Code in Snowflake Notebooks entwickeln und ausführen¶
Dieses Thema beschreibt, wie Sie SQL, Python und Markdown-Code in Snowflake Notebooks schreiben und ausführen.
Grundlagen zu Notebook-Zellen¶
In diesem Abschnitt werden einige grundlegende Zelloperationen vorgestellt. Wenn Sie ein Notebook erstellen, werden drei Beispielzellen angezeigt. Sie können diese Zellen ändern oder neue Zellen hinzufügen.
Neue Zelle erstellen¶
Snowflake Notebooks unterstützt drei Typen von Zellen: SQL, Python und Markdown. Um eine neue Zelle zu erstellen, können Sie entweder mit dem Mauszeiger über eine vorhandene Zelle fahren oder an den unteren Rand des Notebooks scrollen und dann eine der Schaltflächen für den Zellentyp auswählen, den Sie hinzufügen möchten.

Ändern Sie die Sprache einer vorhandenen Zelle, indem Sie eine der folgenden Methoden verwenden:
Öffnen Sie das Dropdown-Menü mit den Sprachen, und wählen Sie eine andere Sprache aus.
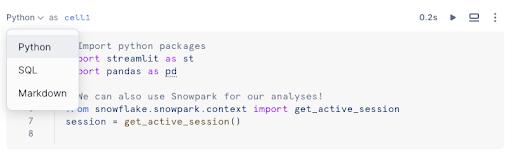
Verwenden Sie Tastaturkürzel.
Eine Zelle bearbeiten¶
Um Bearbeitungskonflikte zu vermeiden, kann jeweils nur ein Benutzer eine Zelle bearbeiten. Wenn ein anderer Benutzer versucht, eine aktive Zelle zu bearbeiten, wird eine Benachrichtigung angezeigt. Die Zelle wird nach 60 Sekunden Inaktivität zur Bearbeitung freigegeben.
Zellen verschieben¶
Sie können eine Zelle entweder durch Ziehen und Ablegen mit der Maus oder über das Aktionsmenü verschieben:
(Option 1) Bewegen Sie die Maus über die Zelle, die Sie verschieben möchten. Wählen Sie das Symbol
 (Ziehen und Ablegen) auf der linken Seite der Zelle, und verschieben Sie die Zelle an ihren neuen Speicherort.
(Ziehen und Ablegen) auf der linken Seite der Zelle, und verschieben Sie die Zelle an ihren neuen Speicherort.(Option 2) Wählen Sie das vertikale Ellipsenmenü
 (Aktionsmenü) aus. Wählen Sie dann die entsprechende Aktion aus.
(Aktionsmenü) aus. Wählen Sie dann die entsprechende Aktion aus.
Bemerkung
Um den Fokus zwischen Zellen zu verschieben, verwenden Sie die Pfeile Up und Down.
Zelle löschen¶
Um eine Zelle zu löschen, führen Sie die folgenden Schritte in einem Notebook aus:
Wählen Sie das vertikale Ellipsenmenü
(weitere Aktionen) aus.Wählen Sie Delete aus.
Wählen Sie zur Bestätigung erneut Delete aus.
Sie können auch das Tastaturkürzel verwenden, um eine Zelle zu löschen.
Hinweise bei Verwendung von Python- und SQL-Zellen finden Sie unter Hinweise zum Ausführen von Notebooks.
Zellen in Snowflake Notebooks ausführen¶
Um Python- und SQL-Zellen in Snowflake Notebooks auszuführen, haben Sie folgende Optionen:
Einzelne Zelle ausführen: Wählen Sie diese Option, wenn Sie den Code häufig aktualisieren.
Drücken Sie CMD + Return auf einer Mac-Tastatur oder CTRL + Enter auf einer Windows-Tastatur.
Wählen Sie
 oder Run this cell only aus.
oder Run this cell only aus.
Führen Sie alle Zellen in einem Notebook in sequenzieller Reihenfolge aus: Wählen Sie diese Option, bevor Sie ein Notebook präsentieren oder weitergeben, um sicherzustellen, dass die Empfänger die aktuellsten Informationen sehen. Mit dieser Option werden alle SQL- und Python-Codezellen im Notebook von oben nach unten ausgeführt. Wenn in einer Zelle ein Fehler auftritt, wird die Ausführung angehalten und die nachfolgenden Zellen werden nicht ausgeführt. Diese Verhaltensweise gilt auch für geplante Notebooks. Wenn Sie zum Beispiel ein Notebook mit 10 Zellen ausführen und in Zelle 2 ein SQL-Syntaxfehler auftritt, wird das Notebook nach Zelle 2 angehalten.
