Snowpark Migration Accelerator:パイプラインラボ - 評価¶
As with SnowConvert, we will run code through the SMA, evaluate the result, resolve any issues, and run it on the new platform. However, unlike SnowConvert, the SMA does NOT connect to any source platform, nor does it connect to Snowflake. It is a local application that can be run completely offline. But its power is in its assessment. Most of the heavy lifting on conversion has been done by building compatibility between the Spark API and the Snowpark API.
抽出およびコードの可用性¶
AdventureWorks ラボに使用するファイルは次のとおりです。
end_to_end_lab_source_code.zip
For the purpose of this lab, we will assume that the notebook and script file that we are converting are already accessible as files. In general, the SMA takes in files as an input and does not connect to any source platform. If the files are being orchestrated by a specific tool, you may need to export them. If you are using notebooks as part of databricks or EMR, you can export those as .ipynb files just as the jupyter notebook we are going to run through the SMA today.
This lab only has a few files, but it’s common in a large migration to have hundreds or thousands of files. Extract what you can and run those files through the SMA. The good thing about using a tool like this is that it can tell you what you might be missing.
Note that there is also a data file as well: ‘customer_update.csv’. This is a sample of the file being generated locally by the Point of Sale (POS) system that Adventure Works is currently using. While that system is also being updated, this Proof of Concept (POC) is focused on making the existing pipeline work with Snowpark instead of Spark.
Let’s take each of these files, and drop them into a single directory on our local machine:
It would be recommended to create a project directory. This can be called whatever you like, but as a suggestion for this lab, let’s go with spark_adw_lab. This means we would create a folder with the name spark_adw_lab, then create another folder in that directory called source_files (the path being something like /your/accessible/directory/spark_adw_lab/source_files). This isn’t required, but will help keep things organized. The SMA will scan any set of subdirectories as well, so you could add specific pipelines in a folder and notebooks in another.
Access¶
アクセス可能なディレクトリにソースファイルができたので、 SMA を実行します。
If you have not already downloaded it, the SMA is accessible from the Snowflake website. It is also accessible from the Migrations page in SnowSight in your Snowflake account:
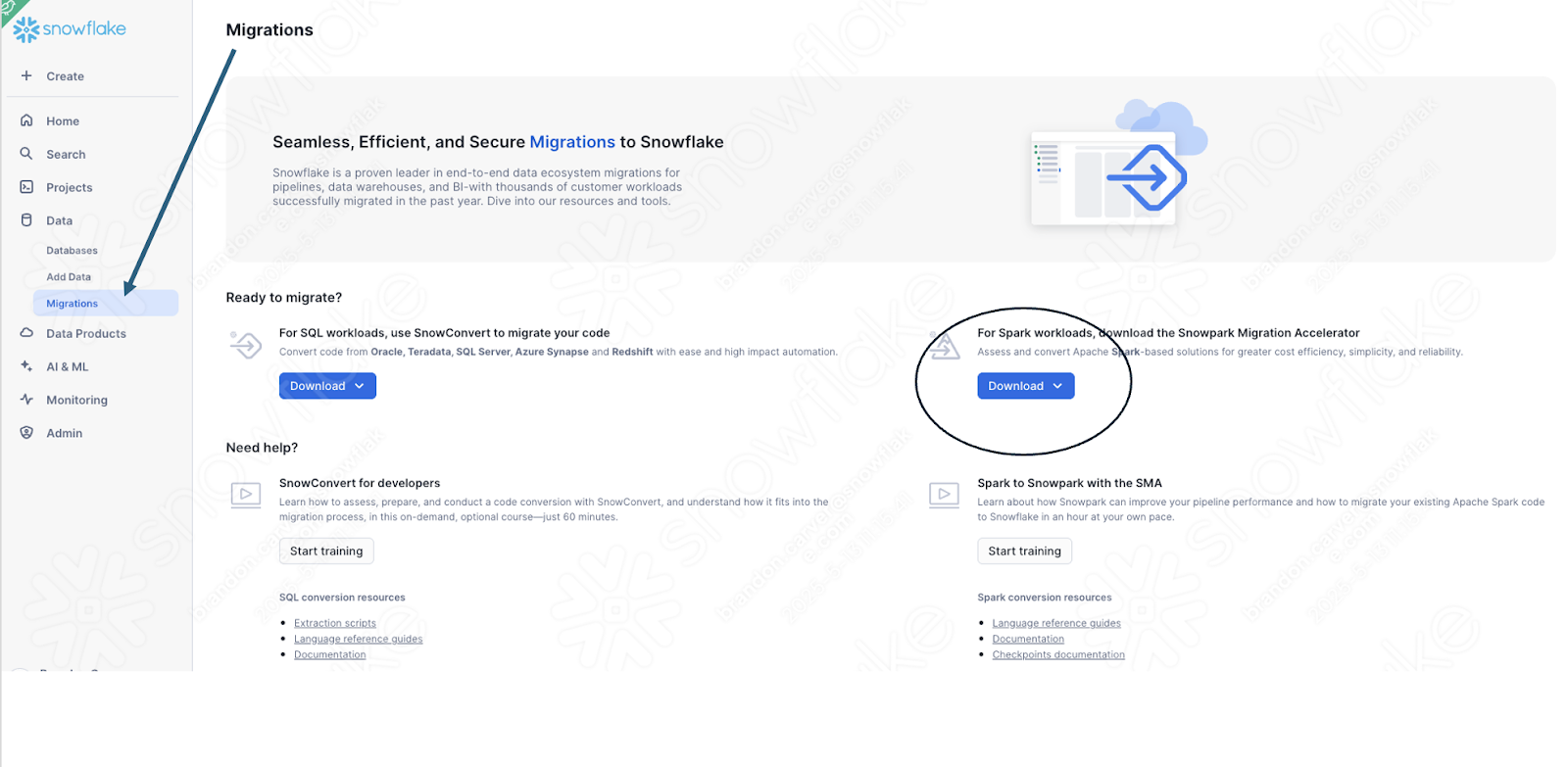
Once you download the tool, install it! There is more information on installing the SMA in the SMA documentation.
