Snowpark Migration Accelerator: 評価出力 - レポートフォルダー¶
A complete set of output files and reports will be generated when you use the Snowpark Migration Accelerator (SMA). To see the full list of generated files and reports, refer to the Output Reports section of this documentation.
The assessment generates .csv files that can be opened with any spreadsheet software. The detailed report provides a summary of these files and serves as a starting point for evaluating the results. While we'll examine some key .csv files to understand the migration requirements, we won't cover all of them. For a complete list of inventory files generated by the Snowpark Migration Accelerator (SMA), refer to the SMA Inventories section of this documentation.
レポートを表示するには、画面下部の「VIEW REPORTS」ボタンをクリックします。これでファイルエクスプローラーが開き、レポートのあるディレクトリに移動します。
詳細レポートから収集できる情報を見てみましょう。
注釈
The version of the detailed report and other inventories shown on this page may differ from what you see when running SMA. The report shown here reflects the tool version available when this walkthrough was created. If you notice significant differences or issues in your results, contact the SMA team at sma-support@snowflake.com or report an issue in the tool. You can also use the SMA tool to report documentation issues.
詳細レポート¶
The Detailed Report (.docx) provides a comprehensive summary of the information found in the inventory files. This report is essential for evaluating how well-suited your codebase is for Snowpark migration. While a complete description of the report's contents is available in the detailed documentation, this guide focuses on three key aspects:
確認する必要のある重要な要素
レディネススコアへの影響
結果の解釈
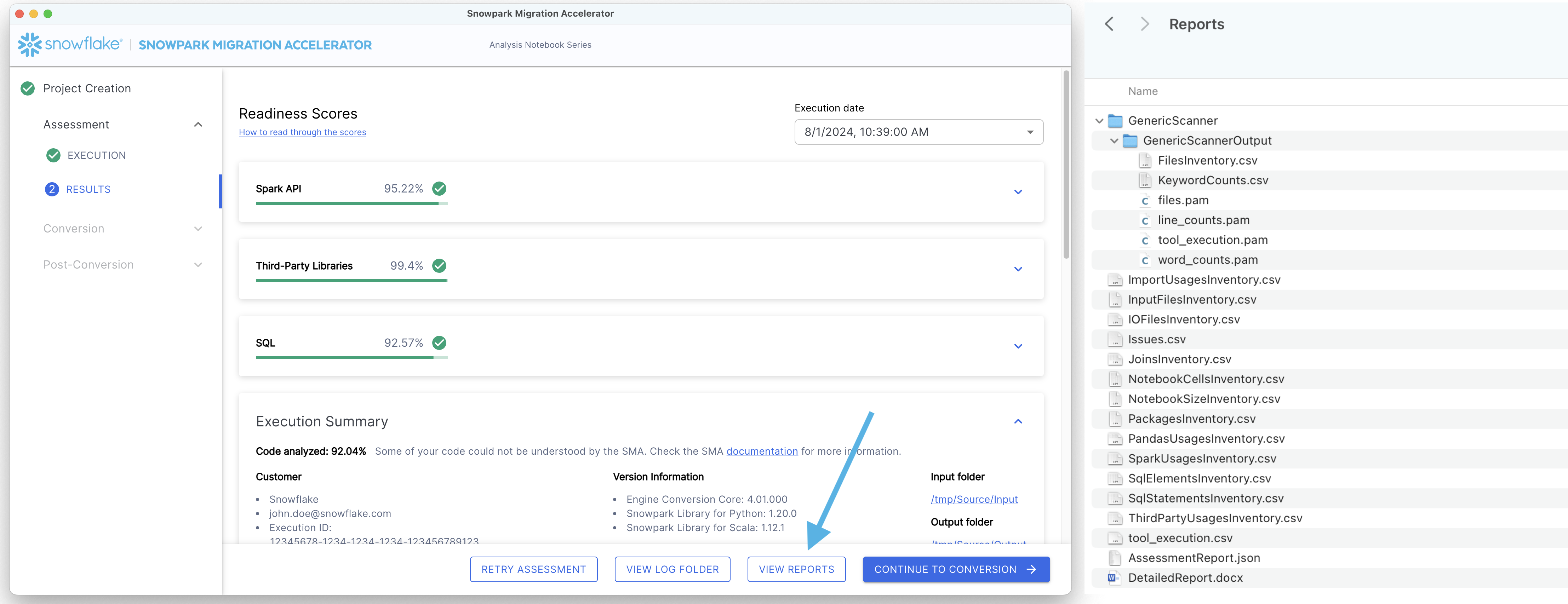
レポートに記載されているすべてのレディネススコアを確認し、移行準備のステータスを把握します。
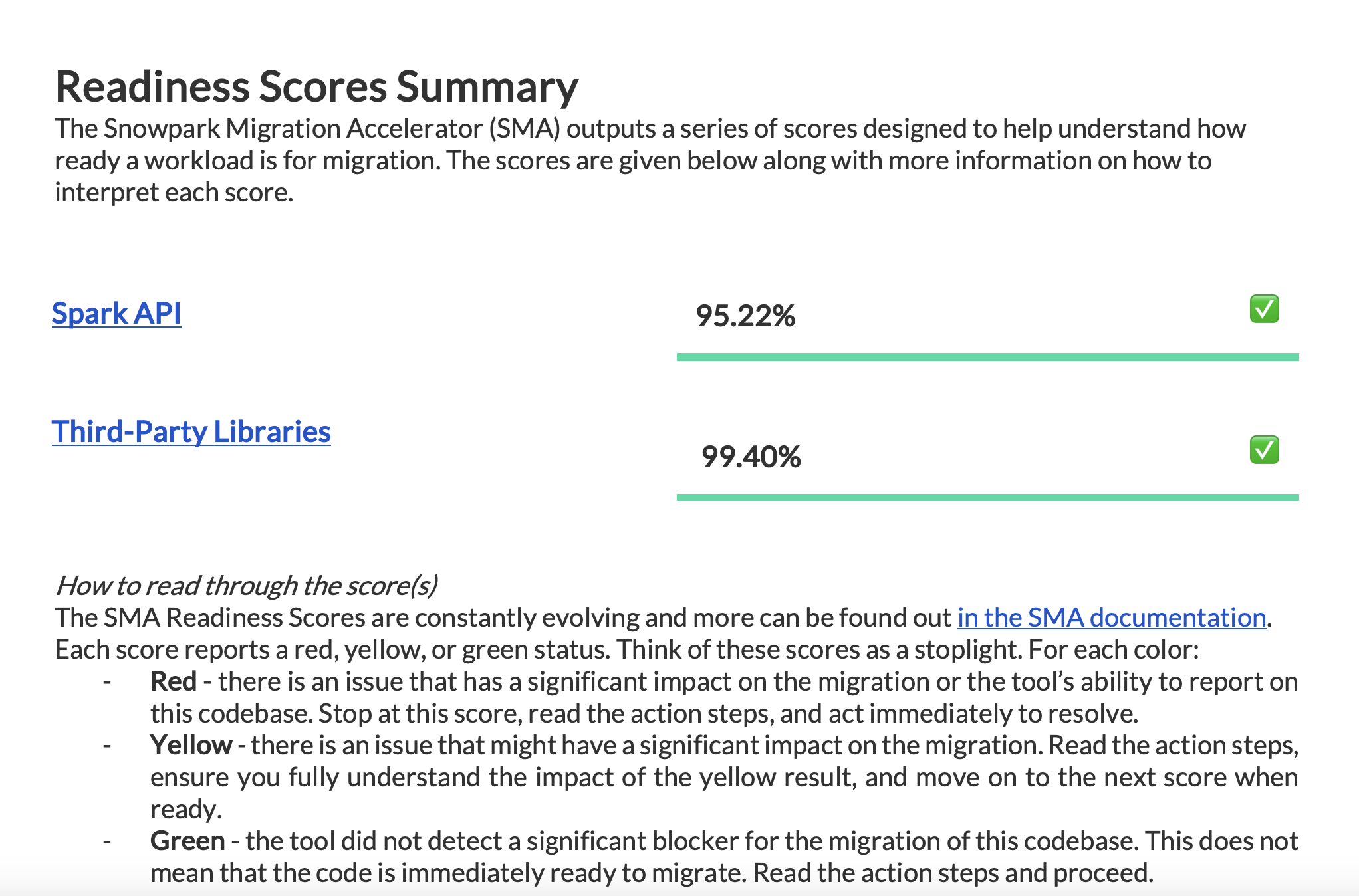
Spark API レディネススコア¶
Let's clarify what the Spark API Readiness score means and how it's calculated. This score is the main readiness indicator produced by the Snowpark Migration Accelerator (SMA). It's important to note that this score only considers Spark API usage and doesn't account for third-party libraries or other factors in your code. While this limitation means the score might not tell the complete story, it still serves as a useful starting point for your migration assessment. For more information about third-party library compatibility, refer to the Third Party API Readiness section.
変換スコアは、コード内で見つかったSpark API 参照の総数と比較して、自動的にSnowpark API に変換できるSpark API 参照の比率を表します。この場合、3746個の参照のうち3541個が変換可能です。スコアが高いほど、より多くのコードを自動的にSnowparkに移行できることを示します。未変換のコードを手動でSnowparkに適合させることは可能ですが、このスコアは、ワークロードが自動移行にどれだけ適しているかを示す信頼性の高い指標となります。
サードパーティライブラリーレディネススコア¶
サードパーティライブラリーレディネススコアは、コード内でどの外部 APIs が使用されているかを把握するのに役立ちます。このスコアは、コードベース内のすべての外部依存関係の概要を明確にします。
概要ページ¶
概要ページには、レディネススコアが表示され、実行結果の概要が表示されます。
探すもの Spark API 参照をSnowpark API 参照に変換するため、レディネススコアをチェックして、コードベースがどの程度準備されているかを評価します。レディネススコアが高いということは、Snowparkへの移行に適したSparkコードであることを示します。
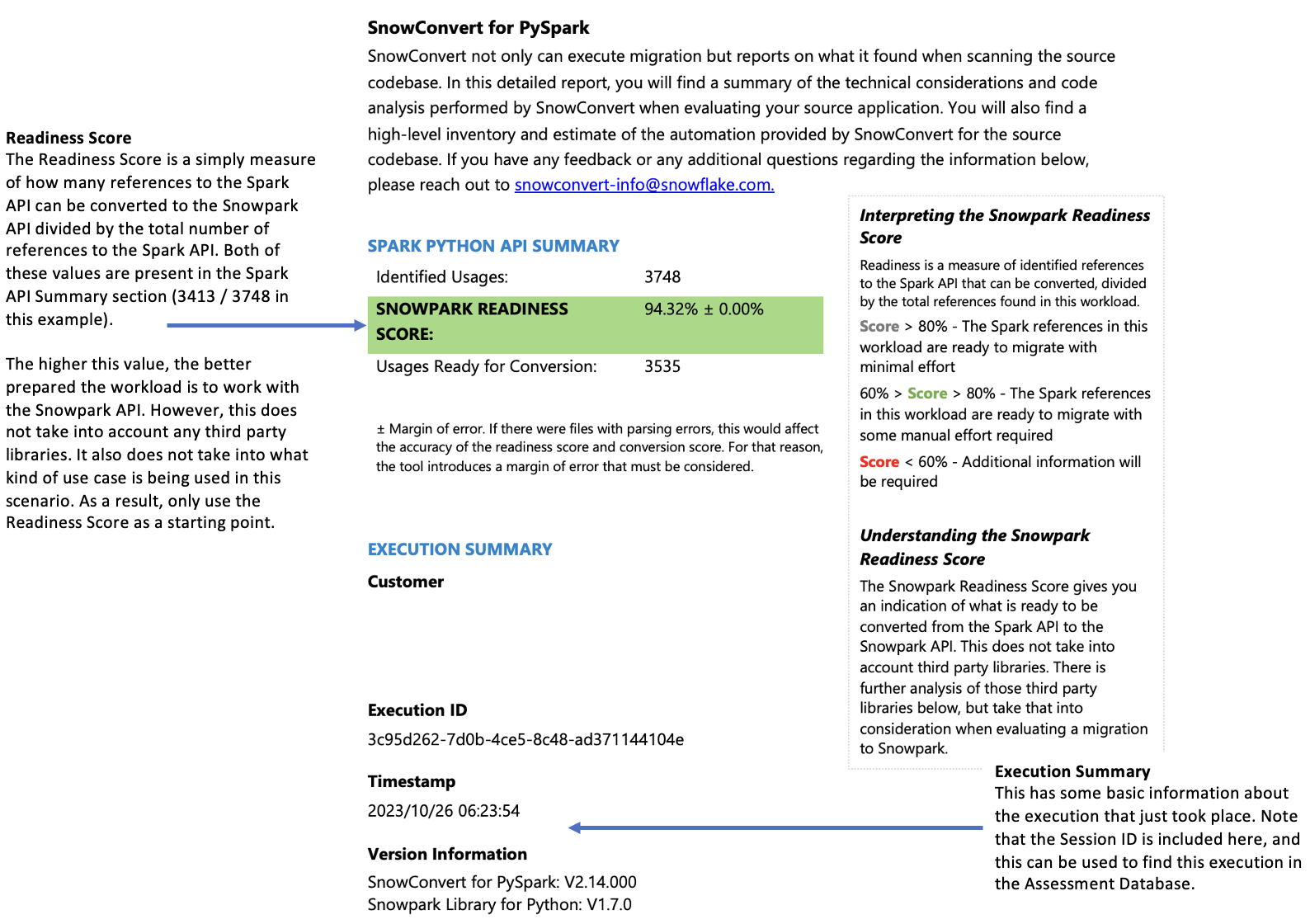
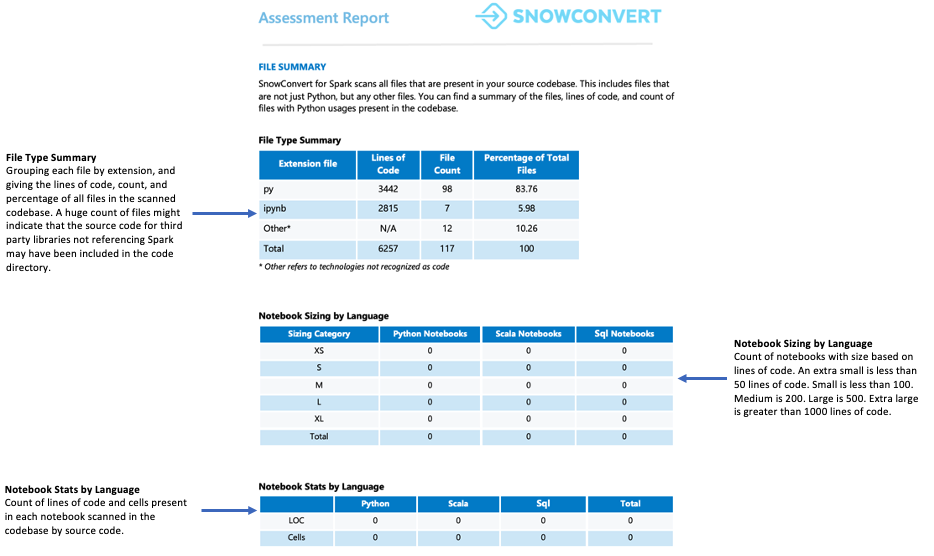
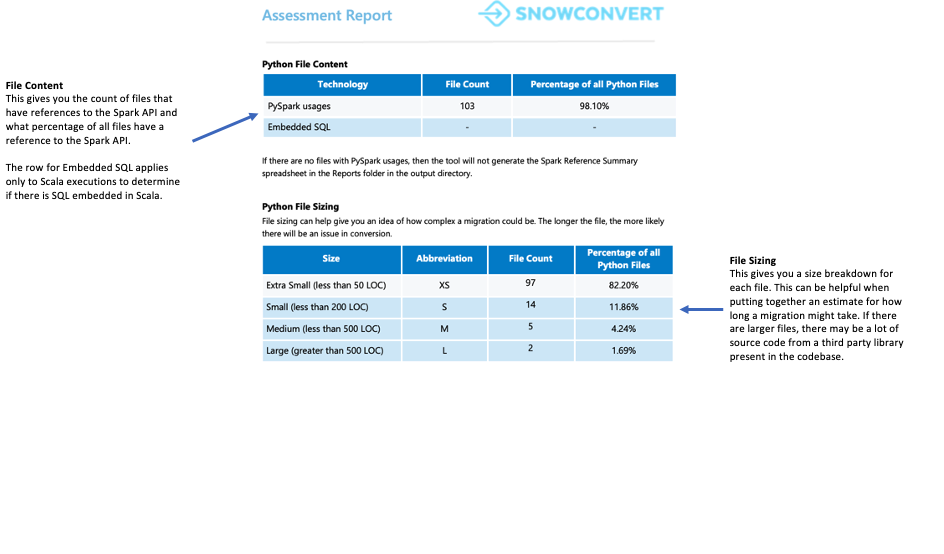
ファイルの概要¶
ファイルの概要は、以下を含むコードベースの概要を提供します。
ファイル拡張子ごとのコード総行数
ノートブックのセル情報(ノートブックを分析した場合)
SQL クエリが埋め込まれたファイルの数
注意する点
ファイルの数と内容。多くのファイルが見つかっても、Spark API の参照が含まれているのはごく少数である場合、以下の可能性があります。
アプリケーションはSparkを最低限しか使用しません(おそらくデータの抽出とロード中だけ)。
ソースコードには外部ライブラリの依存関係が含まれています。
ユースケースは、Sparkがどのように利用されているかを理解するために、さらなる調査が必要です。
いずれのシナリオでも、先に進む前にユースケースを徹底的に分析することが重要です。
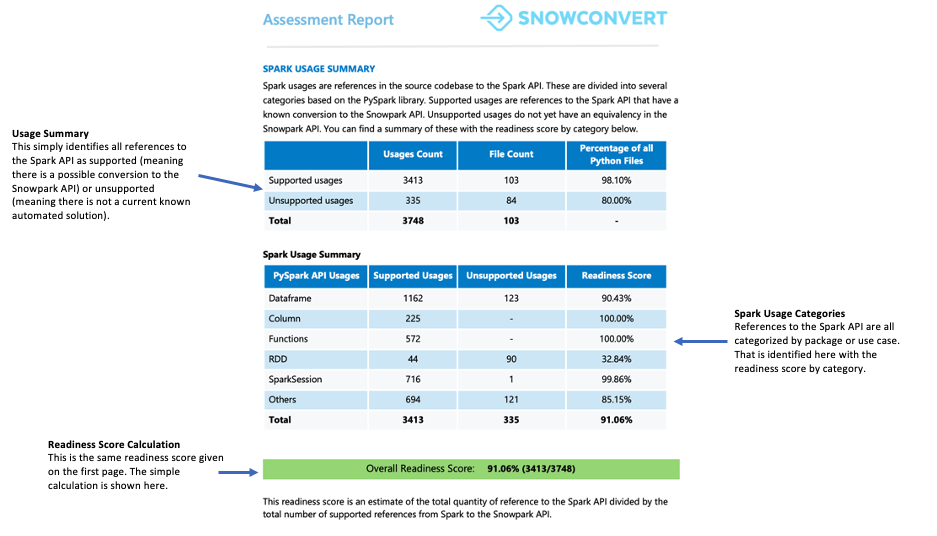
Spark使用概要¶
Spark使用概要では、コード内で見つかったSpark API 参照の詳細な内訳を提供し、どの参照がSnowpark API に変換可能かを識別します。この概要では、これらの参照を DataFrame 操作、列操作、 SparkSession 呼び出し、その他の API 関数など、さまざまなタイプに分類しています。
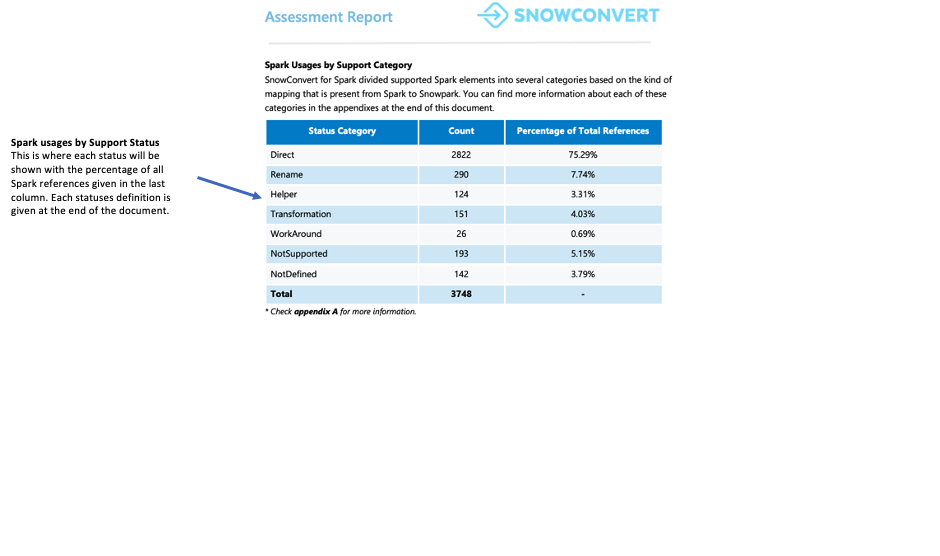
各参照は、7つのサポートステータスのいずれかに分類されます。これらのステータスは、参照がSnowparkでサポートされるかどうか、またどのようにサポートされるかを示しています。これらのステータスの詳細定義は、報告書の付録に記載されています。
直接: この関数は PySpark とSnowparkの両方に存在し、そのまま使用できます。
名前変更: この関数は両方のフレームワークに存在しますが、Snowparkでは名前の変更が必要です。
ヘルパー: この関数はSnowparkで小さな修正を必要としますが、同等のヘルパー関数を作成することで解決できます。
変換:Snowparkで同じ結果を得るためには、異なる方法または複数のステップを使用して、関数を完全に再構築する必要があります。
回避策: 関数を自動的に変換することはできませんが、ドキュメント化された手動による解決策があります。
NotSupported:Snowflakeには同等の機能がないため、関数を変換できません。ツールはコードにエラーメッセージを追加します。
NotDefined: PySpark 要素はまだ変換ツールのデータベースに含まれておらず、将来のアップデートで追加される予定です。
注意する点
レディネススコアはこのセクションに表示されます。直接の翻訳に対して回避策を必要とするコード参照の数を確認することができます。コードに多くの回避策、ヘルパー、変換が必要な場合は、Snowpark Migration Accelerator(SMA)を使用してコードベースを効率的に移行することをお勧めします。
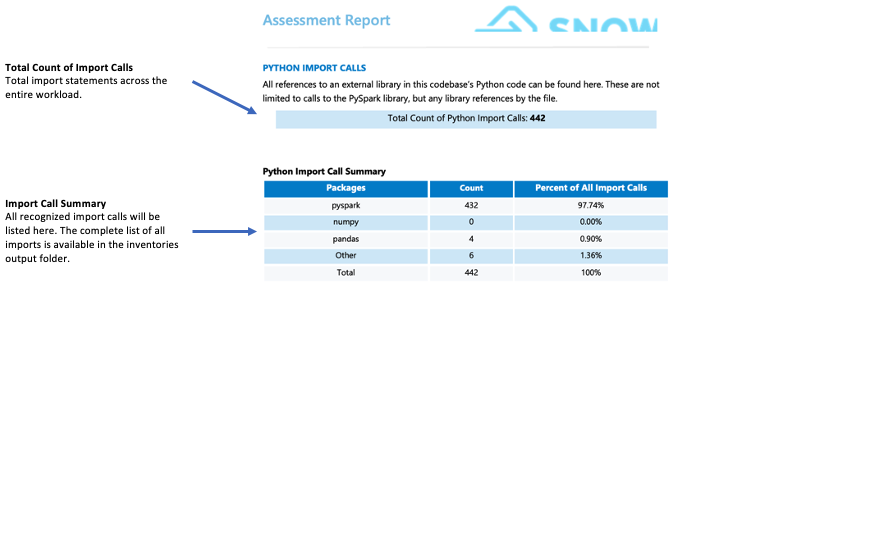
インポート呼び出し:¶
SMA tracks each package or library import as an individual import call. Common and recognized import calls are displayed in the import summary section of the detailed report page. All import calls are recorded in both the local output inventories folder and the assessment database. Note that these import calls have not yet been classified as supported or unsupported in Snowflake.
注意する点
Snowflakeがサポートしていないサードパーティライブラリは、移行準備に大きな影響を与える可能性があります。コードがmllibやストリーミングなどのライブラリや、グラフ、サブプロセス、smtplibなどのサードパーティライブラリをインポートしている場合、移行の課題に直面する可能性があります。これらのライブラリがあるからといって自動的に移行が不可能になるわけではありませんが、ユースケースをより深く分析する必要があります。そのような場合は、 WLS チームに相談し、詳細な評価を受けることをお勧めします。
Snowpark Migration Accelerator の問題の概要¶
このセクションでは、ワークロードの移行中に発生する可能性のある問題とエラーの概要を説明します。変換不可能な要素に関する詳細な情報は別の場所で入手可能ですが、このセクションは変換プロセスの初期ステージで特に価値があります。
注意すべき一般的な問題
変換されなかった要素や既知の回避策がある要素を見つけるには、ローカルインベントリフォルダーにあるSpark参照インベントリを確認します。データベースをクエリすると、これらの要素を既存のマッピングと比較できます。

概要:¶
レディネススコアは、Snowpark移行に対するコードベースの準備状況を示します。スコアが80%以上であれば、コードの移行準備はほぼ整っていることになります。スコアが60%未満の場合は、先に進む前にコードをさらに修正する必要があります。
このワークロードでは、スコアが90%を超えており、移行に対する優れた互換性を示しています。
次のインジケーターは サイズ です。膨大なコードがあるにもかかわらず、Spark API 参照がほとんどないワークロードは、サードパーティのライブラリに大きく依存している可能性があります。レディネススコアが低いプロジェクトであっても、コード行数が100行程度、またはSpark API 参照が5つ程度であれば、自動化ツールに関係なく、手動で迅速に変換することができます。
このワークロードの場合は、サイズも手頃で扱いやすいものです。コードベースには100個以上のファイルがあり、Spark API 参照数は5,000個未満、コード行数は10,000行未満です。これらのファイルの約98%にSpark API 参照が含まれており、PythonコードのほとんどがSpark関連であることがわかります。
3つ目のインジケーターは、 インポートされたライブラリ です。インポートステートメントのインベントリは、コードがどの外部パッケージを使用しているかを識別するのに役立ちます。コードがサードパーティのライブラリに大きく依存している場合は、追加の分析が必要になることがあります。外部依存関係が多数あるユースケースの場合は、ワークロードサービス(WLS)チームに相談して、これらのライブラリがどのように使用されているかをよりよく理解するようにします。
この例では、サードパーティのライブラリをいくつか参照していますが、機械学習やストリーミングなど、Snowparkでの実装が困難な複雑なライブラリに関連するものはありません。
このワークロードはSnowparkへの移行に適しているため、Spark移行プロセスの次のステップに進みます。