Drücken Sie CMD + Shift + Return auf einer Mac-Tastatur oder CTRL + Shift + Enter auf einer Windows-Tastatur.
Wählen Sie Run all aus.
Eine Zelle ausführen und zur nächsten Zelle weitergehen: Wählen Sie diese Option, um eine Zelle auszuführen und schneller zur nächsten Zelle weiterzugehen.
Drücken Sie Shift + Return auf einer Mac-Tastatur oder Shift + Enter auf einer Windows-Tastatur.
Öffnen Sie das vertikale Ellipsenmenü
(weitere Aktionen) der Zelle, und wählen Sie Run cell and advance aus.
Alle obigen ausführen: Wählen Sie diese Option, wenn Sie eine Zelle ausführen, die auf die Ergebnisse vorheriger Zellen verweist.
Öffnen Sie das vertikale Ellipsenmenü
(weitere Aktionen) der Zelle, und wählen Sie Run all above aus.
Alle unten ausführen: Wählen Sie diese Option, wenn Sie eine Zelle ausführen, von der nachfolgende Zellen abhängen. Mit dieser Option werden die aktuelle Zelle und alle folgenden Zellen ausgeführt.
Öffnen Sie das vertikale Ellipsenmenü
(weitere Aktionen) der Zelle, und wählen Sie Run all below aus.
Wenn eine Zelle ausgeführt wird, werden andere Ausführungsanforderungen in eine Warteschlange eingefügt und ausgeführt, sobald die gerade aktive Zelle fertig ist.
Zellen komprimieren und erweitern¶
Sie können steuern, wie viel vom Notebook sichtbar ist, indem Sie eine der Zellenanzeigeoptionen oben im Notebook auswählen:
Wählen Sie das vertikale Ellipsenmenü
(weitere Aktionen) aus.Wählen Sie Show/hide all und wählen Sie die entsprechende Option:
Alles anzeigen: Zeigt sowohl den Code als auch die Ergebnisse für jede Zelle an.
Nur Code anzeigen: Blendet die Ergebnisse aus und zeigt nur die Codezellen an.
Nur Ergebnisse anzeigen: Blendet den Code aus und zeigt nur die Ausgabe an.
Alle ausblenden: Blendet sowohl den Code als auch die Ergebnisse für alle Zellen aus.
Diese Optionen sind hilfreich, wenn:
Sie sich auf das Lesen von Code oder die Überprüfung von Ergebnissen konzentrieren möchten.
Sie Ihr Notebook präsentieren oder teilen.
Sie effizienter durch große Notebooks navigieren müssen.
Zellen duplizieren¶
Die Duplizierung einer Zelle kann bei Folgendem helfen:
Testen von Varianten einer Abfrage oder Funktion.
Fehlersuche ohne Überschreiben der Arbeitsversion.
Vergleichen von verschiedenen Ausgaben nebeneinander.
Wiederverwendung von Code oder Änderung einer bestehenden Zelle ohne Verlust des Originals.
So duplizieren Sie eine Notebook-Zelle:
Wählen Sie in der Zelle, die Sie duplizieren möchten, das vertikale Ellipsenmenü
(weitere Aktionen).Wählen Sie Duplicate aus.
Eine Kopie der Zelle erscheint direkt unter dem Original.
Zellen-Minikarte¶
Die Zellen-Minikarte erscheint in der rechten Seitenleiste des Notebooks und bietet eine kompakte, verschiebbare Liste aller Zellen im Notebook. Jeder Eintrag in der Minikarte entspricht einem Code oder einer Textzelle und spiegelt die Reihenfolge wider, in der die Zellen erscheinen.
Aktuelle Zelle: Die ausgewählte Zelle wird auf der Minikarte hervorgehoben.
Neu anordnen: Ziehen Sie Elemente in die Minikarte und legen Sie sie dort ab, um die Reihenfolge der Zellen im Notebook schnell zu ändern.