Snowpark Migration Acceleratorを使用する¶
Once you have installed the tool, open it! When you launch the SMA, it will look very similar to its partner tool, SnowConvert. Both of these tools are built on a similar concept where you input code files into the tool and it runs. As a reminder, we have seen that SnowConvert can take the DDL and data directly from the source and input it directly into Snowflake. The SMA does not do this. It only takes in code files as a source and outputs those files to something that is compatible with Snowflake. This is primarily because the tool does not know how a user will orchestrate their spark code, but also to make it more secure to use.
ツールを起動すると、新しいプロジェクトを作成するか、既存のプロジェクトを開くかを尋ねられます。
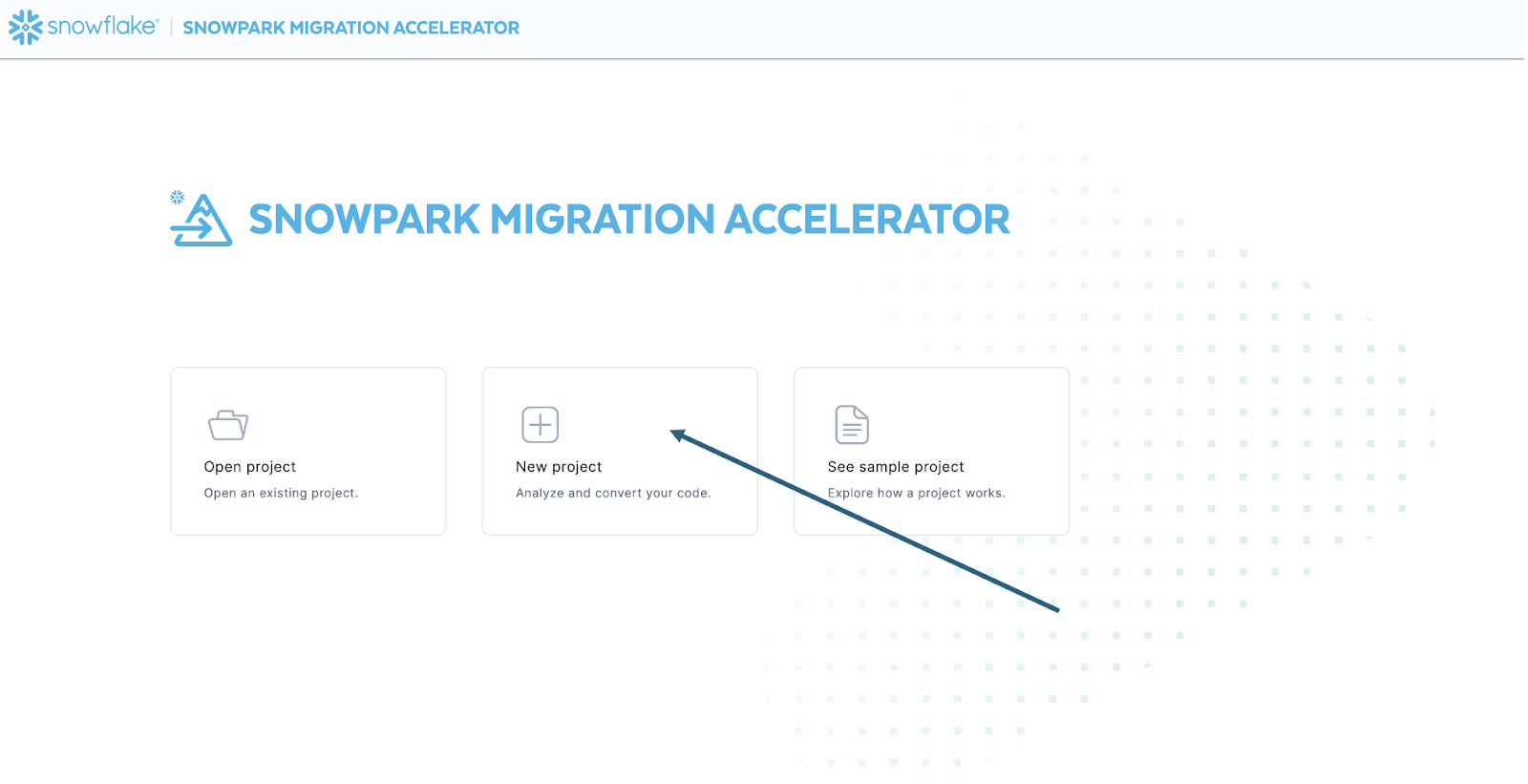
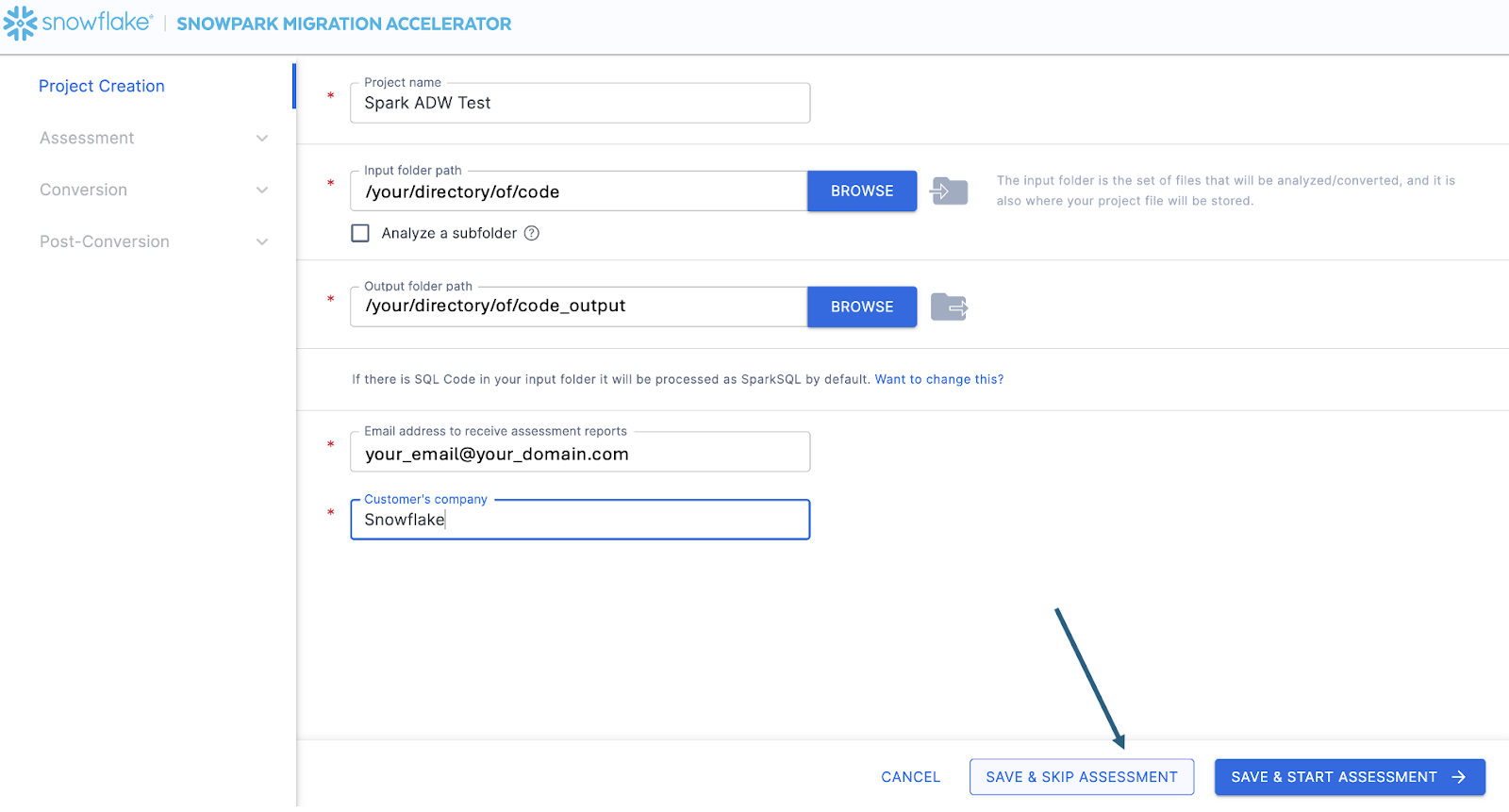
これにより、プロジェクト作成画面が表示されます。
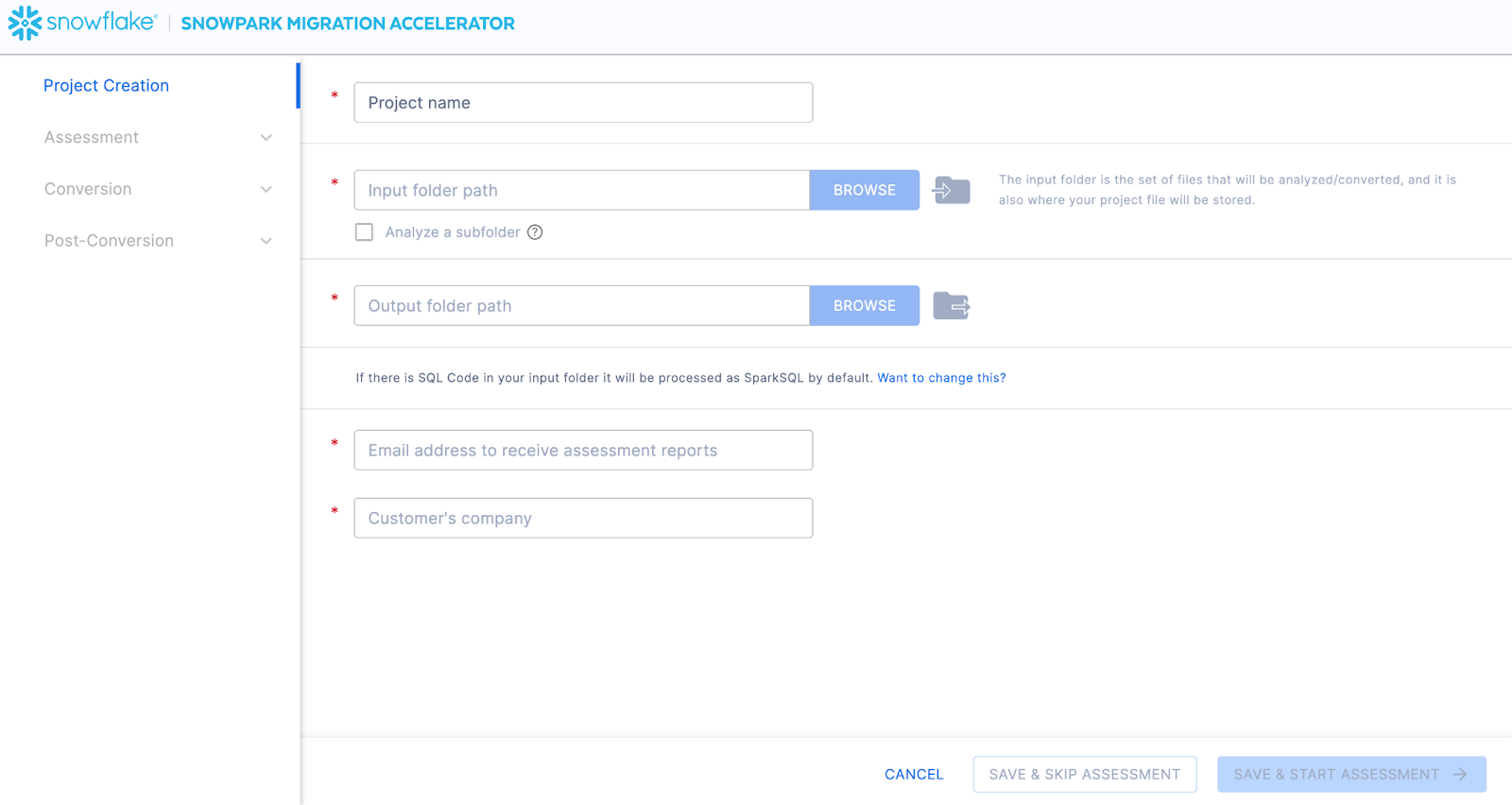
この画面では、プロジェクトの関連する詳細を入力します。すべてのフィールドが必須であることに注意してください。このプロジェクトでは、次のように入力できます。
プロジェクト名: Spark ADW ラボ
Email Address: your.name@your_domain.com
