SnowConvert: Transact DMLs¶
Between¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Source Code
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcBetween
AS
BEGIN
declare @aValue int = 1;
IF(@aValue BETWEEN 1 AND 2)
return 1
END;
GO
Code Expected
CREATE OR REPLACE PROCEDURE ProcBetween ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let AVALUE = 1;
if (SELECT(` ? BETWEEN 1 AND 2`,[AVALUE])) {
return 1;
}
$$;
Known Issues ¶
No issues were found.
Bulk Insert¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
The direct translation for BULK INSERT is the Snowflake COPY INTO statement. The COPY INTO does not use directly the file path to retrieve the values. The file should exist before in a STAGE. Also the options used in the BULK INSERT should be specified in a Snowflake FILE FORMAT that will be consumed by the STAGE or directly by the COPY INTO.
To add a file to some STAGE you should use the PUT command. Notice that the command can be executed only from the SnowSQL CLI. Here is an example of the steps we should do before executing a COPY INTO:
-- Additional Params: -t JavaScript
CREATE PROCEDURE PROCEDURE_SAMPLE
AS
CREATE TABLE #temptable
([col1] varchar(100),
[col2] int,
[col3] varchar(100))
BULK INSERT #temptable FROM 'C:\test.txt'
WITH
(
FIELDTERMINATOR ='\t',
ROWTERMINATOR ='\n'
);
GO
CREATE OR REPLACE FILE FORMAT FILE_FORMAT_638434968243607970
FIELD_DELIMITER = '\t'
RECORD_DELIMITER = '\n';
CREATE OR REPLACE STAGE STAGE_638434968243607970
FILE_FORMAT = FILE_FORMAT_638434968243607970;
--** SSC-FDM-TS0004 - PUT STATEMENT IS NOT SUPPORTED ON WEB UI. YOU SHOULD EXECUTE THE CODE THROUGH THE SNOWFLAKE CLI **
PUT file://C:\test.txt @STAGE_638434968243607970 AUTO_COMPRESS = FALSE;
CREATE OR REPLACE PROCEDURE PROCEDURE_SAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
EXEC(`CREATE OR REPLACE TEMPORARY TABLE T_temptable
(
col1 VARCHAR(100),
col2 INT,
col3 VARCHAR(100))`);
EXEC(`COPY INTO T_temptable FROM @STAGE_638434968243607970/test.txt`);
$$
As you see in the code above, SnowConvert identifies all the BULK INSERTS in the code, and for each instance, a new STAGE and FILE FORMAT will be created before the copy into execution. In addition, after the creation of the STAGE, a PUT command will be created as well in order to add the file to the stage.
The names of the generated statements are auto-generated using the current timestamp in seconds, in order to avoid collisions between their usages.
Finally, all the options for the bulk insert are being mapped to file format options if apply. If the option is not supported in Snowflake, it will be commented and a warning will be added. See also SSC-FDM-TS0004.
Supported bulk options¶
SQL Server |
Snowflake |
|---|---|
FORMAT |
TYPE |
FIELDTERMINATOR |
FIELD_DELIMITER |
FIRSTROW |
SKIP_HEADER |
ROWTERMINATOR |
RECORD_DELIMITER |
FIELDQUOTE |
FIELD_OPTIONALLY_ENCLOSED_BY |
Related EWIs¶
SSC-FDM-TS0004: PUT STATEMENT IS NOT SUPPORTED ON WEB UI.
Common Table Expression (CTE)¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Common table expressions are supported in Snowflake SQL by default.
Snowflake SQL syntax¶
Subquery:
[ WITH
<cte_name1> [ ( <cte_column_list> ) ] AS ( SELECT ... )
[ , <cte_name2> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
[ , <cte_nameN> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
]
SELECT ...
Recursive CTE:
[ WITH [ RECURSIVE ]
<cte_name1> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause )
[ , <cte_name2> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
[ , <cte_nameN> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
]
SELECT ...
Where:
anchorClause ::=
SELECT <anchor_column_list> FROM ...
recursiveClause ::=
SELECT <recursive_column_list> FROM ... [ JOIN ... ]
Noteworthy details¶
The RECURSIVE keyword does not exist in T-SQL, and the transformation does not actively add the keyword to the result. A warning is added to the output code in order to state this behavior.
Common Table Expression with SELECT INTO¶
The following transformation occurs when the WITH expression is followed by an SELECT INTO statement and it will be transformed into a TEMPORARY TABLE.
SQL Server:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2 FROM t1 poh WHERE poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employee WHERE BUSINESSENTITYID = (SELECT col1 FROM ctetable)
),
finalCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employeeCte
) SELECT * INTO #table2 FROM finalCte;
SELECT * FROM #table2;
Snowflake:
CREATE OR REPLACE TEMPORARY TABLE T_table2 AS
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
t1 poh
WHERE
poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employee
WHERE
BUSINESSENTITYID = (SELECT
col1
FROM
ctetable
)
),
finalCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employeeCte
)
SELECT
*
FROM
finalCte;
SELECT
*
FROM
T_table2;
Common Table Expression with other expressions¶
The following transformation occurs when the WITH expression is followed by INSERT or DELETE statements.