Navigation: Klicken Sie auf einen Zellennamen in der Minikarte, um direkt zu dieser Zelle zu springen.
Dieses Feature ist nützlich, um in großen Notebooks zu navigieren und Inhalte effizienter zu reorganisieren.
Ausführen von Notebooks mit Parametern¶
Wenn Sie den EXECUTE NOTEBOOK-Befehl verwenden, um ein Notebook zu starten, können Sie Argumente an das Notebook übergeben. In einer Python-Zelle im Notebook können Sie auf diese Argumente zugreifen, indem Sie die Variable sys.argv verwenden, die eine in Python integrierte Liste ist, die Befehlszeilenargumente enthält.
Durch die Übergabe von Argumenten an Notebooks können Sie das Notebook-Verhalten anpassen. Sie können Folgendes tun:
Personalisieren oder Anpassen der Ausführung des Notebooks
Wiederverwenden desselben Notebooks für mehrere Eingaben
Unterstützung von Automatisierung oder Aufgabenplanung
Beispiele¶
In einer Python-Zelle im Notebook können Sie auf die Argumente zugreifen, indem Sie die sys.argv-Variable verwenden.
Anzeigen aller an das Notebook übergebenen Argumente¶
Ausgabe der vollständigen Liste der an das Notebook übergebenen Argumente
Wenn das Notebook mit diesem Befehl ausgeführt wird:
Lautet die Ausgabe:
Jedes Argument wird ausgegeben¶
Jedes Argument wird einzeln durchlaufen und ausgegeben
Lautet die Ausgabe:
Zugriff auf ein bestimmtes Argument¶
Greifen Sie auf das zweite Argument zu.
Lautet die Ausgabe:
Analysieren eines Arguments, das durch Komma getrennte Werte enthält¶
Wenn ein Argument eine durch Kommas getrennte Liste von Werten enthält, können Sie diese in einzelne Werte aufteilen.
Lautet die Ausgabe:
Sie können die Werte auch mit einer Schleife durchlaufen:
Extrahieren eines Arguments, das ein Schlüssel-Wert-Paar enthält¶
Wenn ein Argument ein Schlüssel-Wert-Paar enthält (z. B. key=value), wird der Wert extrahiert.
Lautet die Ausgabe:
Alternative Syntax für eine einzelne Zeichenfolge¶
Sie können eine Sitzungsvariable auf den Wert eines Arguments einstellen und die Sitzungsvariable an das Notebook übergeben.
Anzeigen der Ergebnisse einer parametrisierten Ausführung¶
So zeigen Sie das Ergebnis einer Notebook-Ausführung an, die mit EXECUTE NOTEBOOK ausgelöst wurde:
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Projects » Notebooks aus.
Wählen Sie das Symbol Calendar aus.
Wählen Sie View run history aus.
Suchen Sie die Notebook-Ausführung und öffnen Sie das Ergebnis.
Es wird ein schreibgeschütztes Notebook geöffnet, welches das Ergebnis dieser Ausführung enthält.
Anmerkungen¶
sys.argventhält nur die mit EXECUTE NOTEBOOK übergebenen Zeichenfolgen.Es werden nur Zeichenfolgen unterstützt. Wenn ein anderer Datentyp (z. B. eine Ganzzahl) übergeben wird, wird dies als NULL interpretiert. Weitere Informationen dazu finden Sie unter EXECUTE NOTEBOOK.
Zellenstatus prüfen¶
Der Status der Zellenausführung wird durch die Farbe der Zelle angezeigt. Diese Statusfarbe wird an zwei Stellen angezeigt: an der linken Seite der Zelle und in der rechten Zellennavigationskarte.
Zellenstatusfarbe:
Blauer Punkt: Die Zelle wurde geändert, aber noch nicht ausgeführt.
Rot: Die Zelle wurde in der aktuellen Sitzung ausgeführt und es ist ein Fehler aufgetreten.
Grün: Die Zelle wurde in der aktuellen Sitzung ohne Fehler ausgeführt.
Bewegtes Grün: Zelle wird gerade ausgeführt.