Company name: Your Organization
Input Folder Path: /your/accessible/directory/spark_adw_lab/source_files
Output Folder Path (the SMA will auto generate a directory for the output, but you can modify this): /your/accessible/directory/spark_adw_lab/source_files_output
このプロジェクト作成画面に関するいくつかのメモがあります。
メールと会社のフィールドは、進行中の可能性のあるプロジェクトを追跡するのに役立ちます。たとえば、大規模な SI の場合は、1人のユーザーが複数のメールアドレスを持ち、複数の組織を代表して SMA を運用している場合があります。この情報は、 SMA によって作成されたプロジェクトファイルに保存されます。
SQL の非表示フィールドがあります。SMA は SQL をスキャンおよび分析できますが、 SQL を変換することはできません。また、次の状況においてのみ SQL を識別できます。
.sqlファイルにある SQL
Jupyter Notebookの SQL セルにある SQL
SQL that is passed as a single string to a spark.sql statement.
この SQL 機能は、Snowflakeとの互換性のない SQL があるかを判断するのに役立ちますが、 SMA の主な使用法ではありません。Spark SQL および HiveQL のその他のサポートは近日公開予定です。
Once you’ve entered all of your project information, for this HoL, we are going to skip the assessment phase. (What… aren’t we building an assessment?) If you do not want to convert any code, running an assessment can be helpful