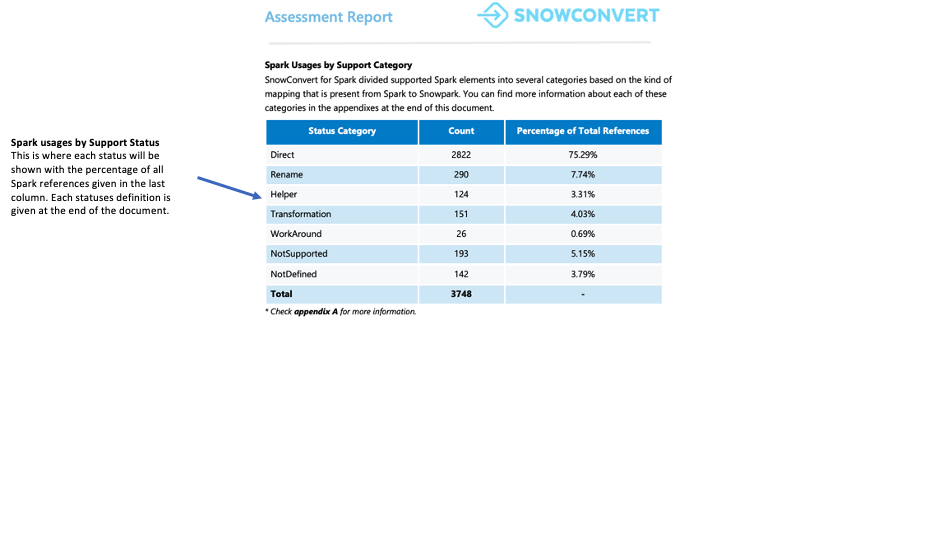
Jede Referenz wird in einen von sieben Unterstützungsstatus eingestuft. Diese Status zeigen an, ob und wie eine Referenz in Snowpark unterstützt werden kann. Die detaillierten Definitionen dieser Status finden Sie in den Anhängen des Berichts.
Direkt: Die Funktion existiert sowohl in PySpark als auch in Snowpark und kann ohne Änderungen verwendet werden.
Umbenennen: Die Funktion existiert in beiden Frameworks, erfordert aber eine Namensänderung in Snowpark.
Helper: Die Funktion erfordert eine kleine Änderung in Snowpark, die durch die Erstellung einer entsprechenden Helper-Funktion gelöst werden kann.
Transformation: Die Funktion muss in Snowpark komplett neu erstellt werden, wobei verschiedene Methoden oder mehrere Schritte verwendet werden, um das gleiche Ergebnis zu erzielen.
Problemumgehung: Die Funktion kann nicht automatisch konvertiert werden, aber es gibt eine dokumentierte manuelle Lösung.
NotSupported: Die Funktion kann nicht konvertiert werden, da Snowflake kein entsprechendes Feature hat. Das Tool fügt dem Code eine Fehlermeldung hinzu.
NotDefined: Das PySpark-Element ist noch nicht in der Datenbank des Konvertierungstools enthalten und wird in einer zukünftigen Aktualisierung hinzugefügt.
Worauf sollten Sie achten?
In diesem Abschnitt wird die Bereitschaftsbewertung angezeigt. Sie können prüfen, für wie viele Code-Referenzen Umgehungslösungen erforderlich sind und wie viele direkt übersetzt werden müssen. Wenn Ihr Code viele Umgehungsmöglichkeiten, Helper und Transformationen erfordert, empfehlen wir die Verwendung von Snowpark Migration Accelerator (SMA), um Ihre Codebasis effizient zu migrieren.
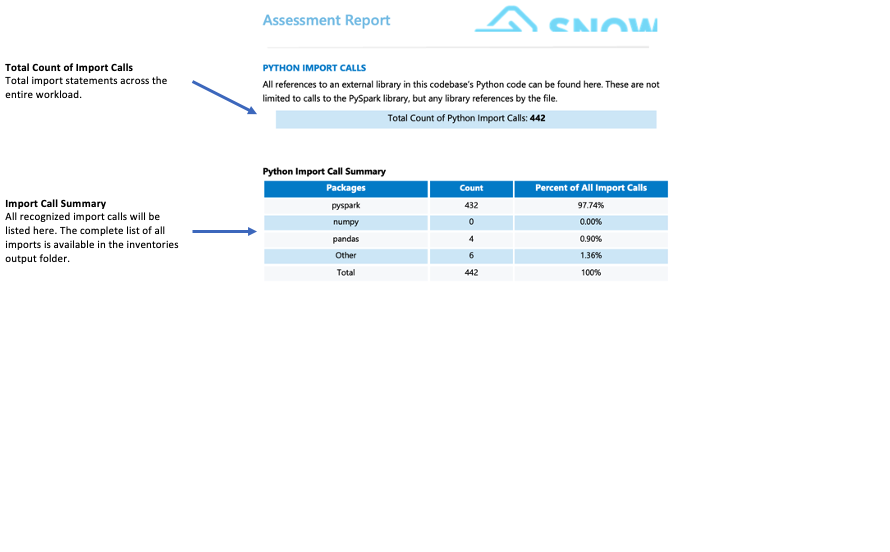
Importaufrufe:¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
Worauf sollten Sie achten?