Grau: Die Zelle wurde in einer vorherigen Sitzung ausgeführt und die angezeigten Ergebnisse stammen aus der vorherigen Sitzung. Die Zellenergebnisse der letzten interaktiven Sitzung werden 7 Tage lang aufbewahrt. Interaktive Sitzung bedeutet, dass der Benutzer das Notebook in Snowsight interaktiv ausführt und nicht über einen Zeitplan oder den SQL-Befehl EXECUTE NOTEBOOK.
Blinkt grau: Die Zelle wartet darauf, ausgeführt zu werden, nachdem Sie Run All gewählt haben.
Bemerkung
Markdown-Zellen zeigen keinen Status an.
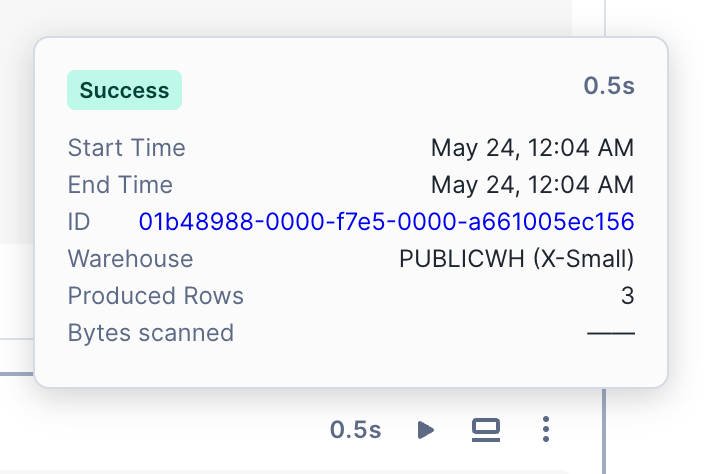
Nachdem eine Zelle ausgeführt wurde, wird die dafür benötigte Zeit oben in der Zelle angezeigt. Wählen Sie diesen Text, um die Ausführungsdetails anzuzeigen, einschließlich der Start- und Endzeit und der verstrichenen Gesamtzeit.
SQL-Zellen enthalten zusätzliche Informationen, z. B. das Warehouse, das für die Abfrage verwendet wurde, die zurückgegebenen Zeilen und einen Hyperlink zur Abfrage-ID-Seite.
In Ausführung befindliche Zelle stoppen¶
Um die Ausführung von Codezellen, die gerade ausgeführt werden, zu stoppen, wählen Sie Stop oben rechts in der Zelle. Sie können auch Stop oben rechts auf der Notebooks-Seite auswählen. Während die Zellen laufen, wird Run all zu Stop.
Dies stoppt die Ausführung der gerade ausgeführten Zelle und aller nachfolgenden Zellen, die für die Ausführung geplant wurden.
Tastaturkürzel¶
Snowflake Notebooks unterstützen verschiedene Tastaturkürzel, um Ihren Entwicklungsprozess zu beschleunigen.
Sie können die Liste der Tastenkombinationen auch anzeigen, indem Sie auf das Tastatursymbol in der unteren rechten Ecke und dann auf Keyboard shortcuts klicken.
Aufgabe |
MacOS |
Windows |
|---|---|---|
Alle Zellen ausführen |
CMD + Shift + Return |
CTRL + Shift + Enter |
Ausgewählte Zelle ausführen |
CMD + Return |
CTRL + Enter |
Ausgewählte Zelle ausführen und zur nächsten Zelle wechseln |
Shift + Return |
Shift + Enter |
Zwischen Zellen bewegen |
Pfeile Nach oben und Nach unten |
Pfeile Nach oben und Nach unten |
Alle Zellen anhalten |
ii |
ii |
Innerhalb der Zelle suchen |
CMD + f |
CTRL + f |
Zelle nach oben verschieben |
CMD + SHIFT + Nach oben Pfeil |
CTRL + SHIFT + Nach oben Pfeil |
Zelle nach unten verschieben |
CMD + SHIFT + Pfeil nach unten |
CTRL + SHIFT + Pfeil nach unten |
Zelle oberhalb der aktuell ausgewählten Zelle hinzufügen |
a |
a |
Zelle unterhalb der aktuell ausgewählten Zelle hinzufügen |
b |
b |
Aktuell ausgewählte Zelle löschen |
dd oder DELETE |
dd oder DELETE |
SQL- oder Python-Zelle in Markdown-Zelle konvertieren |
m |
m |
Zelle in Codezelle konvertieren:
|
y |
y |
Tastaturkürzel anzeigen |
Verschiebung + ? |
Verschiebung + ? |
Darüber hinaus können Sie dieselben Tastenkombinationen verwenden, die Sie auch für Arbeitsblätter nutzen. Siehe Aufgaben mit Tastaturkürzeln ausführen.
Text mit Markdown formatieren¶
Um Markdown in Ihr Notebook aufzunehmen, fügen Sie eine Markdown-Zelle hinzu:
Verwenden Sie das Tastaturkürzel, und wählen Sie Markdown aus, oder wählen Sie + Markdown aus.
Wählen Sie das Stiftsymbol Edit markdown oder doppelklicken Sie auf die Zelle und beginnen Sie mit dem Schreiben von Markdown.
Sie können gültiges Markdown eingeben, um eine Textzelle zu formatieren. Während Sie tippen, wird der formatierte Text unter der Markdown-Syntax angezeigt.
Um nur den formatierten Text anzuzeigen, wählen Sie das Symbol Done editing.