SQL Server:
WITH CTE AS( SELECT * from table1)
INSERT INTO Table2 (a,b,c,d)
SELECT a,b,c,d
FROM CTE
WHERE e IS NOT NULL;
Snowflake:
INSERT INTO Table2 (a, b, c, d)
WITH CTE AS( SELECT
*
from
table1
)
SELECT
a,
b,
c,
d
FROM
CTE AS CTE
WHERE
e IS NOT NULL;
Common Table Expression with Delete From¶
For this transformation, it will only apply for a CTE (Common Table Expression) with a Delete From, however, only for some specifics CTE. It must have only one CTE, and it must have inside a function of ROW_NUMBER or RANK.
The purpose of the CTE with the Delete must be to remove duplicates from a table. In case that the CTE with Delete intents to remove another kind of data, this transformation will not apply.
Let’s see an example. For a working example, we must first create a table with some data.
CREATE TABLE WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue NVARCHAR(258)
);
Insert into WithQueryTest values(100, 100, 'First');
Insert into WithQueryTest values(200, 200, 'Second');
Insert into WithQueryTest values(300, 300, 'Third');
Insert into WithQueryTest values(400, 400, 'Fourth');
Insert into WithQueryTest values(100, 100, 'First');
Note that there is a duplicated value. The lines 8 and 12 insert the same value. Now we are going to eliminate the duplicates rows in a table.
WITH Duplicated AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID) AS RN
FROM WithQueryTest
)
DELETE FROM Duplicated
WHERE Duplicated.RN > 1
If we execute a Select from the table, it will show the following result
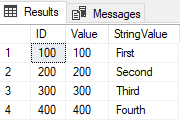
Note that there are no duplicateds rows. In order to conserve the functionality of these CTE with Delete in Snowflake, it will be transformed to
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest AS SELECT
*
FROM PUBLIC.WithQueryTest
QUALIFY ROW_NUMBER()
OVER (PARTITION BY ID ORDER BY ID) = 1 ;
As you can see, the query is transformed to a Create Or Replace Table.
Let’s try it in Snowflake, in order to test it, we need the table too.
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue VARCHAR(258)
);
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Insert into PUBLIC.WithQueryTest values(200, 200, 'Second');
Insert into PUBLIC.WithQueryTest values(300, 300, 'Third');
Insert into PUBLIC.WithQueryTest values(400, 400, 'Fourth');
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Now, if we execute the result of the transformation, and then a Select to check if the duplicated rows were deleted, this would be the result.
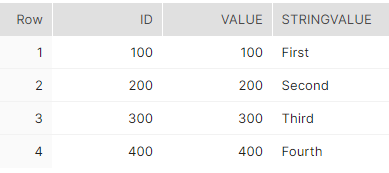
Common Table Expression with MERGE statement¶
The following transformation occurs when the WITH expression is followed by MERGE statement and it will be transformed into a MERGE INTO.
SQL Server:
WITH ctetable(col1, col2) as
(
SELECT col1, col2
FROM t1 poh
where poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT col1 FROM ctetable
)
MERGE
table1 AS target
USING finalCte AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN UPDATE SET target.ID = source.Col1
WHEN NOT MATCHED THEN INSERT (ID, col1) VALUES (source.COL1, source.COL1 );
Snowflake:
MERGE INTO table1 AS target
USING (
--** SSC-PRF-TS0001 - PERFORMANCE WARNING - RECURSION FOR CTE NOT CHECKED. MIGHT REQUIRE RECURSIVE KEYWORD **
WITH ctetable (
col1,
col2
) as
(
SELECT
col1,
col2
FROM
t1 poh
where
poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT
col1
FROM
ctetable
)
SELECT
*
FROM
finalCte
) AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN
UPDATE SET
target.ID = source.Col1
WHEN NOT MATCHED THEN
INSERT (ID, col1) VALUES (source.COL1, source.COL1);
Common Table Expression with UPDATE statement¶
The following transformation occurs when the WITH expression is followed by an UPDATE statement and it will be transformed into an UPDATE statement.
SQL Server:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2
FROM table2 poh
WHERE poh.col1 = 5 and poh.col2 = 4
)
UPDATE tab1
SET ID = 8, COL1 = 8
FROM table1 tab1
INNER JOIN ctetable CTE ON tab1.ID = CTE.col1;
Snowflake:
UPDATE dbo.table1 tab1
SET
ID = 8,
COL1 = 8
FROM
(
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
table2 poh
WHERE
poh.col1 = 5 and poh.col2 = 4
)
SELECT
*
FROM
ctetable
) AS CTE
WHERE
tab1.ID = CTE.col1;
Known Issues ¶
No issues were found.
Related EWIs¶
SSC-EWI-0108: The following subquery matches at least one of the patterns considered invalid and may produce compilation errors.
SSC-PRF-TS0001: Performance warning - recursion for CTE not checked. Might require a recursive keyword.
Delete¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Description¶
Removes one or more rows from a table or view in SQL Server. For more information regarding SQL Server Delete, check here.
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}
Sample Source Patterns ¶
The transformation for the DELETE statement is fairly straightforward, with some caveats. One of these caveats is the way Snowflake supports multiple sources in the FROM clause, however, there is an equivalent in Snowflake as shown below.
