Automating Snowpipe for Google Cloud Storage¶
This topic provides instructions for triggering Snowpipe data loads from external stages on Google Cloud Storage automatically using Google Cloud Pub/Sub messages for Google Cloud Storage (GCS) events.
Note that only OBJECT_FINALIZE events trigger Snowpipe to load files. Snowflake recommends that you only send supported events for Snowpipe to reduce costs, event noise, and latency.
Cloud platform support¶
Triggering automated Snowpipe data loads using GCS Pub/Sub event messages is supported by Snowflake accounts hosted on all supported cloud platforms.
Configuring secure access to Cloud Storage¶
Note
If you have already configured secure access to the GCS bucket that stores your data files, you can skip this section.
This section describes how to configure a Snowflake storage integration object to delegate authentication responsibility for cloud storage to a Snowflake identity and access management (IAM) entity.
This section describes how to use storage integrations to allow Snowflake to read data from and write to a Google Cloud Storage bucket referenced in an external (that is, Cloud Storage) stage. Integrations are named, first-class Snowflake objects that avoid the need for passing explicit cloud provider credentials such as secret keys or access tokens; instead, integration objects reference a Cloud Storage service account. An administrator in your organization grants the service account permissions in the Cloud Storage account.
Administrators can also restrict users to a specific set of Cloud Storage buckets (and optional paths) accessed by external stages that use the integration.
Note
- Completing the instructions in this section requires access to your Cloud Storage project as a project editor. If you are not a project editor, ask your Cloud Storage administrator to perform these tasks.
- Confirm that Snowflake supports the Google Cloud Storage region that your storage is hosted in. For more information, see Supported cloud regions.
The following diagram shows the integration flow for a Cloud Storage stage:
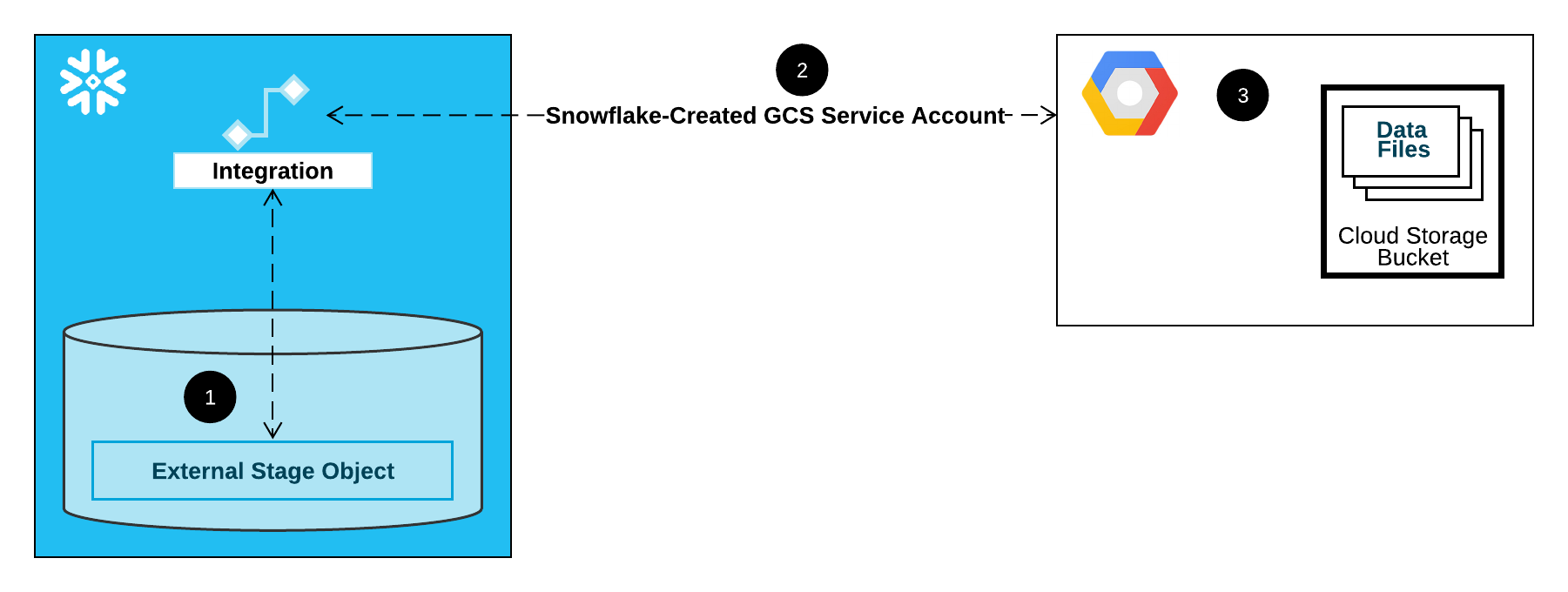
- An external (that is, Cloud Storage) stage references a storage integration object in its definition.