Bemerkung
Markdown-Zellen unterstützen derzeit nicht das Rendern von HTML.
Markdown-Grundlagen¶
Dieser Abschnitt beschreibt die grundlegende Syntax von Markdown, um Ihnen den Einstieg zu erleichtern.
Kopfzeilen
Überschriftebene |
Markdown-Syntax |
Beispiel |
|---|---|---|
Oberste Ebene |

|
|
2nd-level |

|
|
3rd-level |

|
Inline Textformatierung
Textformat |
Markdown-Syntax |
Beispiel |
|---|---|---|
Kursiv |

|
|
Fett |

|
|
Verknüpfung |

|
Listen
Listentyp |
Markdown-Syntax |
Beispiel |
|---|---|---|
Geordnete Liste |

|
|
Ungeordnete Liste |

|
Code-Formatierung
Sprache |
Markdown-Syntax |
Beispiel |
|---|---|---|
Python |
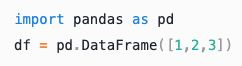
|
|
SQL |

|
Bilder einbetten
Dateityp |
Markdown-Syntax |
Beispiel |
|---|---|---|
Bild |

|
Ein Notebook, das diese Markdown-Beispiele veranschaulicht, finden Sie im Abschnitt Markdown-Zellen des Notebooks „Visuelle Daten-Storys“.
Erläuterungen zu Zellausgaben¶
Wenn Sie eine Python-Zelle ausführen, zeigt das Notebook die folgenden Arten von Ausgaben der Zelle in den Ergebnissen an:
Alle Ergebnisse, die in die Konsole geschrieben werden, wie z. B. Protokolle, Fehler und Warnungen sowie Ausgaben von print()-Anweisungen.
DataFrames werden automatisch mit der interaktiven Tabellenanzeige von Streamlit,
st.dataframe()gedruckt.Zu den unterstützten DataFrame-Anzeigetypen gehören pandas DataFrame, Snowpark DataFrames und Snowpark-Tabellen.
Für Snowpark werden DataFrames im Eager-Modus ausgewertet, ohne dass Sie den Befehl
.show()ausführen müssen. Wenn Sie es vorziehen, DataFrame nicht im Eager-Modus auszuwerten, z. B. wenn Sie das Notebook im nicht-interaktiven Modus ausführen, empfiehlt Snowflake, die DataFrame print-Anweisungen zu entfernen, um die Laufzeit Ihres Snowpark-Codes insgesamt zu beschleunigen.
Visualisierungen werden in Ausgaben gerendert. Wenn Sie mehr über die Visualisierung Ihrer Daten erfahren möchten, besuchen Sie Daten in Snowflake Notebooks visualisieren.
Außerdem können Sie auf die Ergebnisse Ihrer SQL-Abfrage in Python zugreifen und umgekehrt. Siehe Zellen und Variablen in Snowflake Notebooks referenzieren.
Grenzen der Zellenausgabe¶
Es werden nur 10.000 Zeilen oder 8 MB der DataFrame-Ausgabe als Zellenergebnisse angezeigt, je nachdem, welcher Wert niedriger ist. Der gesamte DataFrame steht jedoch weiterhin in der Notebook-Sitzung zur Verwendung zur Verfügung. Auch wenn beispielsweise nicht der gesamte DataFrame gerendert wird, können Sie dennoch Datentransformationsaufgaben durchführen.
Für jede Zelle ist nur eine Ausgabe von 20 MB erlaubt. Wenn die Größe der Zellenausgabe 20 MB überschreitet, wird die Ausgabe verworfen. Ziehen Sie in Erwägung, den Inhalt in mehrere Zellen aufzuteilen, wenn dies geschieht.
Zellen und Variablen in Snowflake Notebooks referenzieren¶
Sie können die Ergebnisse der vorherigen Zelle in einer Notebook-Zelle referenzieren. Wenn Sie beispielsweise auf das Ergebnis einer SQL-Zelle oder den Wert einer Python-Variablen verweisen möchten, lesen Sie die folgenden Tabellen:
Bemerkung
Beim Zellnamen des Verweises wird zwischen Groß- und Kleinschreibung unterschieden, und er muss genau mit dem Namen der referenzierten Zelle übereinstimmen.