as it will allow you to get the full set of reports generated by the SMA. You can then navigate through those or share them with others in your organization while not creating extra copies of the converted code. However, all of these same assessment reports are also generated during a conversion. So we will skip assessment mode for now and go to conversion.
On the Conversion settings page, select Skip Assessment, and then click Continue in the bottom right corner.
「保存」しているものはローカルプロジェクトファイルであることに注意してください。プロジェクト作成画面で入力したすべての情報は、上で指定したディレクトリで拡張子「.snowma」が付いたこのローカルテキストファイルに保存されます。
This will take you to the Conversion settings page. From here, you can choose Default Settings to proceed with conversion, or select Customize settings to review and adjust advanced options.

このハンズオンラボの出力を簡素化する設定が1つあります。それは、pandasデータフレームをSnowpark API に変換しようとする処理を無効にすることです。
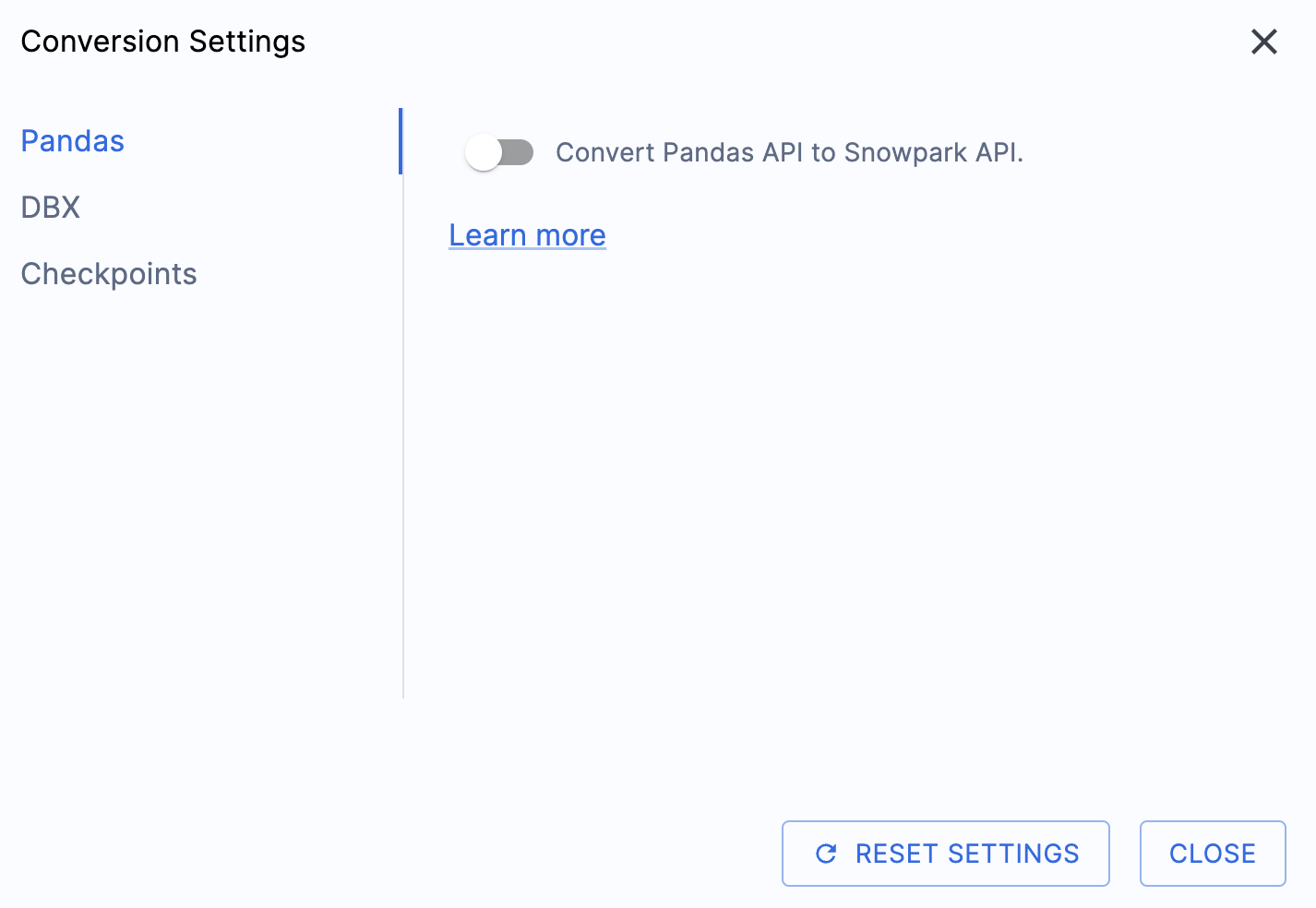