- Snowflake automatically associates the storage integration with a Cloud Storage service account created for your account. Snowflake creates a single service account that is referenced by all GCS storage integrations in your Snowflake account.
- A project editor for your Cloud Storage project grants permissions to the service account to access the bucket referenced in the stage definition. Note that many external stage objects can reference different buckets and paths and use the same integration for authentication.
When a user loads or unloads data from or to a stage, Snowflake verifies the permissions granted to the service account on the bucket before allowing or denying access.
In this Section:
Step 1: Create a Cloud Storage integration in Snowflake¶
Create an integration using the CREATE STORAGE INTEGRATION command. An integration is a Snowflake object that delegates authentication responsibility for external cloud storage to a Snowflake-generated entity (that is, a Cloud Storage service account). For accessing Cloud Storage buckets, Snowflake creates a service account that can be granted permissions to access the bucket(s) that store your data files.
A single storage integration can support multiple external (that is, GCS) stages. The URL in the stage definition must align with the GCS buckets (and optional paths) specified for the STORAGE_ALLOWED_LOCATIONS parameter.
Note
Only account administrators (users with the ACCOUNTADMIN role) or a role with the global CREATE INTEGRATION privilege can execute this SQL command.
Where:
integration_nameis the name of the new integration.bucketis the name of a Cloud Storage bucket that stores your data files (for example,mybucket). The required STORAGE_ALLOWED_LOCATIONS parameter and optional STORAGE_BLOCKED_LOCATIONS parameter restrict or block access to these buckets, respectively, when stages that reference this integration are created or modified.pathis an optional path that can be used to provide granular control over objects in the bucket.
The following example creates an integration that explicitly limits external stages that use the integration to reference either of two buckets and paths. In a later step, we will create an external stage that references one of these buckets and paths.
Additional external stages that also use this integration can reference the allowed buckets and paths:
Step 2: Retrieve the Cloud Storage service account for your Snowflake account¶
Execute the DESCRIBE INTEGRATION command to retrieve the ID for the Cloud Storage service account that was created automatically for your Snowflake account:
Where:
integration_nameis the name of the integration you created in Step 1: Create a Cloud Storage integration in Snowflake (in this topic).
For example:
The STORAGE_GCP_SERVICE_ACCOUNT property in the output shows the Cloud Storage service account created for your Snowflake account (that is, service-account-id@project1-123456.iam.gserviceaccount.com). We provision a single Cloud Storage service account for your entire Snowflake account. All Cloud Storage integrations use that service account.
Step 3: Grant the service account permissions to access bucket objects¶
The following step-by-step instructions describe how to configure IAM access permissions for Snowflake in your Google Cloud console so that you can use a Cloud Storage bucket to load and unload data:
Create a custom IAM role¶
Create a custom role that has the permissions required to access the bucket and get objects.
-
Sign in to the Google Cloud console as a project editor.
-
From the home dashboard, select IAM & Admin » Roles.
-
Select Create Role.
-
Enter a Title and optional Description for the custom role.
-
Select Add Permissions.
-
Filter the list of permissions, and add the following from the list:
Action(s) Required permissions Data loading only storage.buckets.getstorage.objects.getstorage.objects.list
Data loading with purge option, executing the REMOVE command on the stage storage.buckets.getstorage.objects.deletestorage.objects.getstorage.objects.list
Data loading and unloading storage.buckets.get(for calculating data transfer costs)storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
Data unloading only storage.buckets.getstorage.objects.createstorage.objects.deletestorage.objects.list
Using COPY FILES to copy files to an external stage You must have the following additional permissions:
storage.multipartUploads.abortstorage.multipartUploads.createstorage.multipartUploads.liststorage.multipartUploads.listParts
-
Select Add.
-
Select Create.
Assign the custom role to the Cloud Storage Service Account¶
- Sign in to the Google Cloud console as a project editor.
- From the home dashboard, select Cloud Storage » Buckets.
- Filter the list of buckets, and select the bucket that you specified when you created your storage integration.
- Select Permissions » View by principals, then select Grant access.
- Under Add principals, paste the name of the service account name that you retrieved from the DESC STORAGE INTEGRATION command output.
- Under Assign roles, select the custom IAM role that you created previously, then select Save.
Important
If your Google Cloud organization was created on or after May 3, 2024, Google Cloud enforces a domain restriction constraint in project organization policies. The default constraint lists your domain as the only allowed value.
To allow the Snowflake service account access to your storage, you must update the domain restriction.
Grant the Cloud Storage service account permissions on the Cloud Key Management Service cryptographic keys¶
Note
This step is required only if your GCS bucket is encrypted using a key stored in the Google Cloud Key Management Service (Cloud KMS).
- Sign in to the Google Cloud console as a project editor.
- From the home dashboard, search for and select Security » Key Management.
- Select the key ring that is assigned to your GCS bucket.
- Click SHOW INFO PANEL in the upper-right corner. The information panel for the key ring slides out.
- Click the ADD PRINCIPAL button.
- In the New principals field, search for the service account name from the DESCRIBE INTEGRATION output in Step 2: Retrieve the Cloud Storage service account for your Snowflake account (in this topic).
- From the Select a role dropdown, select the
Cloud KMS CrytoKey Encryptor/Decryptorrole. - Click the Save button. The service account name is added to the Cloud KMS CrytoKey Encryptor/Decryptor role dropdown in the information panel.
Note
You can use the SYSTEM$VALIDATE_STORAGE_INTEGRATION function to validate the configuration for your storage integration.
Configuring Automation Using GCS Pub/Sub¶
Prerequisites¶
The instructions in this topic assume the following items have been created and configured:
- GCP account:
- Pub/Sub topic that receives event messages from the GCS bucket. For more information, see Creating the Pub/Sub Topic (in this topic).
- Subscription that receives event messages from the Pub/Sub topic. For more information, see Creating the Pub/Sub Subscription (in this topic).
For instructions, see the Pub/Sub documentation.
- Snowflake:
- Target table in the Snowflake database where you want to load data.
Creating the Pub/Sub Topic¶
Create a Pub/Sub topic using Cloud Shell or Cloud SDK.
Execute the following command to create the topic and enable it to listen for activity in the specified GCS bucket:
Where:
topicis the name for the topic.bucket-nameis the name of your GCS bucket.
If the topic already exists, the command uses it; otherwise, the command creates a new topic.
For more information, see Using Pub/Sub notifications for Cloud Storage in the Pub/Sub documentation.
Creating the Pub/Sub Subscription¶
Create a subscription with pull delivery to the Pub/Sub topic using the Cloud Console, gcloud command-line tool, or the Cloud Pub/Sub API. For instructions, see Managing topics and subscriptions in the Pub/Sub documentation.
Note
- Only Pub/Sub subscriptions that use the default pull delivery are supported with Snowflake. Push delivery is not supported.
Retrieving the Pub/Sub Subscription ID¶
The Pub/Sub topic subscription ID is used in these instructions to allow Snowflake access to event messages.
- Log into the Google Cloud Platform Console as a project editor.
- From the home dashboard, choose Big Data » Pub/Sub » Subscriptions.
- Copy the ID in the Subscription ID column for the topic subscription.
Step 1: Create a Notification Integration in Snowflake¶
Create a notification integration using the CREATE NOTIFICATION INTEGRATION command.
The notification integration references your Pub/Sub subscription. Snowflake associates the notification integration with a GCS service account created for your account. Snowflake creates a single service account that is referenced by all GCS notification integrations in your Snowflake account.
Note
- Only account administrators (users with the ACCOUNTADMIN role) or a role with the global CREATE INTEGRATION privilege can execute this SQL command.
- The GCS service account for notification integrations is different from the service account created for storage integrations.
- A single notification integration supports a single Google Cloud Pub/Sub subscription. Referencing the same Pub/Sub subscription in multiple notification integrations could result in missing data in target tables because event notifications are split between notification integrations. Therefore, pipe creation is blocked if a pipe references the same Pub/Sub subscription as an existing pipe.
Where:
integration_nameis the name of the new integration.subscription_idis the subscription name you recorded in Retrieving the Pub/Sub Subscription ID.
For example:
Step 2: Grant Snowflake Access to the Pub/Sub Subscription¶
-
Execute the DESCRIBE INTEGRATION command to retrieve the Snowflake service account ID:
Where:
integration_nameis the name of the integration you created in Step 1: Create a Notification Integration in Snowflake.
For example:
-
Record the service account name in the GCP_PUBSUB_SERVICE_ACCOUNT column, which has the following format:
-
Log into the Google Cloud Platform Console as a project editor.
-
From the home dashboard, choose Big Data » Pub/Sub » Subscriptions.
-
Select the subscription to configure for access.
-
Click SHOW INFO PANEL in the upper-right corner. The information panel for the subscription slides out.
-
Click the ADD PRINCIPAL button.
-
In the New principals field, search for the service account name you recorded.
-
From the Select a role dropdown, select Pub/Sub Subscriber.
-
Click the Save button. The service account name is added to the Pub/Sub Subscriber role dropdown in the information panel.
-
Navigate to the Dashboard page in the Cloud Console, and select your project from the dropdown list.
-
Click the ADD PEOPLE TO THIS PROJECT button.
-
Add the service account name you recorded.
-
From the Select a role dropdown, select Monitoring Viewer.
-
Click the Save button. The service account name is added to the Monitoring Viewer role.
Step 3: Create a stage (if needed)¶
Create an external stage that references your GCS bucket using the CREATE STAGE command. Snowflake reads your staged data files into the external table metadata. Alternatively, you can use an existing external stage.
Note
- To configure secure access to the cloud storage location, see Configuring Secure Access to Cloud Storage (in this topic).
- To reference a storage integration in the CREATE STAGE statement, the role must have the USAGE privilege on the storage integration object.
The following example creates a stage named mystage in the active schema for the user session. The cloud storage URL includes the
path files. The stage references a storage integration named my_storage_int.
Step 4: Create a pipe with auto-ingest enabled¶
Create a pipe using the CREATE PIPE command. The pipe defines the COPY INTO <table> statement used by Snowpipe to load data from the ingestion queue into the target table.
For example, create a pipe in the snowpipe_db.public schema that loads data from files staged in an external (GCS) stage named mystage into a destination table named mytable:
The INTEGRATION parameter references the my_notification_int notification integration you created in Step 1: Create a Notification Integration in Snowflake. The integration name must be provided in all uppercase.
Important
Verify that the storage location reference in the COPY INTO <table> statement does not overlap with the reference in existing pipes
in the account. Otherwise, multiple pipes could load the same set of data files into the target tables. For example, this situation can
occur when multiple pipe definitions reference the same storage location with different levels of granularity, such as
<storage_location>/path1/ and <storage_location>/path1/path2/. In this example, if files are staged in
<storage_location>/path1/path2/, both pipes would load a copy of the files.
View the COPY INTO <table> statements in the definitions of all pipes in the account by executing SHOW PIPES or by querying either the PIPES view in Account Usage or the PIPES view in the Information Schema.
Snowpipe with auto-ingest is now configured!
When new data files are added to the GCS bucket, the event message informs Snowpipe to load them into the target table defined in the pipe.
Step 5: Load historical files¶
To load any backlog of data files that existed in the external stage before Pub/Sub messages were configured, execute an ALTER PIPE … REFRESH statement.
Step 6: Delete staged files¶
Delete the staged files after you successfully load the data and no longer require the files. For instructions, see Deleting staged files after Snowpipe loads the data.
SYSTEM$PIPE_
The SYSTEM$PIPE_STATUS function retrieves a JSON representation of the current status of a pipe.
For pipes with AUTO_INGEST set to TRUE, the function returns a JSON object containing the following name/value pairs (if applicable to the current pipe status):
For descriptions of the output values, see the reference topic for the SQL function.