SQL Server
DELETE T1 FROM TABLE2 T2, TABLE1 T1 WHERE T1.ID = T2.ID
Snowflake
DELETE FROM
TABLE1 T1
USING TABLE2 T2
WHERE
T1.ID = T2.ID;
Note
Note that, since the original DELETE was for T1, the presence of TABLE2 T2 in the FROM clause requires the creation of the USING clause.
¶
Delete duplicates from a table¶
The following documentation explains a common pattern used to remove duplicated rows from a table in SQL Server. This approach uses the ROW_NUMBER function to partition the data based on the key_value which may be one or more columns separated by commas. Then, delete all records that received a row number value that is greater than 1. This value indicates that the records are duplicates. You can read the referenced documentation to understand the behavior of this method and recreate it.
DELETE T
FROM
(
SELECT *
, DupRank = ROW_NUMBER() OVER (
PARTITION BY key_value
ORDER BY ( {expression} )
)
FROM original_table
) AS T
WHERE DupRank > 1
The following example uses this approach to remove duplicates from a table and its equivalent in Snowflake. The transformation consists of performing an INSERT OVERWRITE statement which truncates the table (removes all data) and then inserts again the rows in the same table ignoring the duplicated ones. The output code is generated considering the same PARTITION BY and ORDER BY clauses used in the original code.
SQL Server
Create a table with duplicated rows
create table duplicatedRows(
someID int,
col2 bit,
col3 bit,
col4 bit,
col5 bit
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
Remove duplicated rows
DELETE f FROM (
select someID, row_number() over (
partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc
) as rownum
from
duplicatedRows
) f where f.rownum > 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Snowflake
Create a table with duplicated rows
create table duplicatedRows(
someID int,
col2 BOOLEAN,
col3 BOOLEAN,
col4 BOOLEAN,
col5 BOOLEAN
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
Remove duplicated rows
insert overwrite into duplicatedRows
SELECT
*
FROM
duplicatedRows
QUALIFY
ROW_NUMBER()
over
(partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc) = 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Warning
Consider that there may be several variations of this pattern, but all of them are based on the same principle and have the same structure.
Known Issues¶
No issues were found.
Related EWIs¶
No related EWIs.
Drops¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
DROP TABLE¶
Syntax in Transact-SQL¶
DROP TABLE [ IF EXISTS ] <table_name> [ ,...n ]
[ ; ]
Syntax in Snowflake¶
DROP TABLE [ IF EXISTS ] <name> [ CASCADE | RESTRICT ]
Translation¶
Translation for single DROP TABLE statements is very straightforward. As long as there is only one table being dropped within the statement, it’s left as-is.
For example:
DROP TABLE IF EXISTS [table_name]
DROP TABLE IF EXISTS table_name;
The only noteworthy difference between SQL Server and Snowflake appears when the input statement drops more than one table. In these scenarios, a different DROP TABLE statement is created for each table being dropped.
For example:
DROP TABLE IF EXISTS [table_name], [table_name2], [table_name3]
DROP TABLE IF EXISTS table_name;
DROP TABLE IF EXISTS table_name2;
DROP TABLE IF EXISTS table_name3;
Known Issues ¶
No issues were found.
Related EWIs ¶
No related EWIs.
Exists¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Types of Subqueries¶
Subqueries can be categorized as correlated or uncorrelated:
A correlated subquery, refers to one or more columns from outside of the subquery. (The columns are typically referenced inside the WHERE clause of the subquery.) A correlated subquery can be thought of as a filter on the table that it refers to, as if the subquery were evaluated on each row of the table in the outer query.
An uncorrelated subquery, has no such external column references. It is an independent query, the results of which are returned to and used by the outer query once (not per row).
The EXISTS statement is considered a correlated subquery.
Source Code
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcExists
AS
BEGIN
IF(EXISTS(Select AValue from ATable))
return 1;
END;
Expected Code
CREATE OR REPLACE PROCEDURE ProcExists ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
if (SELECT(` EXISTS(Select
AValue
from
ATable
)`)) {
return 1;
}
$$;
Known Issues ¶
No issues were found.
Related EWIs ¶
No related EWIs.
IN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
The IN operator checks if an expression is included in the values returned by a subquery.
Source Code
-- Additional Params: -t JavaScript
CREATE PROCEDURE dbo.SP_IN_EXAMPLE
AS
DECLARE @results as VARCHAR(50);
SELECT @results = COUNT(*) FROM TABLE1
IF @results IN (1,2,3)
SELECT 'is IN';
ELSE
SELECT 'is NOT IN';
return
GO
-- =============================================
-- Example to execute the stored procedure
-- =============================================
EXECUTE dbo.SP_IN_EXAMPLE
GO
Expected Code
CREATE OR REPLACE PROCEDURE dbo.SP_IN_EXAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let RESULTS;
SELECT(` COUNT(*) FROM
TABLE1`,[],(value) => RESULTS = value);
if ([1,2,3].includes(RESULTS)) {
} else {
}
return;
$$;
-- =============================================
-- Example to execute the stored procedure
-- =============================================
CALL dbo.SP_IN_EXAMPLE();
Known Issues ¶
No issues were found.
Related EWIs ¶
No related EWIs.
Insert¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Description¶
Adds one or more rows to a table or a view in SQL Server. For more information regarding SQL Server Insert, check here.
Syntax comparison¶
The basic insert grammar is equivalent between both SQL languages. However there are still some other syntax elements in SQL Server that show differences, for example, one allows the developer to add a value to a column by using the assign operator. The syntax mentioned will be transformed to the basic insert syntax too.
Snowflake
INSERT [ OVERWRITE ] INTO <target_table> [ ( <target_col_name> [ , ... ] ) ]
{
VALUES ( { <value> | DEFAULT | NULL } [ , ... ] ) [ , ( ... ) ] |
<query>
}
SQL Server
[ WITH <common_table_expression> [ ,...n ] ]
INSERT
{
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ]
{ <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
{
[ ( column_list ) ]
[ <OUTPUT Clause> ]
{ VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) [ ,...n ]
| derived_table
| execute_statement
| <dml_table_source>
| DEFAULT VALUES
}
}
}
[;]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name
}
<dml_table_source> ::=
SELECT <select_list>
FROM ( <dml_statement_with_output_clause> )
[AS] table_alias [ ( column_alias [ ,...n ] ) ]
[ WHERE <search_condition> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
Sample Source Patterns ¶
Basic INSERT¶
SQL Server¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
Snowflake¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
INSERT with assing operator¶
SQL Server¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
Snowflake¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
INSERT with no INTO¶
SQL Server¶
INSERT exampleTable VALUES ('Hello', 23);
Snowflake¶
INSERT INTO exampleTable VALUES ('Hello', 23);
INSERT with common table expression¶
SQL Server¶
WITH ctevalues (textCol, numCol) AS (SELECT 'cte string', 155)
INSERT INTO exampleTable SELECT * FROM ctevalues;
Snowflake¶
INSERT INTO exampleTable
WITH ctevalues (
textCol,
numCol
) AS (SELECT 'cte string', 155)
SELECT
*
FROM
ctevalues AS ctevalues;
INSERT with Table DML Factor with MERGE as DML¶
This case is so specific where the INSERT statement has a SELECT query, and the FROM clause of the SELECT mentioned contains a MERGE DML statement. Looking for an equivalent in Snowflake, the next statements are created: a temporary table, the merge statement converted, and finally, the insert statement.
SQL Server¶
INSERT INTO T3
SELECT
col1,
col2
FROM (
MERGE T1 USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN
INSERT VALUES ( T2.col1, T2.col2 )
WHEN MATCHED THEN
UPDATE SET T1.col2 = t2.col2
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2
) AS MERGE_OUT
WHERE ACTION_OUT='UPDATE';
Snowflake¶
--** SSC-FDM-TS0026 - DELETE CASE IS NOT BEING CONSIDERED, PLEASE CHECK IF THE ORIGINAL MERGE PERFORMS IT **
CREATE OR REPLACE TEMPORARY TABLE MERGE_OUT AS
SELECT
CASE WHEN T1.$1 IS NULL THEN 'INSERT' ELSE 'UPDATE' END ACTION_OUT,
T2.col1,
T2.col2
FROM T2 LEFT JOIN T1 ON T1.col1 = T2.col1;
MERGE INTO T1
USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN INSERT VALUES (T2.col1, T2.col2)
WHEN MATCHED THEN UPDATE SET T1.col2 = t2.col2
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2 ;
INSERT INTO T3
SELECT col1, col2
FROM MERGE_OUT
WHERE ACTION_OUT ='UPDATE';
Warning
NOTE: As the pattern’s name suggests, it is ONLY for cases where the insert comes with a select…from which the body contains a MERGE statement.
Known Issues¶
1. Syntax elements that require special mappings:
[INTO]: This keyword is obligatory in Snowflake and should be added if not present.
[DEFAULT VALUES]: Inserts the default value in all columns specified in the insert. Should be transformed to VALUES (DEFAULT, DEFAULT, …), the amount of DEFAULTs added equals the number of columns the insert will modify. For now, there is a warning being added.
SQL Server
INSERT INTO exampleTable DEFAULT VALUES;
#### Snowflake
!!!RESOLVE EWI!!! /*** SSC-EWI-0073 - PENDING FUNCTIONAL EQUIVALENCE REVIEW FOR 'INSERT WITH DEFAULT VALUES' NODE ***/!!!
INSERT INTO exampleTable DEFAULT VALUES;
2. Syntax elements not supported or irrelevant:
[TOP (expression) [PERCENT]]: Indicates the amount or percent of rows that will be inserted. Not supported.
[rowset_function_limited]: It is either OPENQUERY() or OPENROWSET(), used to read data from remote servers. Not supported.
[WITH table_hint_limited]: These are used to get reading/writing locks on tables. Not relevant in Snowflake.
[<OUTPUT Clause>]: Specifies a table or result set in which the inserted rows will also be inserted. Not supported.
[execute_statement]: Can be used to run a query to get data from. Not supported.
[dml_table_source]: A temporary result set generated by the OUTPUT clause of another DML statement. Not supported.
3. The DELETE case is not being considered.
For the INSERT with Table DML Factor with MERGE as DML pattern, the DELETE case is not being considered in the solution, so if the source code merge statement has a DELETE case please consider that it might not work as expected.
Related EWIs¶
SSC-EWI-0073: Pending Functional Equivalence Review.
SSC-FDM-TS0026: DELETE case is not being considered.
Merge¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Syntax comparison¶
Snowflake SQL syntax:
MERGE
INTO <target_table>
USING <source>
ON <join_expr>
{ matchedClause | notMatchedClause } [ ... ]
Transact-SQL syntax:
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
Example¶
Given the following source code:
MERGE
INTO
targetTable WITH(KEEPIDENTITY, KEEPDEFAULTS, HOLDLOCK, IGNORE_CONSTRAINTS, IGNORE_TRIGGERS, NOLOCK, INDEX(value1, value2, value3)) as tableAlias
USING
tableSource AS tableAlias2
ON
mergeSetCondition > mergeSetCondition
WHEN MATCHED BY TARGET AND pi.Quantity - src.OrderQty >= 0
THEN UPDATE SET pi.Quantity = pi.Quantity - src.OrderQty
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list)
OPTION(RECOMPILE);
You can expect to get something like this:
MERGE INTO targetTable as tableAlias
USING tableSource AS tableAlias2
ON mergeSetCondition > mergeSetCondition
WHEN MATCHED AND pi.Quantity - src.OrderQty >= 0 THEN
UPDATE SET
pi.Quantity = pi.Quantity - src.OrderQty
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list);
Related EWIs¶
SSC-EWI-0021: Syntax not supported in Snowflake.
Select¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Description¶
Allows the selection of one or more rows or columns of one or more tables in SQL Server.
For more information regarding SQL Server Select, check here.
<SELECT statement> ::=
[ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ]
<query_expression>
[ ORDER BY <order_by_expression> ]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
Sample Source Patterns ¶
SELECT WITH COLUMN ALIASES¶
The following example demonstrates how to use column aliases in Snowflake. The first two columns, from the SQL Server code, are expected to be transformed from an assignment form into a normalized form using the AS keyword. The third and fourth columns are using valid Snowflake formats.
SQL Server
SELECT
MyCol1Alias = COL1,
MyCol2Alias = COL2,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM TABLE1;
Snowflake
SELECT
COL1 AS MyCol1Alias,
COL2 AS MyCol2Alias,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM
TABLE1;
SELECT TOP¶
The basic case of SQL Server Select Top is supported by Snowflake. However, three more cases exist that are not supported, you can check them in the Known Issues section.
SQL Server
SELECT TOP 1 * from ATable;
Snowflake
SELECT TOP 1
*
from
ATable;
SELECT INTO¶
The following example shows the SELECT INTO is transformed into a CREATE TABLE AS, this is because in Snowflake there is no equivalent for SELECT INTO and to create a table based on a query has to be with the CREATE TABLE AS.
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1;
Another case is when including set operators such as EXCEPT and INTERSECT. The transformation is basically the same as the previous one.
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1
EXCEPT
SELECT * FROM TABLE2
INTERSECT
SELECT * FROM TABLE3;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1
EXCEPT
SELECT
*
FROM
TABLE2
INTERSECT
SELECT
*
FROM
TABLE3;
Known Issues¶
SELECT TOP Aditional Arguments¶
Since PERCENT and WITH TIES keywords affect the result, and they are not supported by Snowflake, they will be commented out and added as an error.
SQL Server
SELECT TOP 1 PERCENT * from ATable;
SELECT TOP 1 WITH TIES * from ATable;
SELECT TOP 1 PERCENT WITH TIES * from ATable;
Snowflake
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT FOR¶
Since the FOR clause is not supported in Snowflake, it is commented out and added as an error during the transformation.
SQL Server
SELECT column1, column2 FROM my_table FOR XML PATH('');
Snowflake
SELECT
--** SSC-FDM-TS0016 - XML COLUMNS IN SNOWFLAKE MIGHT HAVE A DIFFERENT FORMAT **
FOR_XML_UDF(OBJECT_CONSTRUCT('column1', column1, 'column2', column2), '')
FROM
my_table;
SELECT OPTION¶
The OPTION clause is not supported by Snowflake. It will be commented out and added as a warning during the transformation.
Warning
Notice that the OPTION statement has been removed from transformation because it is not relevant or not needed in Snowflake.
SQL Server
SELECT column1, column2 FROM my_table OPTION (HASH GROUP, FAST 10);
Snowflake
SELECT
column1,
column2
FROM
my_table;
SELECT WITH¶
The WITH clause is not supported by Snowflake. It will be commented out and added as a warning during the transformation.
Warning
Notice that the WITH(NOLOCK, NOWAIT) statement has been removed from transformation because it is not relevant or not needed in Snowflake.
SQL Server
SELECT AValue from ATable WITH(NOLOCK, NOWAIT);
Snowflake
SELECT
AValue
from
ATable;
Related EWIs¶
SSC-EWI-0040: Statement Not Supported.
SSC-FDM-TS0016: XML columns in Snowflake might have a different format
Set Operators¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Set Operators in both TSQL and Snowflake present the same syntax and supported scenarios(EXCEPT, INTERSECT, UNION and UNION ALL), with the exception of the MINUS which is not supported in TSQL, resulting in the same code during conversion.
SELECT LastName, FirstName FROM employees
UNION ALL
SELECT FirstName, LastName FROM contractors;
SELECT ...
INTERSECT
SELECT ...
SELECT ...
EXCEPT
SELECT ...
Truncate¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Source code
TRUNCATE TABLE TABLE1;
Translated code
TRUNCATE TABLE TABLE1;
Related EWIs¶
No related EWIs.
Update¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Note
Some parts in the output code are omitted for clarity reasons.
Description¶
Changes existing data in a table or view in SQL Server. For more information regarding SQL Server Update, check here.
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
Sample Source Patterns ¶
Basic UPDATE¶
The conversion for a regular UPDATE statement is very straightforward. Since the basic UPDATE structure is supported by default in Snowflake, the outliers are the parts where you are going to see some differences, check them in the Known Issues section.
SQL Server¶
Update UpdateTest1
Set Col1 = 5;
Snowflake
Update UpdateTest1
Set
Col1 = 5;
Cartesian Products¶
SQL Server allows add circular references between the target table of the Update Statement and the FROM Clause/ In execution time, the database optimizer removes any cartesian product generated. Otherwise, Snowflake currently does not optimize this scenario, producing a cartesian product that can be checked in the Execution Plan.\
To resolve this, if there is a JOIN where one of their tables is the same as the update target, this reference is removed and added to the WHERE clause, and it is used to just filter the data and avoid making a set operation.
SQL Server¶
UPDATE [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY]
SET
BusinessEntityID = b.BusinessEntityID ,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY] AS a
RIGHT OUTER JOIN [HumanResources].[EmployeeDepartmentHistory] AS b
ON a.BusinessEntityID = b.BusinessEntityID and a.ShiftID = b.ShiftID;
Snowflake
UPDATE HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY a
SET
BusinessEntityID = b.BusinessEntityID,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM
HumanResources.EmployeeDepartmentHistory AS b
WHERE
HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.BusinessEntityID = b.BusinessEntityID(+)
AND HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.ShiftID = b.ShiftID(+);
Known Issues¶
OUTPUT clause¶
The OUTPUT clause is not supported by Snowflake.
SQL Server¶
Update UpdateTest2
Set Col1 = 5
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
Snowflake
Update UpdateTest2
Set
Col1 = 5
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
CTE¶
The WITH CTE clause is moved to the internal query in the update statement to be supported by Snowflake.
SQL Server¶
With ut as (select * from UpdateTest3)
Update x
Set Col1 = 5
from ut as x;
Snowflake
UPDATE UpdateTest3
Set
Col1 = 5
FROM
(
WITH ut as (select
*
from
UpdateTest3
)
SELECT
*
FROM
ut
) AS x;
TOP clause¶
The TOP clause is not supported by Snowflake.
SQL Server¶
Update TOP(10) UpdateTest4
Set Col1 = 5;
Snowflake
Update
-- !!!RESOLVE EWI!!! /*** SSC-EWI-0021 - TOP CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
-- TOP(10)
UpdateTest4
Set
Col1 = 5;
WITH TABLE HINT LIMITED¶
The Update WITH clause in not supported by Snowflake.
SQL Server¶
Update UpdateTest5 WITH(TABLOCK)
Set Col1 = 5;
Snowflake
Update UpdateTest5
Set
Col1 = 5;
Related EWIs¶
SSC-EWI-0021: Syntax not supported in Snowflake.
Alternative for UPDATE with JOIN¶
This is a work in progress and may change in the future.
Description
The pattern UPDATE FROM is used to update data based on data from other tables. This SQLServer documentation provides a simple sample.
Review the following SQL Server syntax from the documentation.
SQL Server Syntax
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: The table or view you are updating.SET: Specifies the columns and their new values. TheSETclause assigns a new value (or expression) to one or more columns.FROM: Used to specify one or more source tables (like a join). It helps define where the data comes from to perform the update.WHERE: Specifies which rows should be updated based on the condition(s). Without this clause, all rows in the table would be updated.OPTION (query_hint): Specifies hints for query optimization.
Snowflake syntax
The Snowflake syntax can also be reviewed in the Snowflake documentation.
Note
Snowflake does not support JOINs in UPDATE clause.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
[ WHERE <condition> ]
Required parameters
target_table:Specifies the table to update.col_name:Specifies the name of a column intarget_table. Do not include the table name. E.g.,UPDATE t1 SET t1.col = 1is invalid.value:Specifies the new value to set incol_name.
Optional parameters
FROM``additional_tables:Specifies one or more tables to use for selecting rows to update or for setting new values. Note that repeating the target table results in a self-join.WHERE``condition:The expression that specifies the rows in the target table to update. Default: No value (all rows of the target table are updated)
Translation Summary¶
| SQL Server JOIN type | Snowflake Best Alternative |
|---|---|
Single INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN + Agregate condition | Use subquery + IN Operation |
Single LEFT JOIN | Use subquery + IN Operation |
Multiple LEFT JOIN | Use Snowflake
|
Multiple RIGHT JOIN | Use Snowflake
|
| Single RIGHT JOIN | Use the table in the FROM clause and add filters in the WHERE clause as needed. |
Note-1: Simple JOIN may use the table in the FROM clause and add filters in the WHERE clause as needed.
Note-2: Other approaches may include (+) operand to define the JOINs.