この1つの設定は現在更新されているため、このオプションの選択を解除しないと、多くの追加警告が表示されます。pandasデータフレームのほとんどは、pandasのmodin実装の一部として使用できるので、今のところ、単純なインポート呼び出しの変更で十分でしょう。この問題に関する続報は、2025年6月末までにお知らせします。他の設定を確認することもできますが、そのまま残します。出力されたコードが互換性のあるテストライブラリとして、Snowpark Checkpointsというものが存在することに注意することが重要です。これに関連する設定がありますが、このラボでは変更しません。
Select "Save settings" to save and close your settings.
To start the conversion, click Continue in the bottom right corner of the application.
The next screen will show the progress of the conversion:
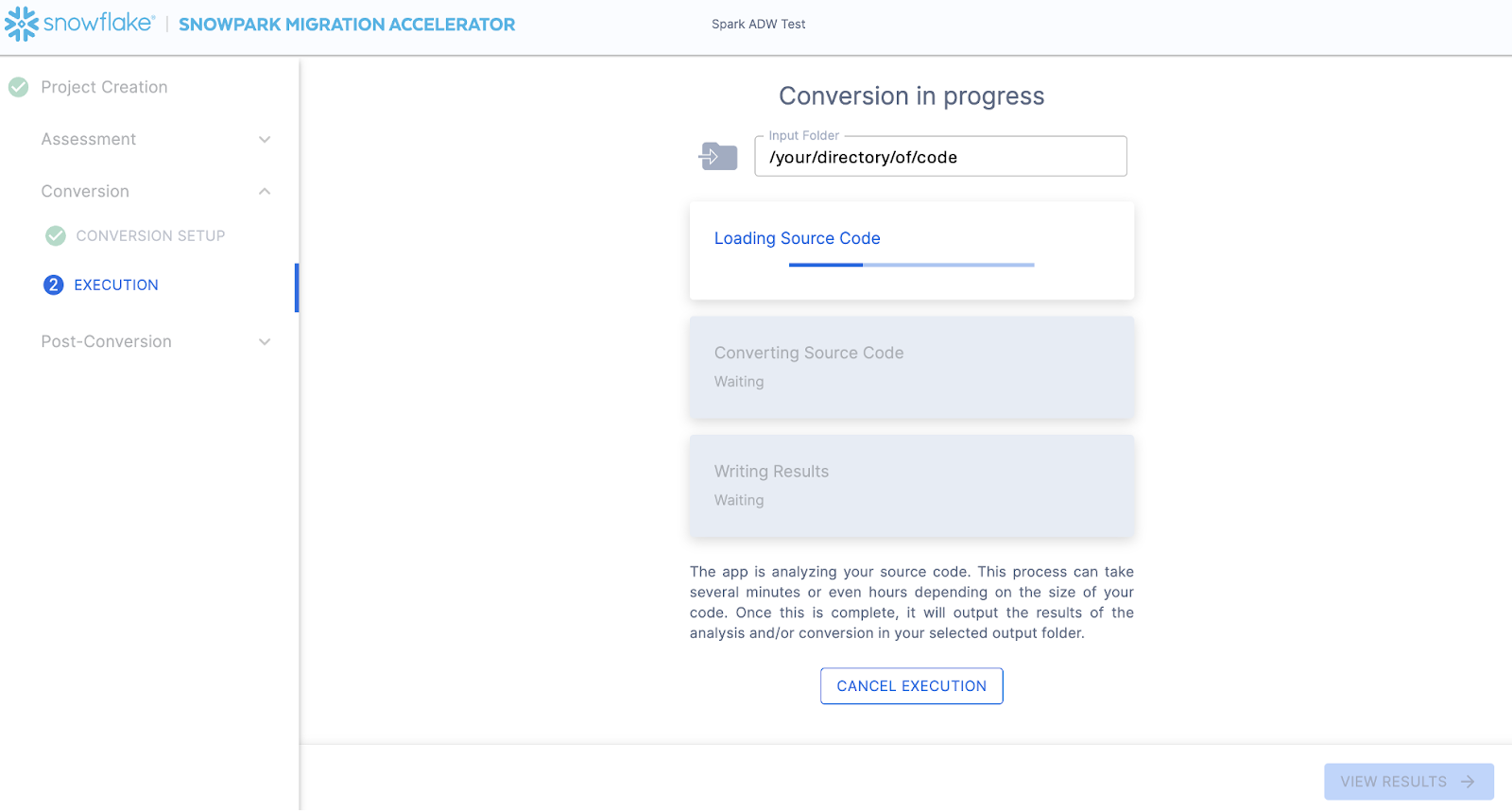
Like SnowConvert, the SMA is building a semantic model of the entire codebase in the input directory. It is building relationships between code elements, sql objects, and other referenced artifacts, and creating the closest output it can to a functional equivalent for Snowflake. This primarily means converting references from the Spark API to the Snowpark API. The SMA’s engineering team is a part of the Snowpark engineering team, so most transformations that take place have been built into the Snowpark API, so the changes may seem minor. But the wealth of assessment information that is generated by the SMA allows a migration project to really get moving forward. An in-depth look at all of the generated assessment information will have to take place elsewhere because the SMA has likely finished this conversion in the time it took to read this paragraph.
When the SMA has finished, the results page will show the… results.
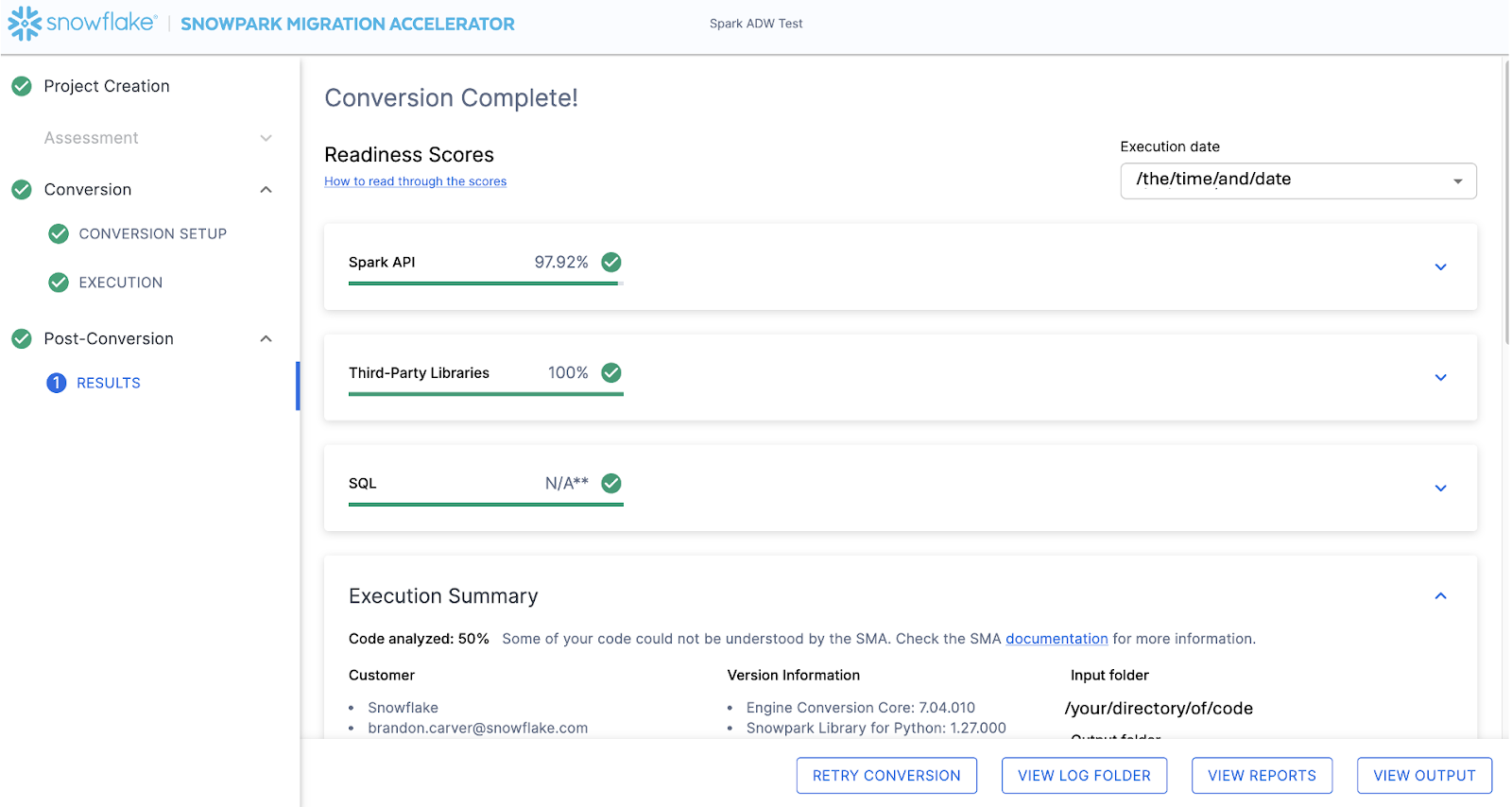
結果ページには、Snowflake用にこのコードベースがどの程度「準備できている」かについて、非常に簡素化されたメトリックである「レディネススコア」があります。次に結果を確認しますが、Snowpark Migration Acceleratorの実行は簡単な部分であることに注意してください。これはあくまで「アクセラレーター」であることにご留意ください。万能薬でも、完全に自動化されたツールでもありません。あるデータソースに接続し、別のデータソースに出力するパイプラインは、このツールでは完全に移行されないため、 SnowConvert が実行するような単純な SQL から SQL への DDL の移行よりも常に多くの注意が必要になります。ただし、Snowflakeはこれを可能な限りシンプルにするよう継続的に取り組んでいます。
出力の解釈¶
The SMA, even more so than SnowConvert, generates a large amount of assessment information. It can be difficult to parse through the results. There are many different directions you could go depending on what you want to achieve.
Note that this is an extremely simple scenario, so some of the steps we are going to take will look like overkill. (I mean, do we really need to analyze the dependencies present in this project when there are only two files and we could just… look?) The goal is to still walk through what we normally recommend even in this small POC. But let’s be clear… that the scope is clear, and there are only two files. We just need both of them to work as they do in the source.
レディネススコア¶
With that in mind, let’s take a look at the first part of the output that you will see in the application: the readiness scores. There will be multiple readiness scores and you can expand on each one of them to better understand what is captured by that readiness score.
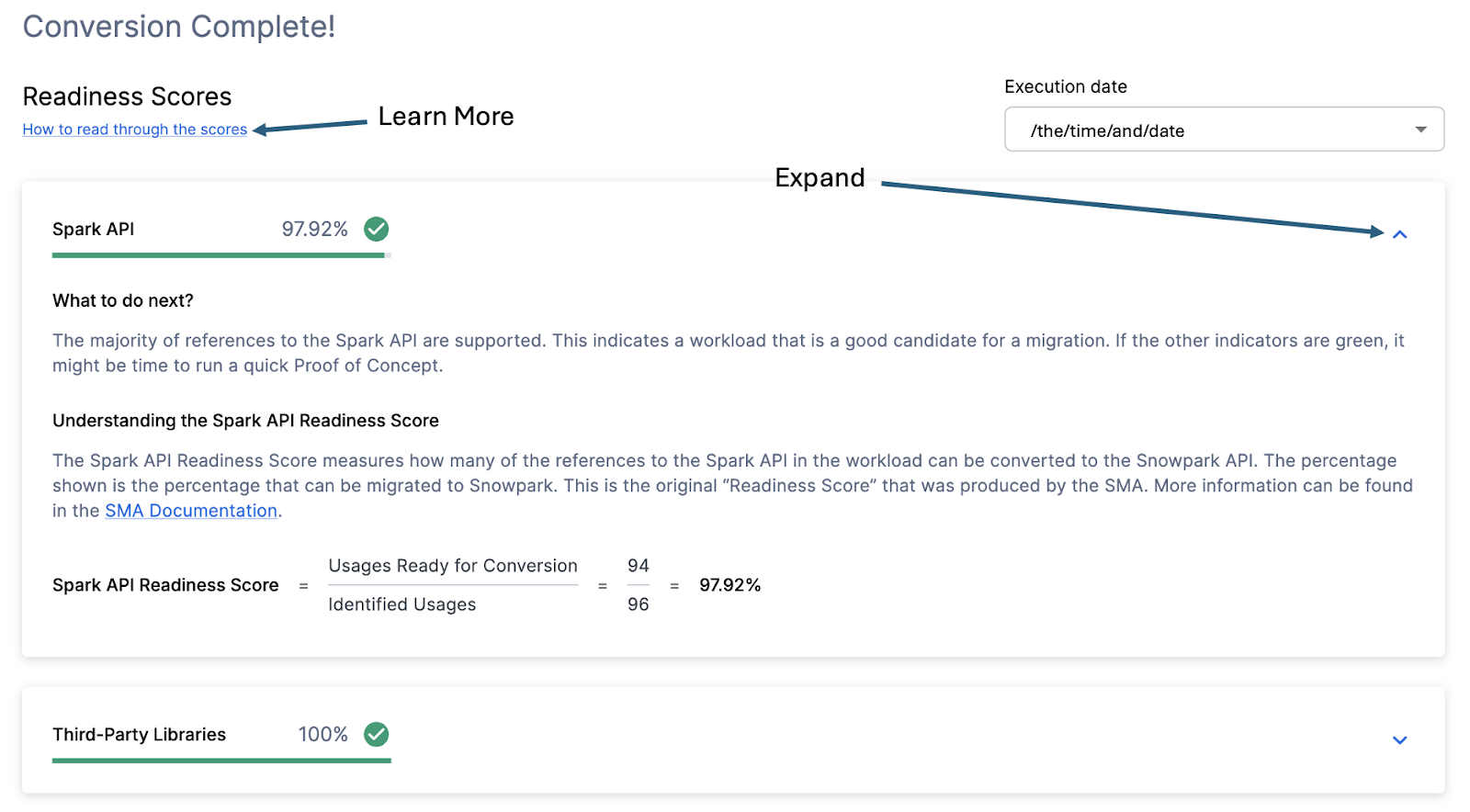
Each readiness score is a very basic calculation of the count of functions or elements in an API that are supported in Snowpark/Snowflake divided by the count of all functions or elements related to that API for this execution. The calculation showing you how the score is calculated is shown when you expand the window. You can also learn more about how to interpret the readiness scores by selecting “How to read through the scores” near the top left corner of this window.
This execution has a Snowpark API Readiness Score of 96.02%. (Please note that yours may be different! These tools are updated on a biweekly basis and there may be a change as compatibility between the two platforms is ever evolving.) This means that 96.02% of the references to the Spark API that the tool identified are supported in Snowflake. “Supported” in this case means that there could be a similar function that already exists or that the SMA has created a functionally equivalent output. The higher this score is, the more likely this code can quickly run in Snowflake.
(Note that this 96.02% of references are either supported directly by the Snowpark API or they are converted by the SMA. Most of them are likely supported directly, but you can find out exactly what was converted and what was passed through by reviewing the SparkUsagesInventory.csv report in the output Reports folder generated by the SMA. We will not walk through that in this lab as we will see what is NOT supported in the Issues.csv file, but you can use this information for reference.)
There are other readiness scores and you may see more than what is shown in the lab as the readiness scores do change over time. This lab won’t walk through each of them, but note that a low score will always be worth investigating.
コード分析済み¶
各レディネススコアのすぐ下に、処理できなかったコードがあったかどうかを示す小さなインジケーターが表示されます。
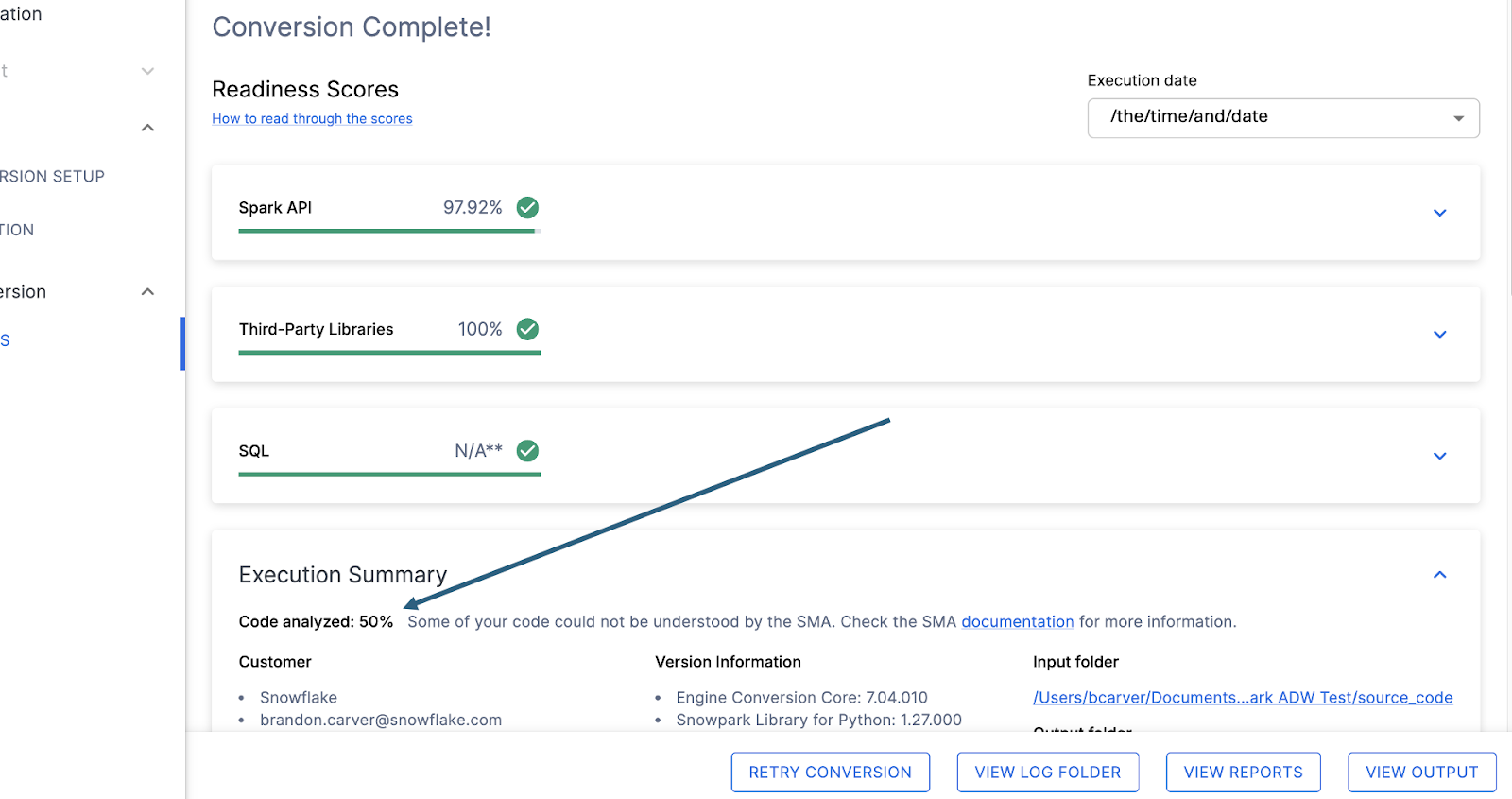
この数値は、完全に解析された ファイルの割合 を表します。この数が100%未満の場合、 SMA が解析または処理できなかったコードが一部存在することになります。問題解決のためにまず最初に確認すべき箇所はここです。100%未満の場合は、問題の概要を見て解析エラーが発生した場所を確認してください。これは、 SMA の出力を介して作業するときに最初に確認すべき箇所です。なぜなら、大量のコードをスキャンできなかった場合にツールを再度実行することが理にかなっている唯一の場所であるためです。