Referenzieren von SQL-Ausgaben in Python-Zellen:
Typ der Referenzzelle |
Typ der aktuellen Zelle |
Referenz-Syntax |
Beispiel |
|---|---|---|---|
SQL |
Python |
|
Konvertieren Sie eine SQL-Ergebnistabelle in einen Snowpark-DataFrame. Wenn eine SQL-Zelle namens Sie können auf die Zelle verweisen, um auf das SQL-Ergebnis zuzugreifen: Sie können das Ergebnis in einen Pandas-DataFrame konvertieren: |
Referenzieren von Variablen im SQL-Code:
Wichtig
In SQL-Code können Sie nur auf Python-Variablen vom Typ string verweisen. Sie können nicht auf ein Snowpark DataFrame-, pandas DataFrame- oder ein anderes natives Python DataFrame-Format verweisen.
Typ der Referenzzelle |
Typ der aktuellen Zelle |
Referenz-Syntax |
Beispiel |
|---|---|---|---|
SQL |
SQL |
|
Beispiel: In SQL-Zelle namens |
Python |
SQL |
|
Beispiel: In einer Python-Zelle namens Python-Variable als Wert verwenden Sie können den Wert der Variablen Python-Variable als Bezeichner verwenden Wenn die Python-Variable einen SQL-Bezeichner wie einen Spalten- oder Tabellennamen darstellt: Wenn die Python-Variable einen SQL-Bezeichner darstellt, wie z. B. einen Spalten- oder Tabellennamen ( Achten Sie darauf, zwischen Variablen, die als Werte (mit Anführungszeichen) und als Bezeichner (ohne Anführungszeichen) verwendet werden, zu unterscheiden. Hinweis: Ein Verweis auf Python DataFrames wird nicht unterstützt. |
Hinweise zum Ausführen von Notebooks¶
Notebooks werden mit Aufruferrechten ausgeführt. Weitere Hinweise finden Sie unter Ändern des Sitzungskontexts für ein Notebook.
Sie können Python-Bibliotheken importieren, um sie in einem Notebook zu verwenden. Weitere Details dazu finden Sie unter Python-Pakete zur Verwendung in Notebooks importieren.
Wenn Sie auf Objekte in SQL-Zellen verweisen, müssen Sie vollqualifizierte Objektnamen verwenden, es sei denn, Sie verweisen auf Objektnamen in einer bestimmten Datenbank oder einem bestimmten Schema. Siehe Ändern des Sitzungskontexts für ein Notebook.
Notebook-Entwürfe werden alle drei Sekunden gespeichert.
Sie können Git-Integration verwenden, um Notebook-Versionen zu verwalten.
Sie können eine Timeout-Einstellung für den Leerlauf konfigurieren, um die Notebook-Sitzung automatisch zu beenden, sobald die Einstellung erreicht ist. Weitere Informationen dazu finden Sie unter Leerlaufzeit und Wiederherstellung der Verbindung.
Die Ergebnisse der Notebookzellen sind nur für den Benutzer sichtbar, der das Notebook ausgeführt hat, und sie werden sitzungsübergreifend zwischengespeichert. Beim erneuten Öffnen eines Notebooks werden die Ergebnisse angezeigt, die beim letzten Aufruf des Notebooks durch den Benutzer über die Snowsight erzielt wurden.
BEGIN … END (Snowflake Scripting) wird in SQL-Zellen nicht unterstützt. Verwenden Sie stattdessen die Methode Session.sql().collect() in einer Python-Zelle, um den Scripting-Block auszuführen. Verketten Sie den Aufruf
sqlmit einem Aufrufcollect, um die SQL-Abfrage sofort auszuführen.Der folgende Code führt einen Snowflake Scripting-Block mit der Methode
session.sql().collect()aus: