Snowpark Migration Accelerator:SMA実行ガイド¶
PySpark 入力¶
SMAチェックポイント機能は、PySpark DataFramesの使用を検出することに依存するため、そのエントリーポイントとしてPySparkワークロードを必要とします。このウォークスルーでは、Pythonスクリプトを1つ使用して、チェックポイントがどのように生成され、典型的なPySparkワークフローで利用されるかのわかりやすい例を示しながら、この機能を説明します。
入力ワークロード

Sample.pyファイルの内容
ワークロードの移行¶
有効機能¶
If the SMA-Checkpoints feature is enabled, a checkpoints.json file will be generated. If the feature is disabled, this file will not be created in either the input or output folders. Regardless of whether the feature is enabled, the following inventory files will always be generated: DataFramesInventory.csv and CheckpointsInventory.csv. These files provide metadata essential for analysis and debugging.
変換プロセス¶
To create a convert your own project please follow up the following guide: SMA User Guide.
SMA-チェックポイント機能設定¶
As part of the conversion process you can customize your conversion settings, take a look on the SMA-Checkpoints feature settings.
注意: このユーザーガイドでは、デフォルトの変換設定を使用しています。
変換結果¶
Once the migration process is complete, the SMA-Checkpoints feature should have created two new inventory files and added a checkpoints.json file to both the input and output folders.
Take a look on SMA-Checkpoints inventories to review the related inventories.
入力フォルダー¶
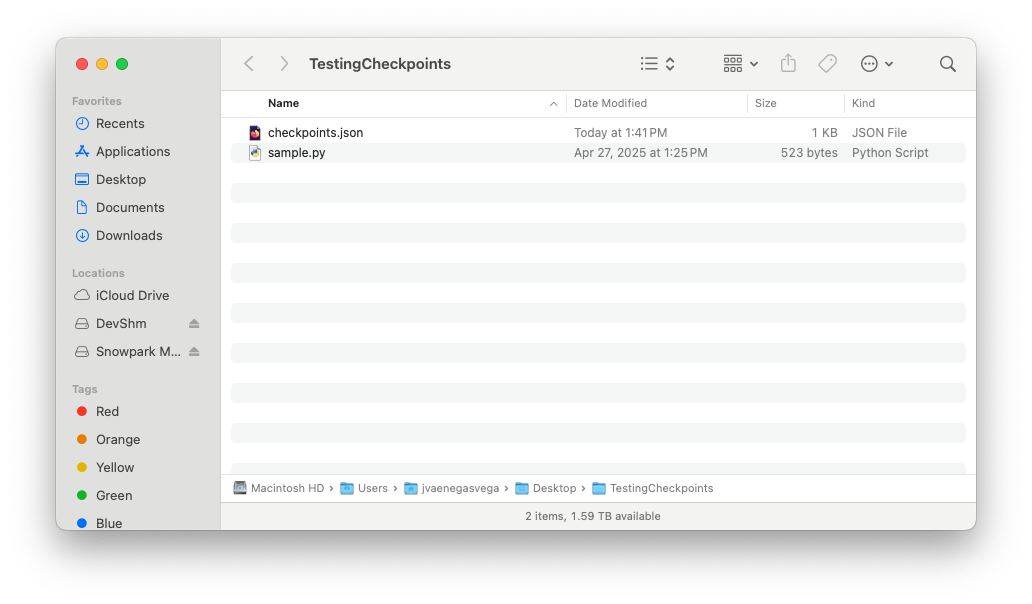
checkpoints.jsonファイルの内容
出力フォルダー¶
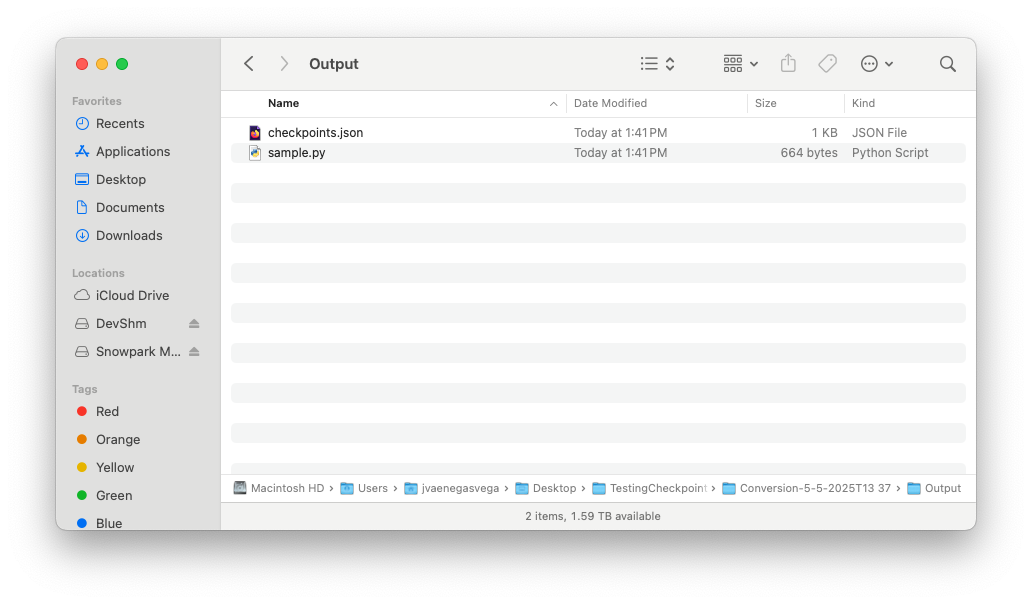
checkpoints.jsonファイルの内容
Once the SMA execution flow is complete and both the input and output folders contain their respective checkpoints.json files, you are ready to begin the Snowpark-Checkpoints execution process.