Bibliotheken von Drittanbietern, die nicht von Snowflake unterstützt werden, können Ihre Migrationsbereitschaft erheblich beeinträchtigen. Wenn Ihr Code Bibliotheken wie mllib, streaming oder Bibliotheken von Drittanbietern wie graphs, subprocess oder smtplib importiert, kann die Migration eine Herausforderung für Sie darstellen. Das Vorhandensein dieser Bibliotheken macht eine Migration zwar nicht automatisch unmöglich, aber es erfordert eine genauere Analyse Ihres Anwendungsfalls. In solchen Situationen empfehlen wir Ihnen, das Team von WLS zu konsultieren, um eine ausführliche Bewertung vorzunehmen.
Snowpark Migration Accelerator Problemübersicht¶
Dieser Abschnitt bietet einen Überblick über mögliche Probleme und Fehler, die bei der Workload-Migration auftreten können. Ausführliche Informationen über nicht konvertierbare Elemente finden Sie an anderer Stelle, aber dieser Abschnitt ist vor allem in den ersten Stagingbereichen des Konvertierungsprozesses sehr nützlich.
Häufige Probleme, auf die Sie achten sollten
Um Elemente zu finden, die nicht konvertiert wurden oder für die es bekannte Problemumgehungen gibt, prüfen Sie das Spark-Referenzinventar in Ihrem lokalen Inventarordner. Sie können diese Elemente mit bestehenden Zuordnungen vergleichen, indem Sie die Datenbank abfragen.

Zusammenfassung:¶
Die Bereitschaftsbewertung zeigt an, wie gut Ihre Codebasis für die Migration auf Snowpark vorbereitet ist. Ein Ergebnis von 80 % oder höher bedeutet, dass Ihr Code größtenteils für die Migration bereit ist. Wenn Ihre Bewertung unter 60 % liegt, müssen Sie zusätzliche Änderungen an Ihrem Code vornehmen, bevor Sie fortfahren können.
Für diesen Workload liegt die Bewertung bei über 90 %, was auf eine ausgezeichnete Kompatibilität für die Migration hinweist.
Der nächste Indikator ist Größe. Ein Workload mit umfangreichem Code, aber wenigen Spark API-Referenzen könnte auf eine starke Abhängigkeit von Bibliotheken von Drittanbietern hindeuten. Selbst wenn ein Projekt eine niedrige Bereitschaftsbewertung hat, kann es schnell manuell konvertiert werden, wenn es nur etwa 100 Codezeilen oder 5 Spark API-Referenzen enthält, unabhängig von Automatisierungstools.
Für diesen Workload ist die Größe angemessen und leicht zu handhaben. Die Codebasis umfasst mehr als 100 Dateien mit weniger als 5.000 Spark API-Referenzen und weniger als 10.000 Zeilen Code. Ungefähr 98 % dieser Dateien enthalten Referenzen auf Spark API, was darauf hindeutet, dass der größte Teil des Python-Codes Spark-bezogen ist.
Der dritte zu untersuchende Indikator ist importierte Bibliotheken. Das Inventar der Importanweisungen hilft bei der Identifizierung der externen Pakete, die der Code verwendet. Wenn sich der Code stark auf Bibliotheken von Drittanbietern stützt, ist möglicherweise eine zusätzliche Analyse erforderlich. In Fällen mit zahlreichen externen Abhängigkeiten wenden Sie sich an das Workload-Services (WLS)-Team, um besser zu verstehen, wie diese Bibliotheken verwendet werden.
In diesem Beispiel haben wir einige referenzierte Bibliotheken von Drittanbietern, aber keine davon hat mit maschinellem Lernen, Streaming oder anderen komplexen Bibliotheken zu tun, die in Snowpark nur schwer zu implementieren wären.
Da dieser Workload für die Migration auf Snowpark geeignet ist, fahren Sie mit dem nächsten Schritt im Spark-Migrationsprozess fort.