Sample Source Patterns ¶
Setup data¶
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
);
CREATE OR REPLACE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
Data Insertion for samples
-- Insert Customer Data
INSERT INTO Customers (CustomerID, CustomerName) VALUES (1, 'John Doe');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (2, 'Jane Smith');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (3, 'Alice Johnson');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (4, 'Bob Lee');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (5, 'Charlie Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (6, 'David White');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (7, 'Eve Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (8, 'Grace Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (9, 'Hank Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (10, 'Ivy Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (11, 'Jack Grey');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (12, 'Kim Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (13, 'Leo Purple');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (14, 'Mona Pink');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (15, 'Nathan Orange');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (16, 'Olivia Cyan');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (17, 'Paul Violet');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (18, 'Quincy Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (19, 'Rita Silver');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (20, 'Sam Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (21, 'Tina Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (22, 'Ursula Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (23, 'Vince Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (24, 'Wendy Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (25, 'Xander White');
-- Insert Product Data
INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Laptop', 999.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Smartphone', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (3, 'Tablet', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (4, 'Headphones', 149.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (5, 'Monitor', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (6, 'Keyboard', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (7, 'Mouse', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (8, 'Camera', 599.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (9, 'Printer', 99.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (10, 'Speaker', 129.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (11, 'Charger', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (12, 'TV', 699.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (13, 'Smartwatch', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (14, 'Projector', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (15, 'Game Console', 399.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (16, 'Speaker System', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (17, 'Earphones', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (18, 'USB Drive', 15.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (19, 'External Hard Drive', 79.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (20, 'Router', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (21, 'Printer Ink', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (22, 'Flash Drive', 9.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (23, 'Gamepad', 34.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (24, 'Webcam', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (25, 'Docking Station', 129.99);
-- Insert Orders Data
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (1, 1, 1, 2, '2024-11-01');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (2, 2, 2, 1, '2024-11-02');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (3, 3, 3, 5, '2024-11-03');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (4, 4, 4, 3, '2024-11-04');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (5, NULL, 5, 7, '2024-11-05'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (6, 6, 6, 2, '2024-11-06');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (7, 7, NULL, 4, '2024-11-07'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (8, 8, 8, 1, '2024-11-08');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (9, 9, 9, 3, '2024-11-09');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (10, 10, 10, 2, '2024-11-10');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (11, 11, 11, 5, '2024-11-11');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (12, 12, 12, 2, '2024-11-12');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (13, NULL, 13, 8, '2024-11-13'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (14, 14, NULL, 4, '2024-11-14'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (15, 15, 15, 3, '2024-11-15');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (16, 16, 16, 2, '2024-11-16');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (17, 17, 17, 1, '2024-11-17');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (18, 18, 18, 4, '2024-11-18');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (19, 19, 19, 3, '2024-11-19');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (20, 20, 20, 6, '2024-11-20');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (21, 21, 21, 3, '2024-11-21');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (22, 22, 22, 5, '2024-11-22');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (23, 23, 23, 2, '2024-11-23');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (24, 24, 24, 4, '2024-11-24');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (25, 25, 25, 3, '2024-11-25');
Case 1: Single INNER JOIN Update¶
For INNER JOIN, if the table is used inside the FROM statements, it automatically turns into INNER JOIN. Notice that there are several approaches to support JOINs in UPDATE statements in Snowflake. This is one of the simplest patterns to ensure readability.
SQL Server¶
UPDATE Orders
SET Quantity = 10
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'John Doe';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
Quantity |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 10
FROM
Customers C
WHERE
C.CustomerName = 'John Doe'
AND O.CustomerID = C.CustomerID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
Quantity |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Other approaches:
MERGE INTO
MERGE INTO Orders O
USING Customers C
ON O.CustomerID = C.CustomerID
WHEN MATCHED AND C.CustomerName = 'John Doe' THEN
UPDATE SET O.Quantity = 10;
IN Operation
UPDATE Orders O
SET O.Quantity = 10
WHERE O.CustomerID IN
(SELECT CustomerID FROM Customers WHERE CustomerName = 'John Doe');
Case 2: Multiple INNER JOIN Update¶
SQL Server¶
UPDATE Orders
SET Quantity = 5
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerName = 'Alice Johnson' AND P.ProductName = 'Tablet';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
Quantity |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 5
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
Quantity |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Case 3: Multiple INNER JOIN Update with Aggregate Condition¶
SQL Server¶
UPDATE Orders
SET Quantity = 6
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
Quantity |
Price |
|---|---|---|---|
11 |
Jack Grey |
6 |
29.99 |
18 |
Quincy Brown |
6 |
15.99 |
20 |
Sam Green |
6 |
89.99 |
22 |
Ursula Red |
6 |
9.99 |
24 |
Wendy Black |
6 |
49.99 |
Snowflake¶
UPDATE Orders O
SET Quantity = 6
WHERE O.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND O.ProductID IN (SELECT ProductID FROM Products WHERE Price < 200);
-- Select changes
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
Quantity |
Price |
|---|---|---|---|
11 |
Jack Grey |
6 |
29.99 |
18 |
Quincy Brown |
6 |
15.99 |
20 |
Sam Green |
6 |
89.99 |
22 |
Ursula Red |
6 |
9.99 |
24 |
Wendy Black |
6 |
49.99 |
Case 4: Single LEFT JOIN Update¶
SQL Server¶
UPDATE Orders
SET Quantity = 13
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13;
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
Quantity |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Snowflake¶
UPDATE Orders
SET Quantity = 13
WHERE OrderID IN (
SELECT O.OrderID
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13
);
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
Quantity |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Note
This approach in Snowflake will not work because it does not update the necessary rows:
UPDATE Orders O SET O.Quantity = 13 FROM Customers C WHERE O.CustomerID = C.CustomerID AND C.CustomerID IS NULL AND O.ProductID = 13;
Case 5: Multiple LEFT JOIN and RIGHT JOIN Update¶
This is a more complex pattern. To translate multiple LEFT JOINs, please review the following pattern:
Note
LEFT JOIN and RIGHT JOIN will depend on the order in the FROM clause.
UPDATE [target_table_name]
SET [all_set_statements]
FROM [all_left_join_tables_separated_by_comma]
WHERE [all_clauses_into_the_ON_part]
SQL Server¶
UPDATE Orders
SET
Quantity = C.CustomerID
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
Quantity |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Snowflake¶
UPDATE Orders O
SET O.Quantity = C.CustomerID
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
Quantity |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Case 6: Mixed INNER JOIN and LEFT JOIN Update¶
SQL Server¶
UPDATE Orders
SET Quantity = 4
FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
Quantity |
|---|---|---|
null |
null |
4 |
Snowflake¶
UPDATE Orders O
SET Quantity = 4
WHERE O.ProductID IN (SELECT ProductID FROM Products WHERE ProductName = 'Monitor')
AND O.CustomerID IS NULL;
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
Quantity |
|---|---|---|
null |
null |
4 |
Case 7: Single RIGHT JOIN Update¶
SQL Server¶
UPDATE O
SET O.Quantity = 1000
FROM Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 1000
FROM Customers C
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Know Issues¶
Since
UPDATEin Snowflake does not allow the usage ofJOINsdirectly, there may be cases that do not match the patterns described.
UPDATE with LEFT and RIGHT JOIN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
Warning
Partially supported in Snowflake
Description ¶
The pattern UPDATE FROM is used to update data based on data from other tables. This SQLServer documentation provides a simple sample.
Review the following SQL Server syntax from the documentation.
SQL Server Syntax¶
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: The table or view you are updating.SET: Specifies the columns and their new values. TheSETclause assigns a new value (or expression) to one or more columns.FROM: Used to specify one or more source tables (like a join). It helps define where the data comes from to perform the update.WHERE: Specifies which rows should be updated based on the condition(s). Without this clause, all rows in the table would be updated.OPTION (query_hint): Specifies hints for query optimization.
Snowflake syntax¶
The Snowflake syntax can also be reviewed in the Snowflake documentation.
Note
Snowflake does not support JOINs in UPDATE clause.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
Required parameters
target_table:Specifies the table to update.col_name:Specifies the name of a column intarget_table. Do not include the table name. E.g.,UPDATE t1 SET t1.col = 1is invalid.value:Specifies the new value to set incol_name.
Optional parameters
FROM``additional_tables:Specifies one or more tables to use for selecting rows to update or for setting new values. Note that repeating the target table results in a self-join.WHERE``condition:The expression that specifies the rows in the target table to update. Default: No value (all rows of the target table are updated)
Translation Summary¶
As it is explained in the grammar description, there is not straight forward equivalent solution for JOINs inside the UPDATE cluase. For this reason, the approach to transform this statements is to add the operator (+) on the column that logically will add the required data into the table. This operator (+) is added to the cases on which the tables are referenced in the LEFT/RIGHT JOIN section.
Notice that there are other languages that use this operator (+) and the position of the operator may determine the type of join. In this specific case in Snowflake, the position will not determine the join type but the asociation with the logically needed tables and columns will.
Even when there are other alternative as MERGE c;ause or the usages of a CTE; these alternatives tend to turn difficult to read when there are complex queries, and get extensive.
Sample Source Patterns ¶
Setup data¶
CREATE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
);
CREATE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
);
CREATE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
);
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
CREATE OR REPLACE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
LEFT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM GenericTable1 T1
LEFT JOIN GenericTable2 T2 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4
LEFT JOIN GenericTable3 T3 ON
T3.Col1 = T2.Col5 AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM
GenericTable2 T2,
GenericTable3 T3
WHERE
T2.Col1(+) COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2(+) = T1.Col2
AND T2.Col3(+) = T1.Col3
AND T2.Col4(+) = T1.Col4
AND T3.Col1(+) = T2.Col5
AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
RIGHT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5
FROM GenericTable2 T2
RIGHT JOIN GenericTable1 T1 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4;
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5
FROM
GenericTable2 T2,
GenericTable1 T1
WHERE
T2.Col1 COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2 = T1.Col2(+)
AND T2.Col3 = T1.Col3(+)
AND T2.Col4 = T1.Col4(+);
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Known Issues¶
There may be patterns that cannot be translated due to differences in logic.
If your query pattern applies, review non-deterministic rows: “When a FROM clause contains a JOIN between tables (e.g.
t1andt2), a target row int1may join against (i.e. match) more than one row in tablet2. When this occurs, the target row is called a multi-joined row. When updating a multi-joined row, the ERROR_ON_NONDETERMINISTIC_UPDATE session parameter controls the outcome of the update” (Snowflake documentation).