Identifying Sequences of Rows That Match a Pattern¶
Introduction¶
In some cases, you might need to identify sequences of table rows that match a pattern. For example, you might need to:
- Determine which users followed a specific sequence of pages and actions on your website before opening a support ticket or making a purchase.
- Find the stocks with prices that followed a V-shaped or W-shaped recovery over a period of time.
- Look for patterns in sensor data that might indicate an upcoming system failure.
To identify sequences of rows that match a specific pattern, use the MATCH_RECOGNIZE subclause of the
FROM clause.
Note
You cannot use the MATCH_RECOGNIZE clause in a recursive common table expression (CTE).
A Simple Example That Identifies a Sequence of Rows¶
As an example, suppose that a table contains data about stock prices. Each row contains the closing price of each stock symbol on a specific day. The table contains the following columns:
| Column Name | Description |
|---|---|
price_date | The date of the closing price. |
price | The closing stock price on that date. |
Suppose that you want to detect a pattern in which the stock price decreases and then increases, producing a “V” shape in the graph of the stock price.
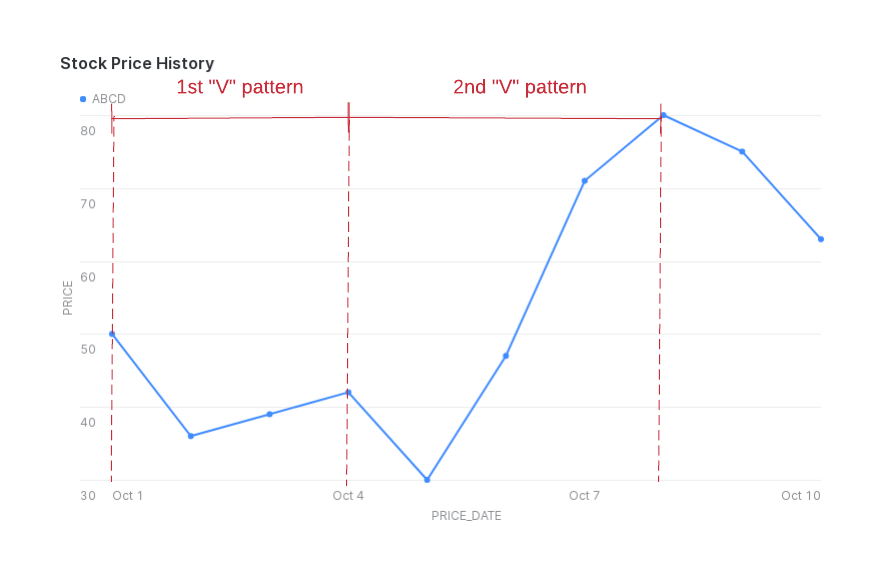
(This example does not account for cases in which the stock price does not change from day to day.)
In this example, for a given stock symbol, you want to find sequences of rows where the value in the price column decreases
before increasing.
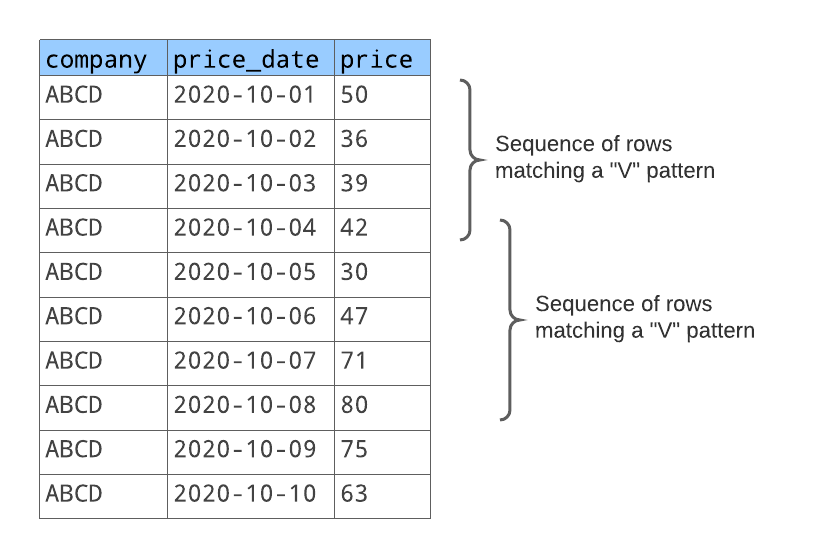
For each sequence of rows that matches this pattern, you want to return:
- A number that identifies the sequence (the first matching sequence, the second matching sequence, etc.).
- The day before the stock price decreased.
- The last day when the stock price increased.
- The number of days in the “V” pattern.
- The number of days when the stock price decreased.
- The number of days when the stock price increased.
The following figure illustrates the price decreases (NUM_DECREASES) and increases (NUM_INCREASES) within the “V” pattern
that the returned data captures. Note that ROWS_IN_SEQUENCE includes an initial row that is not counted in NUM_DECREASES
or NUM_INCREASES.
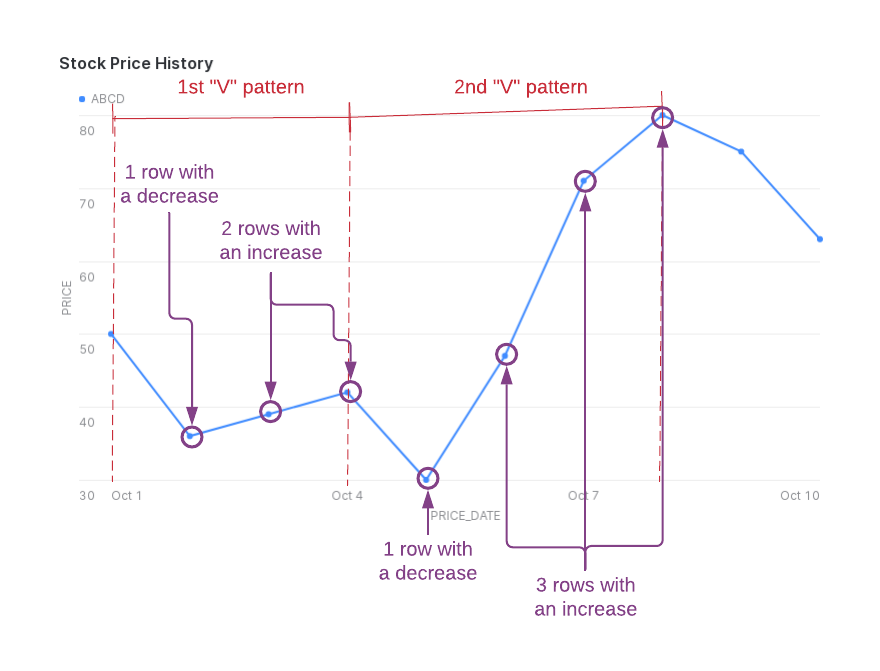
To produce this output, you can use the MATCH_RECOGNIZE clause shown below.
As shown above, the MATCH_RECOGNIZE clause consists of many subclauses, each of which serves a different purpose (e.g.
specifying the pattern to match, specifying the data to return, etc.).
The next sections explain each of the subclauses in this example.
Setting Up the Data For This Example¶
To set up the data used in this example, run the following SQL statements:
Step 1: Specifying the Order and Grouping of Rows¶
The first step in identifying a sequence of rows is defining the grouping and sort order of the rows that you want to search. For the example of finding a “V” pattern in the stock price for a company:
- The rows should be grouped by company, since you want to find a pattern in the price for a given company.
- Within each group of rows (the prices for a given company), the rows should be sorted by date in ascending order.
In a MATCH_RECOGNIZE clause, you use the PARTITION BY and ORDER BY subclauses to specify the grouping and
order of rows. For example:
Step 2: Defining the Pattern to Match¶
Next, determine the pattern that matches the sequence of rows that you want to find.
To specify this pattern, you use something similar to a regular expression. In regular expressions, you use a combination of literals and metacharacters to specify a pattern to match in a string.
For example, to find a sequence of characters that includes:
- any single character, followed by
- one or more uppercase letters, followed by
- one or more lowercase letters
you can use the following Perl-compatible regular expression:
where:
.matches any single character.[A-Z]+matches one or more uppercase letters.[a-z]+matches one or more lowercase letters.
+ is a quantifier that specifies that one or more of the
preceding characters need to match.
For example, the regular expression above matches sequences of characters like:
1Stock@SFComputing%Fn
In a MATCH_RECOGNIZE clause, you use a similar expression to specify the pattern of rows to match. In this case, finding
rows that match a “V” pattern involves finding a sequence of rows that includes:
- the row before the stock price decreases, followed by
- one or more rows where the stock price decreases, followed by
- one or more rows where the stock price increases
You can express this as the following row pattern:
Row patterns consist of pattern variables, quantifiers (which are similar to those used in regular expressions), and operators. A pattern variable defines an expression that is evaluated against a row.
In this row pattern:
-
row_before_decrease,row_with_price_decrease, androw_with_price_increaseare pattern variables. The expressions for these pattern variables should evaluate to:- any row (the row before the stock price decreases)
- a row where the stock price decreases
- a row where the stock price increases
row_before_decreaseis similar to.in a regular expression. In the following regular expression,.matches any single character that appears before the first uppercase letter in the pattern.Similarly, in the row pattern,
row_before_decreasematches any single row that appears before the first row with a price decrease. -
The
+quantifiers afterrow_with_price_decreaseandrow_with_price_increasespecify that one or more rows of each of these must match.
In a MATCH_RECOGNIZE clause, you use the PATTERN subclause to specify the row pattern to match:
To specify the expressions for the pattern variables, you use the DEFINE subclause:
where:
row_before_decreasedoes not need to be defined here because it should evaluate to any row.row_with_price_decreaseis defined as an expression for a row with a price decrease.row_with_price_increaseis defined as an expression for a row with a price increase.
To compare the prices in different rows, the definitions of these variables use the
navigational function LAG() to specify price for the previous row.
The row pattern matches two sequences of rows, as illustrated below:

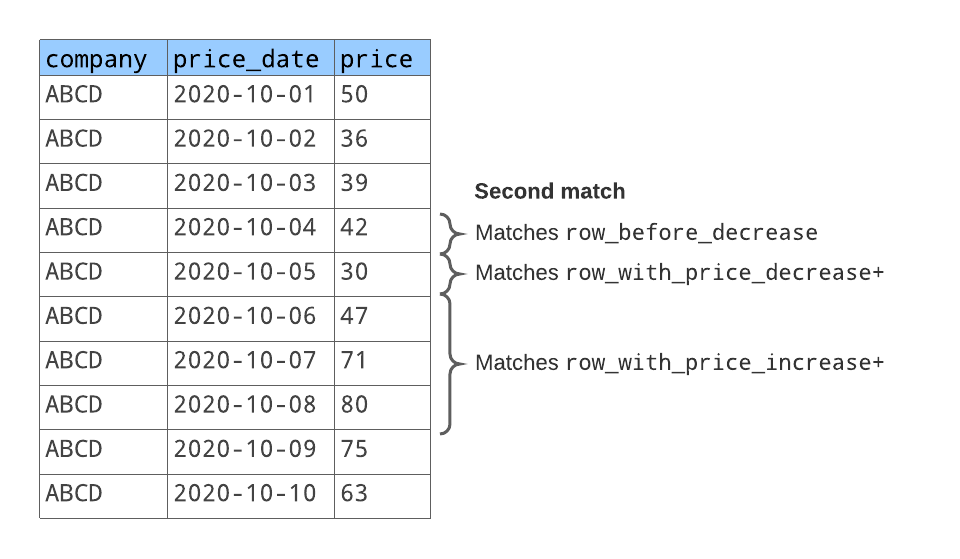
For the first matching sequence of rows:
row_before_decreasematches the row with the stock price50.row_with_price_decreasematches the next row with the stock price36.row_with_price_increasematches the next two rows with the stock prices39and42.
For the second matching sequence of rows:
row_before_decreasematches the row with the stock price42. (This is the same row that is at the end of the first matching sequence of rows.)row_with_price_decreasematches the next row with the stock price30.row_with_price_increasematches the next two rows with the stock prices47,71, and80.
Step 3: Specifying the Rows to Return¶
MATCH_RECOGNIZE can either return:
- a single row that summarizes each matching sequence, or
- each row in each matching sequence
For this example, you want to return a summary of each matching sequence. Use the ONE ROW PER MATCH subclause to specify
that one row should be returned for each matching sequence.
Step 4: Specifying the Measures to Select¶
When you use ONE ROW PER MATCH, MATCH_RECOGNIZE does not return any of the columns in the table (except for the
column specified by PARTITION BY), even when MATCH_RECOGNIZE is in a SELECT * statement. To specify the
data to be returned by this statement, you must define measures. Measures are additional columns of data that are calculated for
each matching sequence of rows (e.g. the starting date of the sequence, the ending date of the sequence, the number of days in the
sequence, etc.).
Use the MEASURES subclause to specify these additional columns to return in the output. The general format for defining a
measure is:
where:
expressionspecifies the information about the sequence that you want to return. For the expression, you can use functions with columns from the table and pattern variables that you defined earlier.column_namespecifies the name of the column that will be returned in the output.
For this example, you can define the following measures:
-
A number that identifies the sequence (the first matching sequence, the second matching sequence, etc.).
For this measure, use the
MATCH_NUMBER()function, which returns the number of the match. The numbers start with1for the first match for a partition of rows. If there are multiple partitions, the number starts with1for each partition. -
The day before the stock price decreased.
For this measure, use the
FIRST()function, which returns the value of the expression for the first row in the matching sequence. In this example,FIRST(price_date)returns the value of theprice_datecolumn in the first row in each matching sequence, which is the date before the stock price decreased. -
The last day when the stock price increased.
For this measure, use the
LAST()function, which returns the value of the expression for the last row in the matching sequence. -
The number of days in the “V” pattern.
For this measure, use
COUNT(*). Because you are specifyingCOUNT(*)in the definition of a measure, the asterisk (*) specifies that you want to count all of the rows in a matching sequence (not all of the rows in the table). -
The number of days when the stock decreased.
For this measure, use
COUNT(row_with_price_decrease.*). The period followed by an asterisk (.*) specifies that you want to count all of the rows in a matching sequence that match the pattern variablerow_with_price_decrease. -
The number of days when the stock increased.
For this measure, use
COUNT(row_with_price_increase.*).
The following is the MEASURES subclause that defines the measures above:
The following shows an example of the output with the selected measures:
As mentioned earlier, the output includes the company column because the PARTITION BY clause specifies that column.
Step 5: Specifying Where to Continue Finding the Next Match¶
After finding a matching sequence of rows, MATCH_RECOGNIZE continues to find the next matching sequence. You can specify
where MATCH_RECOGNIZE should start searching for the next matching sequence.
As shown in the illustration of matching sequences, a row can be part of
more than one matching sequence. In this example, the row for 2020-10-04 is part of two “V” patterns.
For this example, to find the next matching sequence, you can start from a row where the price increased. To specify this in the
MATCH_RECOGNIZE clause, use AFTER MATCH SKIP:
where TO LAST row_with_price_increase specifies that you want to start searching at
the last row where the price increased.
Partitioning and Sorting the Rows¶
The first step in identifying patterns across rows is putting the rows in an order that allows you to find your patterns. For example, if you want to find a pattern of changes in stock prices over time for each company’s stock:
- Partition the rows by company, so that you can search across each company’s stock prices.
- Sort the rows within each partition by date, so that you can find changes to a company’s stock price over time.
To partition the data and specify the order of rows, use the PARTITION BY and
ORDER BY subclauses in MATCH_RECOGNIZE. For example:
(The PARTITION BY clause for MATCH_RECOGNIZE works the same way as the PARTITION BY clause for
window functions.)
An additional benefit of partitioning is that it can take advantage of parallel processing.
Defining the Pattern of Rows to Match¶
With MATCH_RECOGNIZE, you can find a sequence of rows that match a pattern. You specify this pattern in terms of rows that
match specific conditions.
In the example of the table of daily stock prices for different companies, suppose that you want to find a sequence of three rows in which:
- On a given day, the stock price for a company is less than 45.00.
- On the next day, the stock price decreases by at least 10%.
- On the following day, the stock price increases by at least 3%.
To find this sequence, you specify a pattern that matches three rows with the following conditions:
- In the first row in the sequence, the value of the
pricecolumn must be less than 45.00. - In the second row, the value of the
pricecolumn must be less than or equal to 90% of the value of the previous row. - In the third row, the value of the
pricecolumn must be greater than or equal to 105% of the value of the previous row.
The second and third rows have conditions that require a comparison between column values in different rows. To compare the value
in one row against the value in the previous or next row, use the functions LAG() or LEAD():
LAG(column)returns the value ofcolumnin the previous row.LEAD(column)returns the value ofcolumnin the next row.
For this example, you can specify the conditions for the three rows as:
- The first row in the sequence must have
price < 45.00. - The second row must have
LAG(price) * 0.90 >= price. - The third row must have
LAG(price) * 1.05 <= price.
When specifying the pattern for the sequence of these three rows, you use a pattern variable for each row that has a different
condition. Use the DEFINE subclause to define each pattern variable as a row that must meet a specified condition. The
following example defines three pattern variables for the three rows:
To define the pattern itself, use the PATTERN subclause. In this subclause, use a regular expression to specify the
pattern to match. For the building blocks of the expression, use the pattern variables that you defined. For example, the
following pattern finds the sequence of three rows:
The SQL statement below uses the DEFINE and PATTERN subclauses shown above:
The next sections explain how to define patterns that match specific numbers of rows and rows that appear at the beginning or end of a partition.
- Using Quantifiers With Pattern Variables
- Matching Patterns Relative to the Beginning or End of a Partition
Note
MATCH_RECOGNIZE uses backtracking to match patterns. As is the case with other regular expression engines that use backtracking, some combinations of patterns and data to match can take a long time to execute, which can result in high computation costs.
To improve performance, define a pattern that is as specific as possible:
- Make sure that each row matches only one symbol or a small number of symbols
- Avoid using symbols that match every row (e.g. symbols not in the
DEFINEclause or symbols that are defined as true) - Define an upper limit for quantifiers (e.g.
{,10}instead of*).
For example, the following pattern can result in increased costs if no rows match:
If there is an upper limit to the number of rows that you want to match, you can specify that limit in the quantifiers to
improve performance. In addition, rather than specifying that you want to find any_symbol that follows symbol1, you can
look for a row that is not symbol1 (not_symbol1, in this example);
In general, you should monitor the query execution time to verify that the query is not taking longer than expected.
Using Quantifiers With Pattern Variables¶
In the PATTERN subclause, you use a regular expression to specify a pattern of rows to match. You use pattern variables
to identify rows in the sequence that meet specific conditions.
If you need to match multiple rows that meet a specific condition, you can use a quantifier, as you would in a regular expression.
For example, you can use the quantifier + to specify that pattern must include one or more rows in which the stock price
decreases by 10%, followed by one or more rows in which the stock price increases by 5%:
Matching Patterns Relative to the Beginning or End of a Partition¶
To find a sequence of rows relative to the beginning or end of a partition, you can use the metacharacters ^ and $ in the
PATTERN subclause. These metacharacters in a row pattern have a similar purpose as
the same metacharacters have in a regular expression:
^represents the beginning of a partition.$represents the end of a partition.
The following pattern matches a stock with a price greater than 75.00 at the beginning of the partition:
Note that ^ and $ specify positions and do not represent the rows at those positions (much like ^ and $ in a
regular expression specify the position and not the characters at those positions). In PATTERN (^ GT75), the first row
(not the second row) must have a price greater than 75.00. In PATTERN (GT75 $), the last row (not the second-to-last row)
must be greater than 75.
Here is a complete example with ^. Note that although the XYZ stock has a price higher than 60.00 in more than one
row in this partition, only the row at the start of the partition is considered a match.
Here is a complete example with $. Note that although the ABCD stock has a price higher than 50.00 in more than
one row in this partition, only the row at the end of the partition is considered a match.
Specifying Output Rows¶
Statements that use MATCH_RECOGNIZE can choose which rows to output.
Generating One Row for Each Match vs Generating All Rows for Each Match¶
When MATCH_RECOGNIZE finds a match, the output can be either one summary row for the entire match, or one row
for each data point in the pattern.
-
ALL ROWS PER MATCHspecifies that the output include all rows in the match. -
ONE ROW PER MATCHspecifies that the output include only one row for each match in each partition.The projection clause of the SELECT statement can use only the output of the
MATCH_RECOGNIZE. Effectively, this means that the SELECT statement can only use columns from the following subclauses ofMATCH_RECOGNIZE:-
The
PARTITION BYsubclause.All rows in a match are from the same partition, and therefore have the same value for the
PARTITION BYsubclause expressions. -
The
MEASURESclause.When you use
MATCH_RECOGNIZE ... ONE ROW PER MATCH, theMEASURESsubclause generates not only expressions that return the same value for all rows in the match (e.g.MATCH_NUMBER()), but also expressions that can return different values for different rows in the match (e.g.MATCH_SEQUENCE_NUMBER()). If you use expressions that can return different values for different rows in the match, the output is not deterministic.
If you are familiar with aggregate functions and
GROUP BY, the following analogy might be helpful in understandingONE ROW PER MATCH:- The
PARTITION BYclause inMATCH_RECOGNIZEgroups data similarly to the way thatGROUP BYgroups data in aSELECT. - The
MEASURESclause in aMATCH_RECOGNIZE ... ONE ROW PER MATCHallows aggregate functions, such asCOUNT(), that return the same value for each row in the match, asMATCH_NUMBER()does.
If you use only aggregate functions and expressions that return the same value for each row in the match, then
... ONE ROW PER MATCHbehaves similarly toGROUP BYand aggregate functions. -
The default is ONE ROW PER MATCH.
The following examples show the difference in outputs between ONE ROW PER MATCH and ALL ROWS PER MATCH.
These two code examples are almost identical except for the ...ROW(S) PER MATCH clause. (In typical usage, a SQL
statement with ONE ROW PER MATCH has different MEASURES subclauses than a SQL statement with
ALL ROWS PER MATCH.)
Excluding Rows from the Output¶
For some queries, you might want to include only part of the pattern in the output. For example, you might want to find patterns in which stocks rose many days in a row, but display only the peaks and some summary information (for example, the number of days of price increases before each peak).
You can use exclusion syntax in the pattern to tell MATCH_RECOGNIZE to
search for a particular pattern variable but not include it in the output. To include a pattern variable as part of
the pattern to search for, but not as part of the output, use the {- <pattern_variable> -} notation.
Here is a simple example that shows the difference between using exclusion syntax and not using it. This example contains two queries, each of which searches for a stock price that started at less than $45, then decreased, and then increased. The first query does not use exclusion syntax, and therefore shows all the rows. The second query uses the exclusion syntax and does not show the day that the stock price fell.
The next example is more realistic. It searches for patterns in which a stock price rose one or more days in a row, and then fell one or more days in a row. Because the output could be quite large, this uses exclusion to show only the first day the stock rose (if it rose more than one day in a row) and only the first day it dropped (if it dropped more than one day in a row). The pattern is shown below:
This pattern looks for the following events in order:
- A starting price less than 45.
- An UP, possibly followed immediately by others that are not included in the output.
- A DOWN, possibly followed immediately by others that are not included in the output.
Here are the code and output for versions of the preceding pattern without exclusion and with exclusion:
Returning Information About the Match¶
Basic Match Information¶
In many cases, you want your query to list not only information from the table that contains the data, but also
information about the patterns that were found. When you want information about the matches themselves, you specify
that information in the MEASURES clause.
The MEASURES clause can include the following functions, which are specific to MATCH_RECOGNIZE:
MATCH_NUMBER(): Each time a match is found, it is assigned a sequential match number, starting from one. This function returns that match number.MATCH_SEQUENCE_NUMBER(): Because a pattern usually involves more than one data point, you might want to know which data point is associated with each value from the table. This function returns the sequential number of the data point within the match.CLASSIFIER(): The classifier is the name of the pattern variable that the row matched.
The query below includes a MEASURES clause with the match number, match sequence number, and classifier.
The MEASURES subclause can produce much more information than this. For more details, see
the MATCH_RECOGNIZE reference documentation.
Windows, Window Frames, and Navigational Functions¶
The MATCH_RECOGNIZE clause operates on a “window” of rows. If the MATCH_RECOGNIZE contains a PARTITION
subclause, then each partition is one window. If there is
no PARTITION subclause, then the entire input is one window.
The PATTERN subclause of MATCH_RECOGNIZE specifies the symbols in order from left to right. For example:
If you picture the data as a sequence of rows in ascending order from left to right, you can think of
MATCH_RECOGNIZE as moving rightward (e.g. from the earliest date to the latest date in the stock price example),
searching for a pattern in the rows inside each window.
MATCH_RECOGNIZE starts with the first row in the window and checks whether that row and the subsequent rows
match the pattern.
In the simplest case, after determining whether there’s a pattern match starting at the first row in the window,
MATCH_RECOGNIZE moves rightward one row and repeats the process, checking whether the 2nd row is the beginning
of an occurrence of the pattern. MATCH_RECOGNIZE continues moving rightward until it reaches the end of the window.
(MATCH_RECOGNIZE can move rightward by more than one row. For example, you can tell MATCH_RECOGNIZE to start
searching for the next pattern after the end of the current pattern.)
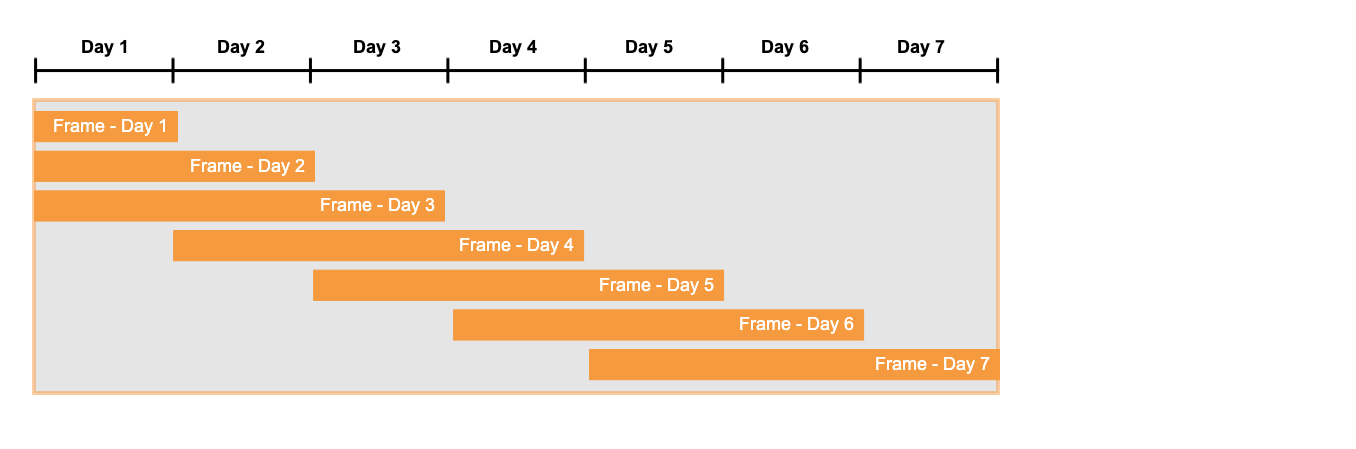
You can picture this loosely as though there were a “frame” moving rightward inside the window. The left-hand edge
of that frame is at the first row in the set of rows currently being checked for a match. The right-hand edge
of the frame is not defined until a match is found; once a match is found, the right-hand edge of the frame is
the last row in the match. For example, if the search pattern were pattern (start down up) then the
row that matches the up is the last row before the right-hand edge of the frame.
(If no match is found, then the right-hand edge of the frame is never defined and is never referenced.)
In simple cases, you can picture a sliding window frame as illustrated below:
You have already seen navigational functions such as LAG()
used in expressions in the DEFINE subclause (e.g. DEFINE down_10_percent as LAG(price) * 0.9 >= price).
The following query shows that navigational functions can also be used in the MEASURES subclause. In this example,
the navigational functions show the edges (and thus the size) of the window frame that contains the current match.
Each output row from this query includes the values of the LAG(), LEAD(), FIRST(), and LAST()
navigational functions for that row. The size of the window frame is the number of rows between FIRST() and
LAST(), including the first and last rows themselves.
The DEFINE and PATTERN clauses in the query below select groups of three rows
(October 1-3, October 2-4, October 3-5, etc.).
The output of this query also illustrates that LAG() and LEAD() functions return NULL for expressions that
attempt to reference rows outside the match group (i.e. outside the window frame).
The rules for navigational functions in DEFINE clauses are slightly different from the rules for
navigational functions in MEASURES clauses. For example, the PREV() function is available in the MEASURES clause
but currently not in the DEFINE clause. Instead, you can use LAG() in the DEFINE clause. The reference
documentation for MATCH_RECOGNIZE lists the corresponding rule for each
navigational function.
The MEASURES subclause can also include the following:
-
Aggregate functions. For example, if the pattern can match a varying number of rows (e.g. because it matches 1 or more falling stock prices), then you might want to know the total number of rows in the match; you can show this by using
COUNT(*). -
General expressions that operate on values in each row in the match. These can be mathematical expressions, logical expressions, etc. For example, you could look at values in the row and print text descriptors such as “ABOVE AVERAGE”.
Remember that if you group rows (
ONE ROW PER MATCH), and if a column has different values for different rows in the group, the value selected for that column for that match is non-deterministic, and expressions based on that value are also likely to be non-deterministic.
For more information about the MEASURES subclause, see the
reference documentation for MATCH_RECOGNIZE.
Specifying Where to Search for the Next Match¶
By default, after MATCH_RECOGNIZE finds a match, it starts looking for the next match immediately after the
end of the most recent match. For example, if MATCH_RECOGNIZE finds a match in rows 2, 3, and 4, then
MATCH_RECOGNIZE will start looking for the next match at row 5. This prevents overlapping matches.
However, you can choose alternative starting points.
Consider the following data:
Suppose you search the data for a W pattern (down, up, down up). There are three W shapes:
- Months: 1, 2, 3, 4, and 5.
- Months: 3, 4, 5, 6, and 7.
- Months: 5, 6, 7, 8, and 9.
You can use the SKIP clause to specify whether you want all patterns, or only non-overlapping patterns. The
SKIP clause supports other options, as well. The SKIP clause is documented in more detail in
MATCH_RECOGNIZE.
Best Practices¶
-
Include an ORDER BY clause in your
MATCH_RECOGNIZEclause.- Remember that this ORDER BY applies only within the
MATCH_RECOGNIZEclause. If you want the entire query to return results in a specific order, then use an additionalORDER BYclause at the outermost level of the query.
- Remember that this ORDER BY applies only within the
-
Pattern variable names:
- Use meaningful pattern variable names to make your patterns easier to understand and debug.
- Check for typographical errors in pattern variable names in both the
PATTERNandDEFINEclauses.
-
Avoid using defaults for subclauses that have defaults. Make your choices explicit.
-
Test your pattern with a small sample of data before scaling up to your full data set.
-
The
MATCH_NUMBER(),MATCH_SEQUENCE_NUMBER(), andCLASSIFIER()are very helpful in debugging. -
Consider using an
ORDER BYclause in the outermost level of the query to force the output to be in order by usingMATCH_NUMBER()andMATCH_SEQUENCE_NUMBER(). If the output data is in another order, then the output might not appear to match the pattern.
Avoiding Analytic Errors¶
Correlation vs Causality¶
Correlation does not guarantee causality. MATCH_RECOGNIZE can return “false positives” (cases where you see a
pattern, but it is just a coincidence).
Pattern matching can also result in “false negatives” (cases where there is a pattern in the real world, but the pattern does not appear in the data sample).
In most cases, finding a match (for example, finding a pattern that suggests insurance fraud) is just the first step in an analysis.
The following factors typically increase the number of false positives:
- Large data sets.
- Searching for a large number of patterns.
- Searching for short or simple patterns.
The following factors typically increase the number of false negatives.
- Small data sets.
- Not searching for all the possible relevant patterns.
- Searching for patterns that are more complex than necessary.
Order-Insensitive Patterns¶
Although most pattern matching requires that the data be in order (for example, by time), there are exceptions. For example, if a person commits insurance fraud both in an automobile accident and in a home burglary, it doesn’t matter which order the frauds occur in.
If the pattern you’re looking for is not order-sensitive, then you can use operators such as
“alternative” (|) and PERMUTE to make your searches less order-sensitive.
Examples¶
This section contains additional examples.
You can find still more examples in MATCH_RECOGNIZE.
Find Multi-Day Price Increases¶
The following query finds all the patterns in which the price of company ABCD rose two days in a row:
Demonstrate the PERMUTE Operator¶
This example demonstrates the PERMUTE operator in the pattern. Search for all upward and downward spikes in the
charts limiting the number of rising prices to two:
Demonstrate the SKIP TO NEXT ROW Option¶
This example demonstrates the SKIP TO NEXT ROW option. This query searches for W-shaped curves in each company’s chart.
The matches can overlap.
Exclusion Syntax¶
This example shows the exclusion syntax in the pattern. This pattern (like the previous pattern) searches for
W shapes, but this query’s output excludes falling prices. Note that in this query, matching continues past the
last row of a match:
Search for Patterns in Non-Adjacent Rows¶
In some situations, you might want to look for patterns in non-contiguous rows. For example, if you are analyzing log files, you might want to search for all patterns in which a fatal error was preceded by a particular sequence of warnings. There might not be a natural way to partition and sort the rows so that all of the relevant messages (rows) are in a single window and adjacent. In that situation, you might need a pattern that looks for particular events, but doesn’t require that the events be contiguous in the data.
Below is an example of DEFINE and PATTERN clauses that recognizes either contiguous or non-contiguous
rows that fit the pattern. The symbol ANY_ROW is defined as TRUE (so it matches any row). The * after each
occurrence of ANY_ROW says to allow 0 or more of occurrences of ANY_ROW between the first warning and the
second warning, and between the second warning and the fatal error log message. Thus the entire pattern says to
search for WARNING1, followed by any number of rows, followed by WARNING2, followed by any number of rows,
followed by FATAL_ERROR. To omit the irrelevant rows from the output, the query uses
exclusion syntax ({- and -}).
Troubleshooting¶
Errors When Using ONE ROW PER MATCH and Specifying Columns in the Select Clause¶
The ONE ROW PER MATCH clause acts similarly to an aggregate function. This limits the output columns you can
use. For example, if you use ONE ROW PER MATCH and each match contains three rows with different dates, then
you can’t specify the date column as an output column in the SELECT clause because no single date is correct for all
three rows.
Unexpected Results¶
-
Check for typographical errors in the
PATTERNandDEFINEclauses.If a pattern variable name used in the
PATTERNclause is not defined in theDEFINEclause (e.g. because the name is typed incorrectly in either thePATTERNorDEFINEclause), then no error is reported. Instead, the pattern variable name is simply assumed to be true for each row. -
Review the
SKIPclause to make sure that it is appropriate, for example to include or exclude overlapping patterns.